
强化学习存在推理效率问题,阿里千问团队发明推理二八法则,解决AI选择困难症 原创
还记得电影《潘神的迷宫》中,在残酷现实与奇诡幻境间穿梭的奥菲利娅吗?
她必须在一座神秘的迷宫中完成潘神交付的三个艰难考验,每一个选择都像是在幽暗森林中辨认正确的岔路,稍有不慎便可能迷失方向,甚至付出沉重的代价。
奥菲利娅的旅程,充满了未知、抉择与对关键路径的依赖。

AI在解决复杂问题,比如解开一道棘手的数学题时,模型内部的思考过程,在某种程度上也像是在探索一座布满岔路的潘神迷宫。
AI的思考过程并非简单地沿着一条预设的直线奔向答案,而是在无数可能的思维路径中不断做出选择。那么,它是如何在这座错综复杂的迷宫中找到正确出口的呢?它是依赖于对每一条小径都进行地毯式搜索,还是也像奥菲利娅一样,能够敏锐地识别出那些决定成败的关键岔路口?
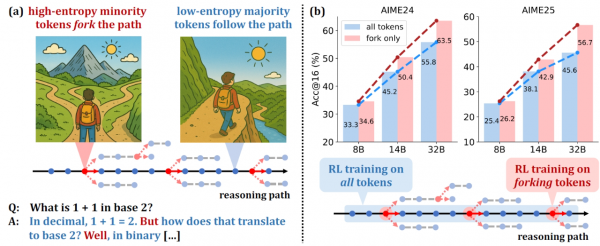
2025年6月2日,阿里巴巴Qwen团队揭示了AI在这座思维迷宫中导航的秘密,并发布论文《超越二八法则:高熵少数词元驱动大语言模型推理的有效强化学习》。
这项研究发现,AI在它的思考旅程中,大部分时候可能只是沿着较为平坦、明确的道路前进,也就是低不确定性的思考步骤。然而,在某些至关重要的岔路口,或者说高不确定性的决策点,AI会展现出非凡的判断力。
这些少数的岔路口,正是研究者们关注的焦点,他们将其称为高熵词元(high-entropy tokens),也就是那些让AI感到选择困难,但又必须做出关键抉择的词语或符号。意外的是,如果训练AI时,我们引导它重点关注这些大约占思考过程20%的岔路口词元,AI的推理能力不仅不会受损,反而可能比全面关注所有步骤时表现得更加出色,尤其是在那些更大型、更复杂的AI模型上!这仿佛是说,AI在自己的潘神迷宫中,学会了通过聚焦少数关键路径点,更高效地找到通往智慧的出口。
AI思考的岔路口在哪里?解密词元熵的秘密
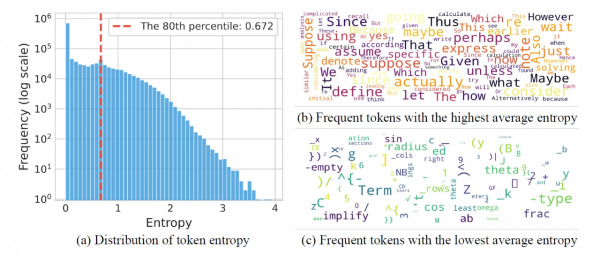
首先,让我们聊聊AI在思考时,是如何一步步吐出答案的。这个过程,在学术上被称为思维链(CoT)。就像我们解数学题时,会在草稿纸上列出详细的步骤一样,AI也会生成一步步的推理过程。研究者们发现,在AI生成的这些思维链中,并不是每个词元(token)都具有相同的重要性。
他们引入了一个叫做词元熵(token entropy)的概念。你可以把熵理解为不确定性或信息量。当AI对于下一个要生成的词元非常确定时,比如在写一句很常见的话,或者一个数学公式的固定部分,这时生成的词元就是低熵的,就像是沿着一条笔直的大路前进,毫不费力。
但当AI面临一个关键的决策点,比如需要选择下一步的推理方向,或者引入一个新的条件时,它对下一个词元的选择就会有很多可能性,这时生成的词元就是高熵的。这就像走到了一个复杂的岔路口,需要停下来思考往哪里走。
通过对大量AI生成的推理文本进行分析,研究者们发现了一个有意思的现象:在AI的思考过程中,绝大多数词元都是低熵的,它们主要负责完成句子结构、补充细节,就像是铺路石,让整个推理过程显得流畅自然。而只有一小部分词元是高熵的,这些高熵词元往往扮演着导航员的角色,它们是逻辑转折点,是决定推理方向的关键岔路口(研究者们称之为分叉词元,forking tokens)。比如,在数学推导中,“假设”、“因为”、“所以”、“然而”这类词,或者在选择解题策略的开端,往往就是这些高熵的分叉词元。
为了验证这个想法,研究团队做了一个巧妙的实验。他们人为地调整了AI在生成这些分叉词元时的不确定性(通过调整温度参数)。结果发现,如果适度增加这些关键岔路口词元的不确定性,让AI在这些点上更有探索欲,AI的解题表现反而会提升。相反,如果强行降低这些词元的不确定性,让AI在关键路口不敢尝试,那么它的表现就会变差。这进一步证明了这些少数的高熵分叉词元对于AI推理的重要性,它们就像是推理路径上的灯塔,指引着AI走向正确的答案。
AI如何学习走好这些岔路口?强化学习的奥秘
了解了岔路口词元的重要性后,下一个问题是,AI是如何学会更好地在这些关键点上做决策的呢?这里就要提到叫“带可验证奖励的强化学习”(Reinforcement Learning with Verifiable Rewards, RLVR)的训练方法。简单来说,这种方法就像是给AI请了一位严格的考官。AI每解完一道题,考官就会根据答案是否正确来给出奖励或惩罚。通过不断地试错和获取反馈,AI就能逐渐学会如何做出更优的推理。
研究者们进一步观察了在使用RLVR方法训练AI的过程中,词元熵是如何变化的。他们发现,即使用了强化学习,AI大脑中固有的哪些词元是岔路口,哪些词元是寻常路的模式,并不会发生翻天覆地的改变。也就是说,AI在学习过程中,很大程度上还是会遵循它最初对路况的判断。强化学习的主要作用,更像是对那些本身就很重要的岔路口词元进行重点打磨,让AI在这些关键点上的决策更加精准和有效。而对于那些普通的低熵词元,它们的变化则相对较小,就像是路面被稍稍修缮了一下,但基本走向不变。这就好比一位经验丰富的向导在学习新路线时,他会重点关注那些容易迷路的复杂岔路,而不是在平坦大道上花费过多精力。
惊人的发现:少即是多的AI训练法
基于以上发现,研究团队提出了一个大胆的想法:既然这些少数的高熵分叉词元如此重要,那么在训练AI时,我们能不能只关注它们,而忽略掉大部分低熵的跟随词元呢?就像教学生解题,不是让他把每个字都背下来,而是让他重点掌握解题思路和关键步骤。
于是,他们设计了一种新的训练策略:在强化学习过程中,只对那些被识别为高熵的20%岔路词元的决策进行调整和优化,而对其余80%的寻常路词元则放任不管。
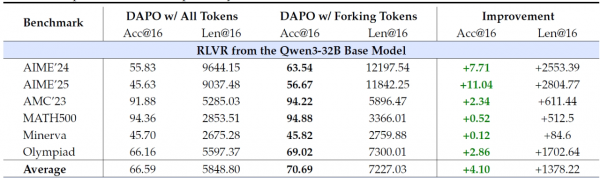
实验结果很好,以Qwen3-8B这个模型为例,采用这种只关注20%的训练方法,其推理表现与训练所有词元的传统方法相当。而在更强大的Qwen3-14B和Qwen3-32B模型上,这种少即是多的方法甚至取得了显著的超越!例如,在Qwen3-32B模型上,针对AIME'25(一项数学竞赛测试)的准确率提升了高达11.04个百分点,AIME'24的准确率也提升了7.71个百分点。这充分说明,AI推理能力的提升,主要来自于对那些决定推理方向的关键岔路口词元的优化。
相反,如果只训练那80%的低熵寻常路词元,AI的推理能力则会大幅下降。这就像只让学生练习写字,而不教他们思考方法,成绩自然不会好。这些结果有力地证明了,高效率的AI强化学习,关键在于抓住那些少数但至关重要的高熵分叉词元。这种发现甚至超越了我们常说的二八法则,因为在这里,仅仅20%的努力(只训练20%的词元)就带来了100%甚至超过100%的回报!
研究者还发现,这种只挑重点训练的方法,其优势会随着AI模型规模的增大而更加明显。也就是说,对于那些脑容量更大的AI,让它们专注于岔路口的思考,效果会更好。这可能是因为大模型有更强的能力去理解和利用这些关键决策点带来的灵活性和探索空间。
为什么抓住少数反而更有效?探索与稳定的平衡
为什么只训练少数高熵词元就能取得如此好的效果呢?研究者们认为,这可能与强化学习中的探索(exploration)和利用(exploitation)之间的平衡有关。
想象一下AI在解题,它既需要利用已有的知识(利用),也需要尝试新的思路(探索)。高熵的岔路口词元天然就代表着探索的可能性,因为它们对应着模型不太确定的多种选择。当我们只关注这些高熵词元进行训练时,实际上是在鼓励模型在这些关键的决策点上进行更有效的探索。
研究团队通过实验观察到,保留大约20%最高熵的词元进行训练,似乎能在探索和训练稳定性之间达到一个最佳的平衡点。如果保留的比例太少(比如10%),可能会漏掉一些有用的岔路口,导致探索不足。如果保留的比例太多(比如50%或100%,即包含了许多低熵词元),则可能会因为过多地关注那些寻常路,反而限制了在真正关键点上的探索效率,使得整体的探索信号被稀释了。就好比寻宝,我们应该把精力集中在那些最有可能藏有宝藏的地点,而不是在每一寸土地上都平均用力。
有趣的是,当只训练那80%的低熵词元时,模型的整体熵值(不确定性)显著降低,这表明模型几乎放弃了探索,这也是其性能大幅下降的原因。因此,通过精确地聚焦于高熵的少数派词元,AI似乎能更有效地进行探索,从而找到通往正确答案的更优路径。
这对我们意味着什么?AI训练的新启示
这项研究不仅仅是推理训练技术上的突破,它还为我们理解和训练AI提供了新的视角。
首先,它或许能解释为什么强化学习训练出的模型往往比监督学习(SFT,即直接喂给模型标准答案让它模仿)训练出的模型具有更好的泛化能力(即在新问题上的表现更好)。研究者推测,强化学习通过关注和调整这些高熵的岔路口词元,保留了AI在推理路径上的灵活性和探索性。而监督学习则倾向于让模型死记硬背标准答案,可能会压低这些关键岔路口的熵,使得推理路径变得僵化,难以适应新的、未见过的问题。
其次,这项研究也揭示了语言模型思考与传统强化学习任务(比如下棋、玩游戏)的一个重要区别。传统的强化学习任务中,每一步行动的不确定性可能都差不多。但语言模型在生成思考链时,由于它预先学习了大量的语言知识,并且需要生成流畅易懂的文本,所以大部分词元都是低熵的、高度确定的,只有少数词元是高熵的、需要探索的。这也解释了为什么AI的熵模式在训练后依然能保持相对稳定。
此外,研究还对AI训练中一种常用的技巧——熵奖励(entropy bonus)提出了新的看法。熵奖励通常被用来鼓励AI进行更多的探索。但如果对所有词元都施加熵奖励,可能会无差别地提升那些本应保持低熵的寻常路词元的熵,反而可能干扰正常的语言生成,导致性能下降。论文中提到的clip-higher机制,则能更精准地作用于那些高熵的岔路口词元,鼓励它们进行探索,同时不过多影响低熵词元,这或许是一种更适合语言模型推理任务的探索增强方法。
研究团队还测试了这种只关注少数高熵词元的训练方法在不同类型任务上的表现。他们发现,即使训练数据主要是数学题,用这种方法训练出来的模型,在代码生成这类跨界任务上,依然能比传统方法表现更好。这暗示着高熵词元可能与AI的通用推理和泛化能力紧密相关。甚至,通过延长模型允许生成的思考步骤长度,这种方法的潜力还能得到进一步的释放,取得更好的成绩。
当然,研究者们也坦诚地指出了当前工作的一些局限性,比如实验主要集中在Qwen系列模型上,未来需要在更多不同类型的模型和更广泛的任务领域(如编程、更复杂的逻辑推理)上进行验证。观察到的最佳少数派比例(如20%)也可能因具体的模型和任务而异,需要灵活调整。
结论:AI学会抓重点,未来可期
说到底,这项研究就像是为我们揭示了AI在解决复杂问题时的一个小窍门:它们并非对每一个细节都平均用力,而是懂得在关键的岔路口集中智慧。通过识别并重点关注那些充满不确定性但又至关重要的高熵少数词元,我们不仅能更深入地理解AI的思考机制,还能找到更高效的训练方法。
这不仅仅意味着我们可以用更少的计算资源训练出更聪明的AI,更重要的是,它为我们打开了一扇新的大门,去探索如何让AI学会更灵活、更具创造性地思考。未来,这些发现可能会启发更多针对性的AI算法,不仅用于强化学习,还可能影响监督学习、知识蒸馏、甚至是多模态AI的训练方式。
想象一下,如果AI能够像经验丰富的侦探一样,迅速锁定案件的关键线索(高熵词元),而不是在无关紧要的细节上浪费时间,那么它们解决问题的能力将会提升到怎样的高度呢?
如果你对这项工作的技术细节或者更深入的讨论感兴趣,不妨去阅读他们的原始论文或者访问他们的项目主页。
项目主页:
https://shenzhi-wang.github.io/high-entropy-minority-tokens-rlvr
论文地址:
https://arxiv.org/abs/2506.01939
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q:AI推理的关键点到底是什么?
A:AI推理的关键点在于思维链中的"高熵词元"(high-entropy tokens),即那些让AI感到选择困难的决策点。这些词元类似思维迷宫中的岔路口,决定了推理方向,占整个思考过程的约20%。
Q:为什么只训练20%的高熵词元反而效果更好?
A:研究发现,高熵词元是AI推理的关键岔路口,专注于这些词元的强化学习能更高效优化决策质量。实验显示,仅训练Qwen3-32B模型的20%高熵词元,其数学竞赛准确率提升11.04%,远超传统全词元训练方法。
Q:AI二八法则对实际应用有什么帮助?
A:该技术可提升AI在复杂任务(如数学题、代码生成)中的推理效率和泛化能力。例如,通过精准优化关键决策点,AI能更快适应新问题,减少无效计算,未来或应用于多模态模型训练及自动化推理系统优化。
来源:至顶AI实验室
好文章,需要你的鼓励


ORV:4D占用中心机器人视频生成——北京人工智能研究院打造精准可控的机器人世界
这项研究提出了ORV(占用中心机器人视频生成)框架,利用4D语义占用作为中间表示来生成高质量的机器人操作视频。与传统方法相比,ORV能提供更精确的语义和几何指导,实现更高的时间一致性和控制精度。该框架还支持多视角视频生成(ORV-MV)和模拟到真实的转换(ORV-S2R),有效弥合了虚拟与现实之间的差距。实验结果表明,ORV在多个数据集上的表现始终优于现有方法,为机器人学习和模拟提供了强大工具。

自我反思助力AI成长:Writer团队提出强化学习优化模型自我纠错能力的突破性研究
这项研究由Writer公司团队开发的"反思、重试、奖励"机制,通过强化学习教导大型语言模型生成更有效的自我反思内容。当模型回答错误时,它会生成反思并二次尝试,若成功则奖励反思过程。实验表明,该方法在函数调用和数学方程解题上带来显著提升,最高分别改善18.1%和34.7%。令人惊讶的是,经训练的小模型甚至超越了同家族10倍大的模型,且几乎不存在灾难性遗忘问题。这种自我改进技术为资源受限环境下的AI应用开辟了新方向。

FuseLIP:通过早期融合离散标记实现多模态嵌入的突破性研究
FuseLIP是一项突破性研究,提出了通过早期融合离散标记实现多模态嵌入的新方法。与传统CLIP模型使用独立编码器不同,FuseLIP采用单一编码器同时处理图像和文本标记,实现了更自然的模态交互。研究证明,这种早期融合方法在多种多模态任务上表现优异,特别是在需要理解图像结构而非仅语义内容的任务上。研究还开发了创新的数据集和评估任务,为多模态嵌入研究提供了宝贵资源。

解锁多语言多条件查询的新纪元:ByteDance多语言语义检索系统MERIT
ByteDance与浙江大学合作开发的MERIT是首个专为多语言多条件语义检索设计的基准数据集,包含320,000条跨5种语言的查询和135,000个产品。研究发现现有模型在处理多条件查询时过度关注全局语义而忽略特定条件元素,为此提出CORAL框架,通过嵌入重建和对比学习相结合的方式,使检索性能提升45.9%。这项研究不仅识别了现有方法的关键局限性,还为多条件交错语义检索领域的未来研究奠定了基础。
2025
06/05
18:19
分享
点赞

2025思爱普中国峰会:商业AI持续释放数据价值,驱动企业韧性增长
Snap 推出 Lens Studio iOS 与网页版应用,用 AI 和简单工具创建 AR Lens
国家网络安全中心阐述如何构建网络安全文化
Epic Games 揭示 2025 年 Unreal 现状
AI测试趋势洞察、行业实践探索与未来展望
Snapchat 全球推出 Apple Watch 应用
中国光网络研讨会“卫星光通信与智能组网技术”首届专项研讨会召开
亚马逊神秘研发实验室开发集成agentic AI软件的机器人
数据中心的绿色存储
别再猜测为什么你的大语言模型出错: Anthropic 的新工具能准确显示问题所在
Samsung 联手 Glance 利用你的面容实现 AI 生成锁屏广告
未来预测:逐年推进 AI 迈向 2040 年实现 AGI 的路径
