
熬过了40+危机的程序员,向AI开战 原创
写代码的人,被代码替代……

谷歌裁掉一万人
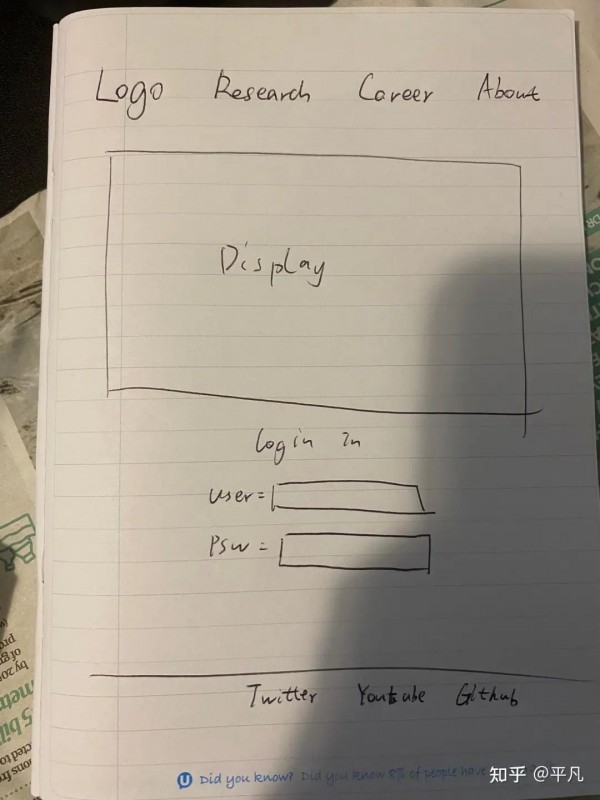
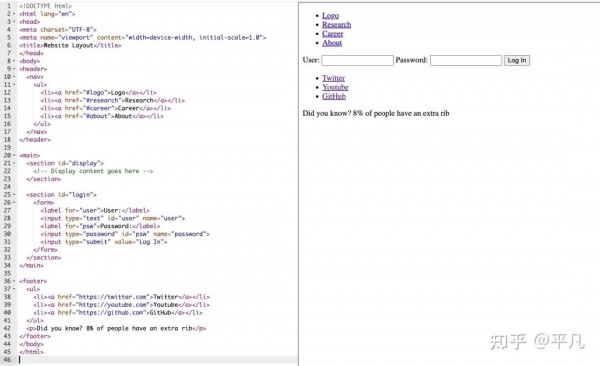
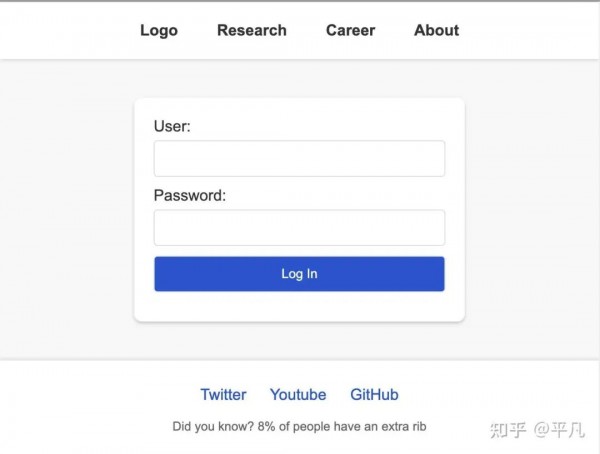
写代码的人,被代码代替
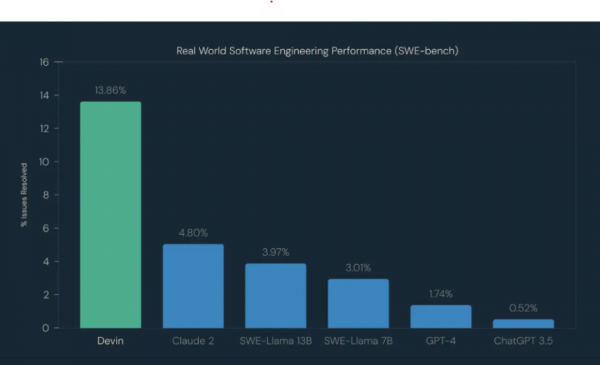
人类与AI的博弈,还在继续
来源:至顶网码客人生频道
好文章,需要你的鼓励



德国图宾根大学团队让2D材质预测瞬间“立体化“:MatSpray技术重新定义3D物体重光照
德国图宾根大学研究团队开发了MatSpray技术,能将2D照片中的材质信息准确转换为3D模型的物理属性。该技术结合了2D扩散模型的材质识别能力和3D高斯重建技术,通过创新的神经融合器解决多视角预测不一致问题,实现了高质量的材质重建和真实的重光照效果,处理速度比现有方法提升3.5倍。

2025-12-25
至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
真相只有一个:在AI与创意的交汇点上,HP Z2 Mini G1a确实是一台值得推荐的灵感引擎。

纽约大学发明“大脑翻译器“:让机器人读懂人类思维,精准操控语言AI
纽约大学研究团队开发出革命性"大脑翻译器"技术,首次实现用人类大脑活动模式精确控制AI语言行为。通过MEG脑磁图技术构建大脑语言地图,提取20个关键坐标轴,训练轻量级适配器让AI按人脑思维方式工作。实验证明该方法不仅能精确引导AI生成特定类型文本,还显著提升语言自然度,在多个AI模型中表现出良好通用性,为人机交互和AI可控性研究开辟全新路径。
2024
10/24
10:33
分享
点赞

最新文章
EcoStruxure(TM) Building GPT楼宇智能运维专家
拥抱AI,HPE Networking以“自动驾驶的网络”引领智能网络新时代
至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
冷板式液冷CDU系统
我们希望AI有多智能?世界模型可能比我们更懂世界
首席信息官角色将在2026年扩展的四种方式
Waymo正在测试Gemini在无人驾驶出租车中的车载AI助手功能
数据中心从幕后走向台前的转折之年
意大利要求Meta暂停禁止竞争对手AI聊天机器人使用WhatsApp的政策
让老旧Windows和macOS系统延续生命力
微软计划到2030年用Rust语言替换所有C和C++代码
2026年创客工具迎来重大升级,这些新技术值得期待
相关文章

邮件订阅