
AI终于学会了"看声音":Captions公司让机器理解语音背后的表情和手势 原创
我们回想一下电影的发展史,从默片时代的卓别林到现代的好莱坞大片,最关键的转折点就是1920年代末“有声电影”的诞生。

在那之前,观众只能看到演员的动作表情,却听不到他们的声音。而现在的AI视频生成技术,恰恰也处在这样一个关键转折点上。
目前市面上的AI视频生成工具就像早期的默片——要么能制作出漂亮的无声画面,要么只能在现有图片基础上添加一些简单的嘴部动作来配合声音。
最近,来自Captions公司的研究团队发布了一项令人瞩目的研究成果,他们开发出了名为"Mirage"的AI模型。
Mirage的革命性突破就在于,它能够从一段音频中"听出"说话者应该有什么样的表情、手势和身体动作,然后生成完全匹配的视频画面。这就像一个极其敏感的观察者,仅仅通过听你的声音,就能准确想象出你此时的表情、手势,甚至是你所处的环境。
神奇的"读心术":从声音到画面的魔法
这种技术被称为"A-roll生成"。在影视制作中,A-roll指的是主要的叙事画面,比如演员对着镜头说台词的镜头。这些画面是整部影片的骨架,需要音画高度同步。想象一下新闻主播播报新闻时的状态——他们的表情、手势、眼神都要与所说的内容完美配合,这正是Mirage要实现的效果。
Mirage的工作原理就像一位经验丰富的配音导演。当配音导演听到一段录音时,他能立即在脑海中想象出演员应该有的表情和动作。Mirage也是如此,它通过深度学习"观看"了大量真实的说话视频,学会了声音和画面之间的微妙关系。
这个学习过程就像我们小时候学习说话一样。婴儿通过观察父母说话时的嘴型、表情和手势,逐渐理解声音和视觉之间的联系。Mirage也经历了类似的学习过程,只不过它观看的是数以万计的视频片段,从中发现了人类说话时的各种规律。
当Mirage接收到一段音频时,它会像侦探分析线索一样,从中提取出丰富的信息。首先,它会分析说话的内容——是在讲笑话、表达愤怒,还是解释复杂概念。然后,它会注意声音的特质——是男性还是女性的声音,年轻还是年长,兴奋还是平静。最有趣的是,它甚至能从背景声音中推断环境——如果听到回声,就知道可能在室内;如果有交通噪音,就判断可能在户外。
基于这些分析,Mirage开始"想象"画面。就像一个导演在脑海中构思镜头一样,它会决定说话者应该是什么样子——外貌特征、穿着打扮、表情神态,甚至包括背景环境的布置。然后,它会让这个虚拟的说话者"活"起来,产生与音频完全同步的嘴型、表情变化和手势动作。
技术架构:构建AI"大脑"的精密工程
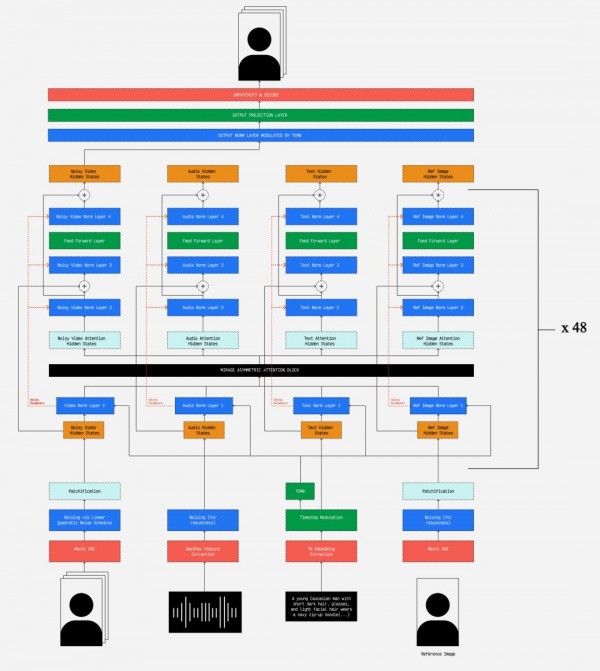
要理解Mirage的技术架构,我们可以把它想象成一个复杂的翻译系统,只不过它翻译的不是语言,而是将听觉信息转换为视觉信息。这个系统的核心是一种叫做"Diffusion Transformer"的AI架构,我们可以把它看作一个特别聪明的艺术家。
这位AI艺术家有着独特的工作方式。想象一下,如果你要画一幅肖像画,通常是先勾勒出大致轮廓,然后逐步添加细节,最后进行精细修饰。Mirage采用了类似但更加巧妙的方法——它从随机的噪点开始,就像从一张布满墨点的纸开始作画,然后通过多次迭代,逐步将这些噪点"雕琢"成清晰的视频画面。
这个过程被称为"flow matching",就像水流从混乱状态逐渐汇聚成清澈的溪流一样。在每一步迭代中,AI都会参考音频信息,确保生成的画面与声音保持一致。这就好比雕刻家在雕刻过程中不断对照着模特,确保作品的每个细节都准确无误。
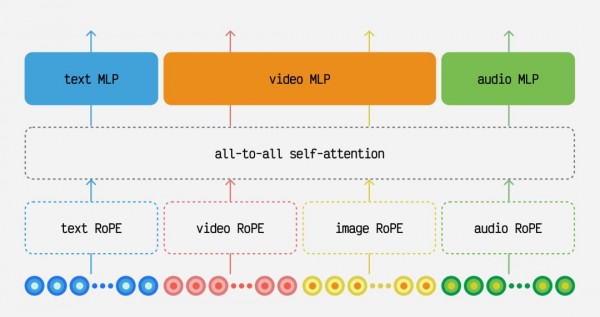
更令人惊奇的是,Mirage还使用了一种叫做"自注意力机制"的技术。想象一下,当你在听一个复杂故事时,你的大脑会同时关注故事的多个方面——情节发展、人物情感、环境描述等,并且能够理解它们之间的关系。Mirage的自注意力机制正是模拟了这种能力,它能同时处理音频、文本描述和参考图像等多种信息,并理解它们之间的相互关系。
在数据处理方面,研究团队开发了一套精密的"食材准备"系统。就像顶级餐厅需要精心挑选和处理食材一样,Mirage也需要高质量的训练数据。研究团队建立了一个复杂的数据筛选系统,从海量的视频中挑选出最适合训练的片段。他们使用了多种"质检标准":视频画面要稳定、音质要清晰、说话者的表情要自然、嘴型要与声音同步等等。
这个筛选过程就像淘金一样严格。原始数据中,只有大约四分之一能通过初步筛选,经过层层过滤后,最终用于训练的高质量数据更是精益求精。这种严格的筛选确保了Mirage学习到的都是最准确、最自然的语音-视觉对应关系。
训练过程:打造AI"演员"的专业课程
训练Mirage的过程就像培养一个万能演员。这个演员需要学会扮演不同年龄、性别、性格的角色,还要掌握各种情感表达和肢体语言。整个训练过程可以分为几个阶段,每个阶段都有明确的学习目标。
首先是基础训练阶段,类似于演员学习基本发声和形体。在这个阶段,Mirage学习最基础的音画对应关系——比如说"a"音时嘴型应该张开,说"m"音时嘴唇应该闭合。这些看似简单的规律,实际上是所有后续复杂表演的基础。
研究团队特别关注了一个叫做"发音与口型同步"的细节。他们发现,人类说话时的口型变化非常复杂精细。比如说"peter"这个词,每个字母对应的嘴型都不同,而且变化过程是连续流畅的,不是机械的切换。Mirage需要学会这种自然的过渡,就像真正的人类说话一样。
接下来是情感表达训练。就像演员需要学会表达喜怒哀乐一样,Mirage也要学会根据语音中的情感色彩生成相应的表情。研究团队发现,即使说同样的话,开心时和悲伤时的表情、眼神、甚至肩膀的姿态都会有微妙差异。Mirage通过观察大量真实情感表达的视频,逐渐掌握了这些细腻的变化。
更有趣的是手势和身体语言的训练。人类说话时的手势并不是随机的,而是与语言内容密切相关的。比如在描述大小时会用手比划,在强调重点时会做切手动作,在表示不确定时会摸头或耸肩。Mirage学会了这些微妙的关联,能够生成与说话内容高度匹配的手势和身体动作。
研究团队还发现了一些意想不到的细节。比如,Mirage竟然学会了从音频中推断说话环境。当音频中有回声时,它会生成室内环境的背景;当有风声或交通噪音时,它会生成户外场景。这就像一个经验丰富的录音师仅仅听声音就能判断录音环境一样神奇。
令人惊叹的表现:AI展现出的"人性"细节
Mirage的表现令研究者们都感到惊讶,它展现出了许多连开发者都没有特别训练的能力。这些能力的出现,就像一个学生突然展现出老师没有教过的才华一样让人欣喜。

最令人印象深刻的是Mirage对细微发音的精准把握。研究团队测试了各种复杂的发音,包括绕口令。比如"Peter Piper picked a peck of pickled peppers"这样的绕口令,其中包含大量相似但又不同的音素。Mirage不仅能准确同步每个音的嘴型,还能表现出说绕口令时的那种专注表情和轻微的舌头动作。
更有趣的是,Mirage还学会了眨眼。虽然研究团队从来没有专门教过它什么时候该眨眼,但它却展现出了非常自然的眨眼模式。而且这种眨眼不是机械重复的,而是符合人类眨眼规律的——有时频繁一些,有时稀疏一些,甚至在思考时会有略长的眨眼。
Mirage在情感表达方面的表现同样出色。当处理带有特定情感色彩的音频时,它不仅会调整面部表情,还会相应改变整体的身体语言。开心时,整个人会显得更加放松和开放;紧张时,肩膀会微微紧绷;思考时,可能会轻微皱眉或者眼神向上。这些细节的准确性让生成的视频看起来真实可信。
甚至更神奇的是,Mirage能够从纯音频中推断出说话者的一些身体特征。比如从声音的特质推断性别、大致年龄,甚至是身材特点。当然,这种推断并不总是完全准确,但准确率高得令人惊讶。研究团队测试发现,即使没有提供任何视觉参考,Mirage生成的人物形象往往与真实说话者有相当程度的相似性。
研究团队还发现了Mirage的一个"意外技能"——它能处理各种非语言声音。比如咳嗽、打喷嚏、笑声等。当音频中出现咳嗽声时,Mirage会让生成的人物做出咳嗽的动作和表情;当听到笑声时,会生成相应的笑容和愉悦表情。这些都不是专门训练的结果,而是模型在学习过程中自然掌握的能力。
突破传统的技术创新
Mirage最值得称道的创新在于它采用了一种"大一统"的方法。传统的音视频生成技术就像专门的工匠,每个工匠只会做一种特定的工作——有的专门负责嘴型同步,有的专门负责表情生成,有的专门负责手势动作。最后需要将这些分别制作的部分拼接起来,结果往往显得不够自然。
而Mirage更像是一个全能的表演艺术家,它用一个统一的"大脑"来协调所有的表演元素。这种统一的方法带来了意想不到的好处——生成的视频中,表情、嘴型、手势、身体动作都是协调一致的,就像真人表演一样自然流畅。
在技术架构上,Mirage采用了一种叫做"asymmetric self-attention"的机制。用通俗的话说,这就像一个极其专业的导演,能够同时关注演员表演的多个方面,并确保它们之间的协调配合。这个"导演"不仅关注当前的表演片段,还会考虑前后的连贯性,确保整个表演的流畅性。
另一个重要创新是训练方法的简化。传统方法需要为不同类型的条件输入(音频、文字、图片等)设计专门的处理模块,就像需要不同的翻译器来处理不同的语言。而Mirage使用了一种"万能翻译器"的方法,能够统一处理各种不同类型的输入信息。这不仅简化了系统设计,还提高了不同信息类型之间的协调性。
研究团队还开发了一套创新的训练策略。他们发现,如果让模型同时学习所有技能,就像让一个学生同时学习数学、语文、英语一样,可能会相互干扰。所以他们采用了"先分后合"的策略——先让模型分别掌握各项基础技能,然后再学习如何将这些技能整合运用。
实际应用:从实验室到日常生活
Mirage的应用前景就像智能手机刚出现时一样令人兴奋——你能想象到一些明显的用途,但更多的可能性还有待发掘。目前,这项技术已经集成到Captions公司的多个产品中,为用户提供实际的服务。
最直接的应用是内容创作领域。想象一下,如果你是一个YouTuber或者自媒体创作者,你可以用自己的声音录制一段音频,然后让Mirage生成配套的视频画面。这意味着你不需要花费大量时间在摄像头前反复录制,也不用担心化妆、灯光、背景等视觉因素。你只需要专注于内容本身,技术会为你处理其余的一切。
在教育领域,Mirage可能会带来革命性的变化。教师可以制作更加生动的教学视频——不仅有声音解释,还有同步的手势、表情和身体语言。这对于语言学习特别有价值,学生可以同时学习发音和相应的口型、表情。
企业培训是另一个重要应用场景。公司可以使用Mirage制作标准化的培训视频,确保所有员工接受一致的培训内容。而且这些视频可以根据不同地区、不同语言的需求进行定制,只需要改变音频,视频画面会自动调整。
在无障碍服务方面,Mirage也有巨大潜力。对于听障人士,它可以为音频内容自动生成相应的视觉表现,包括嘴型、表情和手势,这比传统的字幕提供了更丰富的信息。对于视障人士,虽然他们看不到画面,但Mirage的技术原理也可以反向应用——从视频中提取更丰富的音频描述。
在国际化内容制作方面,Mirage展现出了独特优势。当需要将一种语言的内容翻译成另一种语言时,传统方法是重新录制或配音。而有了Mirage,只需要提供翻译后的音频,就能生成匹配的新视频,大大降低了国际化的成本和复杂度。
技术挑战与巧妙解决方案
开发Mirage的过程并非一帆风顺,研究团队遇到了许多技术挑战,他们的解决方案往往充满创意和智慧。
最大的挑战之一是数据质量控制。网络上虽然有海量的视频内容,但真正适合训练的高质量数据却稀少得像金子一样珍贵。许多视频存在音画不同步、画质模糊、背景嘈杂等问题。研究团队开发了一套精密的"质检流水线",就像珠宝商挑选钻石一样严格。

他们使用了多种自动化检测工具。比如,用专门的算法检测视频中是否有分屏或文字覆盖,因为这些元素会干扰训练效果。他们还使用了唇同步检测技术,确保训练数据中的音频和嘴型是准确对应的。更有趣的是,他们甚至开发了运动检测算法,过滤掉那些画面过于静止或者运动过于剧烈的视频。
另一个重大挑战是计算资源的管理。训练Mirage需要处理海量数据,就像同时烹饪上千道复杂菜肴一样,需要精确的资源调度和协调。研究团队开发了一套分布式训练系统,能够将巨大的计算任务分解到多个GPU上并行处理。
更巧妙的是,他们还开发了一种"容错机制"。在如此大规模的训练过程中,硬件故障是不可避免的,就像长途旅行中可能遇到的意外状况。他们的系统能够自动检测和替换故障设备,确保训练过程不会因为个别设备的问题而中断。
在模型推理速度方面,研究团队也遇到了挑战。用户当然希望能够快速生成视频,而不是等待几个小时。他们采用了多种优化策略,包括模型量化、并行推理等技术。其中最有创意的是一种叫做"inference time caching"的方法——就像厨师预先准备一些半成品,在接到订单时能够更快完成菜品一样,这种方法能够将推理速度提升40%。
令人惊叹的实验结果
研究团队通过大量实验验证了Mirage的能力,这些实验结果就像魔术表演一样令人惊叹。
在发音准确性测试中,研究团队特别关注了英语中的六个爆破音:p、t、k、b、d、g。这些音素在发音时需要特定的嘴型和舌位,是测试唇同步技术的经典难题。Mirage在这些测试中表现得近乎完美,不仅能准确同步每个音素的嘴型,还能表现出发音时的细微肌肉运动。
更有挑战性的是绕口令测试。研究团队用"Peter Piper picked a peck of pickled peppers"这样的经典绕口令来测试Mirage。结果表明,即使在如此快速和复杂的发音序列中,Mirage仍然能保持精确的唇同步,同时还会表现出说绕口令时特有的专注表情和轻微的头部动作。
在情感表达测试中,研究团队让Mirage处理带有不同情感色彩的相同文本。比如用开心、悲伤、愤怒、恐惧等不同情绪说同一句话。Mirage不仅能生成相应的面部表情,还会调整整体的身体语言——开心时身体更加放松开放,愤怒时肩膀紧绷,恐惧时略微后缩。
特别有趣的是跨性别测试。当研究团队故意提供不匹配的音频和文本描述时(比如男性声音配女性外貌描述),Mirage会尝试在两者之间找到平衡。结果往往是生成一个具有中性特征的人物形象,显示出模型试图协调矛盾信息的能力。
在环境推断测试中,Mirage展现了令人意想不到的能力。仅仅通过分析音频中的背景噪音和回声特征,它能够推断出录音环境,并生成相应的背景设置。室内录音会生成书房、办公室等背景,而带有交通噪音的户外录音则会生成街道、公园等场景。
技术局限与未来展望
尽管Mirage表现出色,但研究团队也诚实地指出了现有技术的局限性,这种科学的态度让这项研究更加可信。
目前最明显的局限是在处理复杂场景时的表现。当文本描述过于复杂,包含太多细节要求时,Mirage的表现会有所下降。这就像要求一个演员同时处理过多的表演指令,可能会顾此失彼。研究团队发现,简洁明确的指令往往能获得更好的结果。
另一个局限是在处理极端情况时的稳定性。比如音频质量很差、包含大量噪音,或者说话者有特殊的发音习惯时,Mirage的表现可能不够稳定。这提醒我们,AI技术虽然强大,但仍然需要相对标准化的输入才能发挥最佳效果。
在计算资源需求方面,Mirage目前还需要相当强大的硬件支持。虽然研究团队已经在优化效率方面做了大量工作,但要让这项技术真正普及到普通用户的设备上,还需要进一步的技术突破。
展望未来,研究团队提出了几个令人兴奋的发展方向。首先是提高模型的泛化能力,让它能够处理更多样化的语言、方言和说话风格。目前的模型主要在英语数据上训练,扩展到其他语言将是一个重要方向。
其次是提高生成质量的一致性。虽然Mirage在大多数情况下表现出色,但在一些边缘情况下仍有改进空间。研究团队正在探索更先进的训练方法和架构改进。
更有趣的是,研究团队还在考虑双向应用的可能性。目前Mirage是从音频生成视频,但这个过程也可以反向进行——从视频中提取更丰富的音频描述,这对无障碍服务有重要意义。
在实时应用方面,研究团队的目标是让Mirage能够实现真正的实时生成,这将为视频通话、直播等应用场景打开新的可能性。想象一下,未来的视频会议中,你可以选择用AI生成的虚拟形象代替真实的自己,同时保持完全自然的表达效果。
至顶AI实验室洞见
Mirage代表的不仅仅是一项技术突破,更是AI理解人类交流方式的重要进步。
人类之间的交流从来不是单纯的语言或单纯的视觉,而是两者的完美融合。当我们说话时,我们用声音传递信息,用表情传递情感,用手势强调重点,用眼神建立连接。Mirage的成功在于它开始理解并模拟这种复杂而微妙的人类交流方式。
这项技术的意义远远超出了视频制作本身。它让我们看到了AI在理解人类行为方面的巨大潜力,也为未来更自然的人机交互奠定了基础。也许在不久的将来,我们与AI的交流会变得像与朋友聊天一样自然舒适。
像任何新技术一样,Mirage的出现也带来了新的思考。当AI能够如此逼真地模拟人类表达时,我们需要思考如何确保这项技术被用于正面的目的,如何在享受技术便利的同时保护隐私和真实性。
论文地址:
https://arxiv.org/pdf/2506.08279
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A:
Q1:Mirage是什么?它能做什么?
A: Mirage是由Captions公司开发的AI视频生成模型,它的核心能力是仅通过音频就能生成完全匹配的说话视频。简单来说,你只需要提供一段语音,Mirage就能创造出一个虚拟人物,这个人物的嘴型、表情、手势和身体动作都与音频内容完美同步。
它就像一个超级智能的演员,能够"听出"声音中的情感色彩、说话者特征,甚至是录音环境,然后生成相应的视觉表现。比如听到开心的声音会生成笑容,听到室内录音会生成室内背景。这项技术主要用于内容创作、教育培训、无障碍服务等领域。
Q2:Mirage会不会取代真人视频制作?
A:目前不会完全取代,但会大大改变视频制作方式。Mirage更像是一个强大的制作工具,而不是真人的替代品。它的优势在于效率和便利性:创作者不需要化妆、布置灯光、反复录制,只需录制音频就能生成视频。这对于教学视频、培训内容、多语言版本制作等场景非常有用。
但Mirage仍有局限性:处理复杂场景时表现下降,需要高质量音频输入,对硬件要求较高。而且在需要真实情感交流、复杂互动的场景中,真人表演仍然不可替代。未来更可能是人机协作的模式,用AI提高制作效率,用真人保证情感深度。
Q3:如何使用Mirage?有什么要求?
A: 目前普通人可以通过Captions公司的产品体验Mirage技术(网址:https://mirage.app),但还不是完全普及的消费级产品。
使用要求相对简单:主要需要提供清晰的音频文件,最好是16kHz单声道格式。音频质量越好,生成效果越佳。用户还可以添加文字描述来指定人物外貌、背景环境等细节,但不是必需的。
技术门槛方面,目前Mirage对硬件要求较高,需要强大的GPU支持。不过研究团队正在优化,未来可能会有更轻量级的版本。对于一般用户来说,通过云端服务使用会是更现实的选择,就像现在使用ChatGPT一样方便。
来源:至顶AI实验室
好文章,需要你的鼓励


芯片制造商Ambiq Micro IPO募资9600万美元,股价暴涨超60%
芯片制造商Ambiq Micro在纽约证券交易所首日交易中股价飙升超60%。该公司通过IPO融资9600万美元,售出400万股,每股24美元。总部位于奥斯汀的Ambiq专注于可穿戴设备和电视遥控器等电池供电设备的处理器。其旗舰芯片Apollo510集成CPU和GPU,可运行AI模型并具备网络安全功能。

新加坡国立大学提出TPDiff:让AI视频生成快两倍的神奇“时间金字塔“
新加坡国立大学研究团队提出TPDiff(时间金字塔视频扩散模型),通过在扩散过程中逐步增加帧率的创新策略,实现了AI视频生成50%的训练成本削减和1.5倍推理效率提升。该方法基于视频帧间冗余和扩散过程熵减特性,设计了阶段性扩散训练框架,在保持视频质量的同时显著降低计算复杂度,为AI视频生成的实用化提供了重要技术突破。

Lightbits与Supermicro服务器共享块存储测试创IOPS新高
Lightbits声称在使用超微服务器硬件的基准测试中,为容器化事务处理展示了最快的共享块存储性能。测试配置采用AMD EPYC 9575F处理器和8块三星NVMe SSD,实现了360万4K随机读IOPS、160万4K随机写IOPS等优异成绩。双方发布的Kubernetes参考架构结合了Lightbits的NVMe/TCP存储技术,为金融交易、实时分析、AI训练等高性能应用提供解决方案。

AI推理也能“画草图“?KAIST团队让大模型思考更高效
KAIST研究团队开发出"思维草图"方法,让大型语言模型像人类专家一样进行简洁高效的推理。该方法通过三种认知启发的推理方式和智能路由系统,在15个数据集上实现平均73%的输出减少,同时保持甚至提升推理准确性,为AI应用的效率优化提供了重要突破。
2025
06/12
17:57
分享
点赞

Lightbits与Supermicro服务器共享块存储测试创IOPS新高
5G独立组网推动移动核心网络市场加速发展
希捷凭借HAMR技术实现30%增长,摆脱业绩低迷
美光推出276层SSD三剑客:兼顾速度、容量与稳定性
谷歌AI搜索模式新增PDF分析和实时视频功能
Lightbits与Supermicro联合测试创共享块存储IOPS性能新高
Enfabrica推出弹性AI内存架构提升GPU工作负载效率
重塑企业未来的四种AI商业模式
Gemini CLI编码工具存在安全漏洞,黑客可利用其执行恶意命令
戴尔科技助推企业筑牢安全基石 实现创新突破
五大策略助CIO降低IT成本且不影响创新
思科向Linux基金会捐赠Agntcy项目,助力AI智能体优雅交互
