
AI真的知道自己知道什么吗?Meta团队重磅突破:让AI学会说“不”,幻觉问题锐减至5%以下 原创
当我们向AI提问时,最担心的是什么?是它信口开河地给出错误答案,还是老实地说“我不知道”?
Meta Reality Labs研究团队发表了一项开创性研究,他们找到了一种让大型语言模型学会谦逊的方法。这项研究解决了当前AI领域最令人头疼的问题之一:幻觉现象。
什么是幻觉?就像一个不懂装懂的人,明明不知道答案却硬要编造一个看似合理的回答。
为了解决这个问题,研究团队开发了一种叫做ConfQA的训练方法。
这个方法的核心思想出奇地简单:当AI能够正确回答问题时,就让它继续给出答案;当它回答错误时,就训练它老实地说"我不确定"。这就像训练一个学生,让他知道什么时候该承认自己不知道,而不是瞎蒙一个答案。
让这个看似简单的想法能够真正发挥出作用,研究团队发现了两个关键要素。
首先是一个特殊的"约束提示词"——"只有在你确信的时候才回答",这个简单的提示就像给AI装上了一个内在的"谨慎开关",没有这个提示,幻觉率仍然高达15%-25%。其次,他们发现使用简单的事实陈述来训练模型效果最好,特别是那些描述实体属性的基础知识,比如"埃菲尔铁塔在哪个城市"这样的问题。
研究背景:当AI变得过分自信
在深入了解ConfQA方法之前,我们需要理解当前AI面临的困境。现代大型语言模型在训练过程中积累了大量知识,但它们往往像一个什么都想回答的热心学生,即使不确定答案也要硬着头皮给出回复。
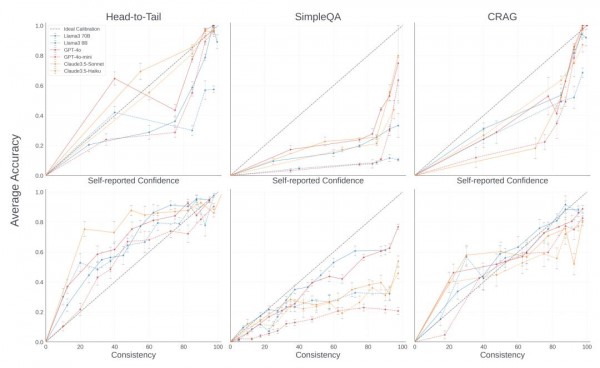
研究团队首先探索了一个根本问题:AI真的知道自己知道什么吗?通过大量实验,他们发现AI确实具备一定的"自我认知"能力,但这种认知存在严重偏差。当AI声称对某个答案有很高信心时,实际准确率往往远低于其声称的信心水平。这种现象在不同规模的模型中都存在,而且有趣的是,较小的模型往往比较大的模型更加自信,体现了"无知者无畏"的特征。
研究团队还发现,如果让AI多次回答同一个问题,然后看答案的一致性,这种一致性与准确性的关联度要比自我报告的信心分数更可靠。但是这种方法需要多次调用AI,成本高昂且耗时,在实际应用中并不现实。
当前解决幻觉问题的主要方法是检索增强生成(RAG),也就是让AI在回答问题时先去查找外部资料,然后基于这些资料给出答案。这就像让学生考试时可以翻书,确实能提高准确性。但问题是,什么时候该翻书,什么时候应该依靠自己的知识呢?如果每个问题都要查资料,不仅耗费时间和计算资源,还可能被不相关的信息干扰。
ConfQA方法:教AI学会谦逊的艺术
ConfQA方法的核心就像训练一个诚实的学生。研究团队首先从DBPedia知识图谱中提取了大量简单的问答对,这些问题都是关于实体属性的基础事实,比如"巴黎是哪个国家的首都"、"披头士乐队有多少成员"等。
训练过程分为两个步骤。第一步,研究团队让Llama-3.1-70B模型回答这些问题,然后用更强大的Llama-3.1-405B模型来判断答案是否正确。如果答案正确,就将正确答案作为训练标签;如果答案错误,就将"我不确定答案"作为训练标签。这个过程就像一个老师在批改作业,对于答错的题目,不是直接给出正确答案,而是告诉学生"你答错了,下次遇到不确定的时候要承认"。
第二步是加入"约束提示词"。研究团队发现,在训练和推理时都加入"只有在你确信的时候才回答"这个简单提示,能够显著提升效果。这个提示就像给AI设置了一个心理暗示,让它在回答前先问问自己"我真的确定吗?"
为什么选择简单的事实问题来训练?研究团队的想法很巧妙:简单的事实就像建筑的基础,如果AI能够在这些基础事实上保持诚实和准确,这种行为模式就能推广到更复杂的问题上。这就像学习数学,先掌握加减法,再学习复杂的方程式。
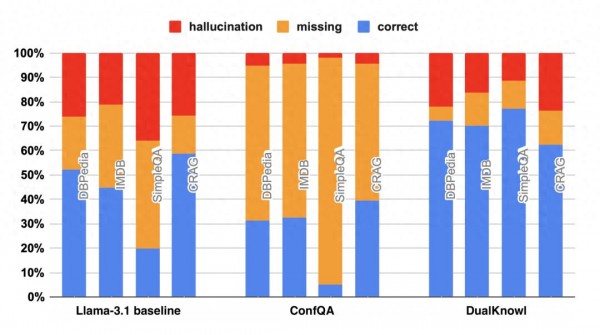
训练完成后的ConfQA模型表现出了显著的改进。在多个基准测试中,幻觉率从原来的20%-40%降低到了5%以下。更令人惊喜的是,虽然训练数据只来自DBPedia,但模型在其他领域(如IMDb电影数据库)和其他类型的问题上也表现出了相似的改进,展现出强大的泛化能力。
双神经知识框架:内外兼修的智能系统
基于ConfQA的成功,研究团队进一步提出了"双神经知识框架"(DualKnowl)。这个框架就像给AI配备了两个大脑:一个是内在的神经网络知识,另一个是外部的检索系统。
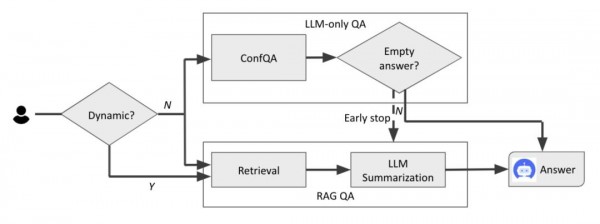
这个框架的工作原理很像一个聪明的研究员。当遇到问题时,它首先会同时启动两个过程:一方面用自己的知识(ConfQA模型)尝试回答,另一方面开始检索外部资料。但是,如果满足以下两个条件之一,系统就会提前终止外部检索:第一,如果问题询问的是动态信息(比如"今天的天气"或"最新股价"),系统会等待外部检索结果;第二,如果ConfQA模型回答"我不确定",系统也会等待外部检索。
这种设计的巧妙之处在于,它能够根据AI的信心水平智能地决定是否需要外部信息。当AI对自己的知识有信心时,就直接给出答案,节省时间和资源;当AI不确定时,就求助于外部检索,确保准确性。
实验结果显示,这个双重框架既保持了准确性(达到95%以上),又将外部检索的使用频率降低了30%以上,在CRAG基准测试中节省了600毫秒的响应时间。这就像一个高效的图书馆管理员,既能快速回答常见问题,又知道什么时候该去查阅资料。
实验验证:跨领域的惊人表现
研究团队在多个不同的基准测试上验证了ConfQA方法的有效性。这些测试覆盖了从简单的事实问答到复杂的长篇回答,从流行实体到冷门知识,从单一领域到跨领域应用。
在短篇回答测试中,ConfQA在Head-to-Tail、SimpleQA和CRAG等基准上都表现出色。特别值得注意的是,当使用约束提示词时,模型的幻觉率在所有测试中都降到了5%以下。虽然这会导致正确答案的数量有所下降(因为模型变得更加保守),但整体的事实准确性得到了显著提升。
在长篇回答测试中,ConfQA同样表现优秀。在LongFact和Biography等需要生成多段落回答的任务中,模型不仅保持了较高的准确率,还学会了在不确定时保持沉默,避免了编造虚假信息。
最令人印象深刻的是模型的泛化能力。虽然训练数据完全来自DBPedia,但ConfQA在电影、音乐、体育等其他领域的表现同样出色。这说明"学会说不知道"这种能力确实可以从一个领域迁移到其他领域。
研究团队还特别关注了不同流行度实体的表现。他们发现,ConfQA在处理冷门实体(tail entities)时更加谨慎,这是合理的,因为模型对这些实体的知识本来就比较有限。这种行为模式正是我们希望看到的:对于不太了解的事物保持更多的谦逊。
技术细节与创新点
ConfQA方法的技术实现虽然概念简单,但在具体执行中有很多巧妙的设计。训练数据的构建过程经过了精心设计:研究团队使用了3000个高质量的问答对,平均分布在流行、中等流行和冷门实体之间。训练过程采用了较小的学习率(1e-6)和短期训练(1个epoch),避免了过拟合。
研究团队还进行了详细的消融实验,验证了各个组件的重要性。结果显示,约束提示词的作用非常关键:没有它,幻觉率仍然高达15%-25%;有了它,幻觉率能降到5%以下。这个简单提示词的巨大效果说明,有时候最有效的解决方案并不复杂,关键是找到正确的方向。
另一个重要发现是训练数据的选择策略。研究团队比较了使用DBPedia(简单事实)和MMLU(混合技能和知识)作为训练数据的效果,发现专注于简单事实的训练效果更好。这支持了他们的假设:通过在基础事实上建立诚实的行为模式,可以推广到更复杂的场景。
在与其他方法的对比中,ConfQA展现出了独特的优势。与R-Tuning等现有方法相比,ConfQA在保持较低幻觉率的同时,能够维持更高的正确回答率。这种平衡很重要,因为我们既希望AI不要胡说八道,也希望它能够充分利用自己确实掌握的知识。
实际应用与未来展望
ConfQA方法不仅在学术实验中表现出色,在实际应用中也展现出巨大潜力。双神经知识框架为构建更可靠的AI系统提供了新思路:既要利用AI的内在知识,又要知道什么时候求助于外部资源。
在客服系统中,ConfQA可以帮助AI客服更好地处理用户询问。当遇到常见问题时,AI可以直接给出答案;当遇到不熟悉的问题时,AI可以诚实地说"让我查一下资料",然后调用检索系统寻找准确信息。这种做法不仅提高了回答的准确性,还增强了用户对AI的信任。
在教育场景中,ConfQA可以帮助AI导师成为更好的学习伙伴。一个懂得承认不知道的AI导师,比一个总是给出错误答案的AI导师更值得学生信赖。学生也能从AI的谦逊中学会:承认不知道并不丢人,重要的是找到正确的答案。
在医疗和法律等专业领域,ConfQA的价值更加明显。在这些领域,错误信息可能造成严重后果,AI系统必须知道自己的能力边界。一个会说"我需要查阅相关资料"的AI助手,比一个可能给出错误建议的AI助手更安全、更有用。
研究团队也指出了当前方法的一些局限性。ConfQA目前主要针对事实性问题,对于数学推理、编程等其他类型的任务,可能需要进一步的研究和改进。此外,该方法需要对模型进行微调,这意味着只能应用于开源模型,对于只能通过API访问的专有模型还无法直接使用。
未来的研究方向包括将这种"诚实文化"扩展到更多类型的任务,探索如何在不进行微调的情况下实现类似效果,以及研究如何让AI在保持谦逊的同时不过度保守。研究团队还计划探索使用强化学习等其他训练方法来进一步改进效果。
至顶AI实验室洞见
由此可见,ConfQA的价值不仅在于技术创新,更在于它代表了AI发展的一个重要方向:让AI变得更加诚实和可靠。
在AI能力日益强大的今天,教会AI说"我不知道"可能比教会它回答更多问题更加重要,毕竟,一个诚实的AI助手比一个看似无所不知但经常出错的AI更值得我们信赖。
未来的AI系统不仅会更加智能,还会更加诚实。当AI学会了谦逊,人机合作就能达到新的高度。
我们期待看到这种"诚实的AI"在更多场景中发挥作用,为人类提供更可靠、更值得信赖的智能服务。
论文地址:
https://arxiv.org/pdf/2506.07309v1
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:ConfQA是什么?它能解决什么问题?
A:ConfQA是Meta团队开发的一种训练方法,能让大型语言模型学会在不确定时说"我不知道",而不是编造错误答案。它将AI的幻觉率从20-40%降低到5%以下,显著提高了AI回答的可靠性。
Q2:ConfQA的训练方法有什么特别之处?
A:ConfQA有两个关键创新:一是使用"只有在你确信时才回答"的约束提示词,二是专门用简单的事实性问题进行训练。当AI回答正确时继续训练其给出答案,回答错误时训练其承认不知道。
Q3:双神经知识框架是如何工作的?
A:这个框架同时调用内部知识(ConfQA模型)和外部检索系统。当AI对答案有信心时直接回答,当AI说"不确定"或遇到动态信息时才使用外部检索,既保证准确性又节省了30%以上的检索成本。
来源:至顶AI实验室
好文章,需要你的鼓励


IT文艺复兴恐失势头,亟需重获关注
当前世界充满变数,IT领域除AI外鲜少受到关注。从气候变化到地缘政治紧张局势,IT在公众讨论中边缘化。这在技术变革关键时刻十分危险。CEO、高管和媒体对IT缺乏深度思考,普遍持"不坏就别谈"的态度。CIO需要重新获得利益相关者关注,克服对IT运营的冷漠和无知。技术文盲问题严重,大多数人从未构建过IT系统。IT行业需要重新赢得人心,大幅提升公众IT知识水平。

大语言模型为什么老是“胡编乱造“?OpenAI团队揭开AI幻觉的真相
OpenAI团队的最新研究揭示了大语言模型产生幻觉的根本原因:AI就像面临难题的学生,宁愿猜测也不愿承认无知。研究发现,即使训练数据完全正确,统计学原理也会导致AI产生错误信息。更重要的是,现有评估体系惩罚不确定性表达,鼓励AI进行猜测。研究提出了显式置信度目标等解决方案,通过改革评估标准让AI学会诚实地说"不知道",为构建更可信的AI系统指明方向。

每位CIO必须回答的11个变更管理问题
技术驱动的变革比以往更加频繁,但成功并不能得到保证。Gartner研究显示,只有五分之一的组织能够在75%或更多时间内从转型项目中获得预期收益。其余都是昂贵的失败。有效的变革管理能够提高技术采用率,服务于业务目标。变革管理不再是边缘活动或软技能,而是决定新举措是否能够创造商业价值的核心绩效学科。

ByteDance AI实验室发布重磅研究:让计算机学会“逆向思考“,解决创意写作难题
字节跳动AI实验室提出"逆向工程推理"新范式,通过从优质作品反推思考过程的方式训练AI进行创意写作。该方法创建了包含2万个思考轨迹的DeepWriting-20K数据集,训练的DeepWriter-8B模型在多项写作评测中媲美GPT-4o等顶级商业模型,为AI在开放性创意任务上的应用开辟了新道路。
2025
06/13
17:27
分享
点赞

阿里要用AI将云计算重做一遍
阿里夸克发布全新AI创作平台“造点”,已接入通义万相Wan2.5
蚂蚁数科提出隐私保护AI新算法,可将推理效率提升超过100倍
IT文艺复兴恐失势头,亟需重获关注
每位CIO必须回答的11个变更管理问题
Qorvo推出全新TDD波束成形芯片AWMF-0247,适用于紧凑型、高能效Ku波段卫星通信终端
阿里吴泳铭最新演讲:实现超级人工智能ASI的三个阶段
Google Photos对话式编辑功能向Android用户推出
斯坦福AI安全工作坊展示安全AI发展路径
Sila在美国开设硅负极材料工厂,助力高能量密度电动汽车电池生产
TechCrunch Disrupt 2025:构建太空新基础设施
谷歌AI模式全球推出西班牙语版本
