
模型训练越来越不需要人类了!清华等提出RLPR,让AI通过语言直觉训练 原创
你有没有刷到过 “间谍测试”短视频。视频里提问的人给出上句“宫廷玉液酒”“大锤八十”,如果回答的人对不上“一百八一杯”“小锤四十”,那么就被认为是“间谍”,因为这几个春晚经典桥段家喻户晓。
很巧的是,一个最新的AI模型训练算法RLPR,它的核心思想竟然跟这个对话过程出奇相似,也就是看模型能不能流利地输出标准答案,来判断模型有没有在蒙混过关。不知作者是否有部分灵感来自于此。
2025年6月23日,清华大学等多所知名院校共同提出新的AI训练方法Reinforcement Learning with Reference Probability Reward(基于参考概率奖励的强化学习,简称RLPR),论文发表于arXiv。RLPR能让AI通过自己的语言直觉来评判答案质量,在开放性问题上表现更好。
一个困扰AI界的老大难问题
开始之前,举个简单例子来理解强化学习和验证器。就好像教一个小孩子做数学题,当孩子做对了,我们会说“很好”,做错了我们会说“不对,再试试”。这种反馈机制在AI训练中被称为强化学习,而给出对或错判断的就是验证器。
在过去几年里,AI研究者们发现:通过这种奖励正确答案、惩罚错误答案的方式训练,AI在数学和编程方面变得异常聪明。这就像是给AI请了一位严格的数学老师,每道题都会仔细批改打分。这种方法被称为可验证奖励强化学习(RLVR),在数学推理和代码生成领域取得了令人瞩目的成功。
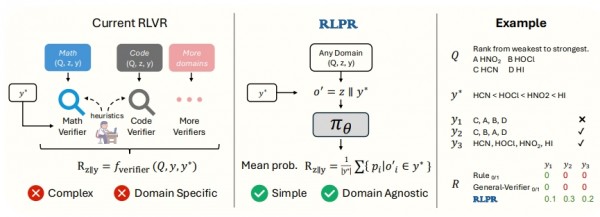
然而,这里有个巨大的限制。数学题有标准答案,代码能不能运行也很容易检验,但如果AI要回答“如何解决城市交通拥堵问题”或者“分析莎士比亚作品的艺术特色”这类开放性问题时,情况就完全不同了。这就像是让那位数学老师去批改文学作文或者历史论述题,根本没有标准答案可以参考。
现有的解决方案要么是花费大量时间为每个新领域专门设计复杂的规则系统(想象为每个学科都培养一位专门的老师),要么是训练专门的AI模型来充当验证器(相当于培养AI助教来批改作业)。但这两种方法都有明显的问题:设计规则系统需要大量的人工工作且很难涵盖所有情况,而训练验证器模型不仅成本高昂,效果也往往不尽如人意。
清华团队的巧妙突破
清华大学的研究团队提出了一个巧妙的解决方案,他们称之为RLPR(基于参考概率奖励的强化学习)。这个方法的核心思路可以这么理解:
设想你正在和一个朋友玩猜歌名的游戏。当播放一首歌的前几个音符时,如果你的朋友能够流利地说出正确的歌名,这说明他对这首歌很熟悉。相反,如果他结结巴巴、犹豫不决,那多半是不太确定。
RLPR的工作原理与此类似。当AI生成一个答案后,研究团队会让AI尝试复述标准答案的每个词汇。如果AI能够非常流利、高概率地生成出标准答案的每个词,这说明AI对这个问题理解得很好,应该给予高分奖励。如果AI在生成标准答案时磕磕绊绊、概率很低,那说明AI的理解还不够深入,应该得到较低的奖励。
这种方法的巧妙之处在于,它完全不需要外部的验证器,而是让AI自己的语言直觉来评判答案的质量。就像一个熟练的演讲者能够流畅地表达自己熟悉的内容一样,如果AI真正理解了一个问题,它就能够很自然地生成出相关的正确答案。
技术细节的通俗解释
研究团队在具体实现上做了几个关键的技术改进,让这个看似简单的想法真正发挥作用。
首先是概率计算的优化。最初的想法是将AI生成标准答案每个词的概率相乘,但这种方法就像是用多个小数相乘一样,结果会变得非常不稳定。比如说,0.01乘以0.7再乘以0.9,和0.05乘以0.7再乘以0.9,虽然只有第一个数字有微小差异,但最终结果却相差很大。
为了解决这个问题,研究团队改用了平均概率的方法,就像计算班级平均分一样,将所有词汇的概率加起来除以词汇总数。这种方法更加稳定可靠,不会因为某一个词的概率特别低就让整个分数变得极其糟糕。
其次是奖励偏差的消除。研究团队发现,即使没有经过推理过程,AI对某些问题的标准答案本身就有不同的熟悉程度。这就好比有些歌曲本身就比较流行,大多数人都能轻易哼出来,而有些冷门歌曲即使是音乐专家也可能不够熟悉。
为了公平评判,研究团队设计了一个基准测试:让AI在没有看到推理过程的情况下直接生成标准答案,以此作为基础难度。然后用带有推理过程的得分减去这个基础得分,得到的差值才是真正反映推理质量的奖励分数。这就像是在考试中根据题目的基础难度进行调整,确保评分的公平性。
第三个创新是训练稳定性的保障。在训练过程中,研究团队发现某些问题要么太简单(AI总是能轻易答对),要么太困难(AI总是答错),这两种情况都不利于AI的学习。这就像是一个学生如果总是做过于简单或过于困难的题目,学习效果都不会好。
为了解决这个问题,研究团队开发了一个动态筛选机制。他们会持续监控每道题目上AI答案的多样性。如果发现某道题的答案总是大同小异(标准差很小),就会暂时将这道题从训练集中移除。这样确保AI始终在适当难度的问题上进行训练,就像一个好老师会根据学生的水平调整作业难度一样。
实验验证的丰硕成果
为了验证RLPR方法的有效性,研究团队进行了大规模的对比实验,结果看起来很不错。
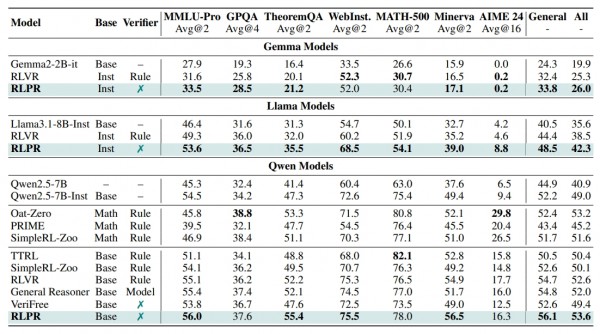
在数学推理方面,即使RLPR在训练时完全没有使用数学数据,它在数学基准测试上的表现仍然相当出色。在Minerva数学推理测试中,RLPR达到了56.5%的准确率,甚至超过了一些专门针对数学设计的方法。这就好比一个平时主要学习文科的学生,在数学考试中居然能够取得优异成绩,说明其掌握的是更加通用的思维能力。
在通用推理领域,RLPR的优势更加明显。在MMLU-Pro这个涵盖多个学科的综合测试中,RLPR达到了56.0%的准确率,比基础模型提升了约25%。在物理、化学等科学问题的GPQA测试中,准确率达到37.6%。在定理应用测试TheoremQA中,表现更是突出,达到55.4%的准确率。
特别值得一提的是,RLPR甚至超越了一些需要额外训练验证器模型的复杂方法。比如,相比于需要专门训练15亿参数验证器的General Reasoner方法,RLPR在七个测试基准的平均表现上还要高出1.6个百分点。这就像是一个自学成才的学生超越了有专业老师辅导的同学,充分体现了这种自我评估方法的强大威力。
为什么这种方法特别有效
研究团队通过深入分析发现,RLPR方法之所以效果卓越,有几个根本性的原因。
首先,这种方法能够更好地处理自然语言的复杂性和多样性。传统的规则验证器往往只能识别完全匹配的答案,但现实中正确答案可能有多种表达方式。比如说,对于氢气比氧气轻这个事实,可能的正确表述包括氢气密度小于氧气、氢气比氧气的重量轻等多种形式。规则验证器很难处理这种变化,但RLPR通过概率机制能够给予这些语义相似的答案合理的评分。
其次,这种方法与AI模型的内在工作机制更加契合。现代的大型语言模型本质上就是通过预测下一个词的概率来工作的,RLPR正是利用了这种天然的概率机制。就像是利用一个钢琴家的肌肉记忆来判断他对某首曲子的熟悉程度一样,RLPR利用AI的语言记忆来评估其对问题的理解深度。
第三,这种方法具有很好的通用性和扩展性。不像传统方法需要为每个新领域重新设计验证规则,RLPR可以无缝应用到任何有参考答案的问题上,从数学物理到人文社科,从技术文档到创意写作都能适用。
对不同规模模型的广泛适用性
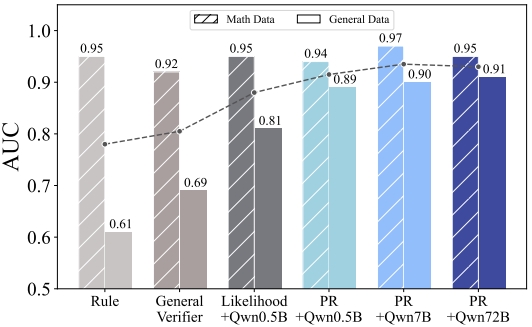
研究团队还测试了RLPR在不同规模AI模型上的表现,发现了一个有趣的规律。即使是相对较小的模型(如5亿参数的Qwen2.5-0.5B),使用RLPR方法的效果仍然超过了专门训练的验证器模型。这说明这种自我评估能力是AI模型的一种内在特质,不需要特别大的模型规模就能发挥作用。
在不同的模型家族(Qwen、Llama、Gemma)上的测试结果也都表明,RLPR方法具有很好的通用性。无论是中文为主的Qwen模型,还是英文为主的Llama和Gemma模型,都能从这种训练方法中受益,平均性能提升都在6个百分点以上。
方法的局限性和改进空间
虽然RLPR方法表现出色,但研究团队也诚实地指出了一些局限性。
首先,这种方法仍然需要有参考答案的训练数据。虽然不需要为每个领域专门设计验证器,但仍然需要人工标注的标准答案作为对比基准。这在某些全新的、探索性的问题上可能存在困难。
其次,概率分数作为奖励信号仍然会有一定的噪声。虽然研究团队通过多种技术手段减少了这种噪声,但完全消除是不可能的。这就像是利用直觉判断虽然通常很准确,但偶尔也会有误判的情况。
第三,在一些需要严格逻辑推理的场景下,概率评分可能不如精确的规则验证器那么可靠。比如在数学证明或者代码正确性检验中,差不多对和完全正确之间有着本质区别。
未来发展的广阔前景
尽管存在一些局限性,RLPR方法仍然为AI推理能力的提升开辟了一条全新的道路。这种方法的最大价值在于大大降低了将强化学习应用到新领域的门槛。
传统上,要让AI在一个新领域变聪明,研究者需要花费大量时间设计复杂的评估规则或者收集大量数据训练专门的验证器。现在,只要有基本的问答数据,就可以直接应用RLPR方法,这大大加速了AI技术在各个领域的应用进程。
更重要的是,这种方法启发我们重新思考AI学习的本质。也许最好的老师不是外部的评判者,而是学习者自己的内在理解。这种自我反思和自我评估的能力,可能是通向更加智能的AI系统的关键路径。
研究团队表示,他们正在将这种方法扩展到更多的应用场景,包括多模态理解(结合文本、图像、音频的综合理解)和更大规模的模型训练。随着技术的不断完善,我们有理由相信,AI在各个领域的推理能力都将迎来新的突破。
至顶AI实验室洞见
AI模型性能持续提升,离不开它的训练方法,尤其是强化学习方法的持续改良。
比如,早期RLHF(基于人类反馈的强化学习)是最受欢迎的训练方法,也是GPT3的核心算法之一。RLHF通过人类偏好来指导模型的学习过程。
后来,RLVR(基于可验证奖励的强化学习)受到Anthropic等AI头部公司青睐。RLVR不依赖人类指导,奖励来源于明确、可自动验证的标准或规则。
问题在于,RLHF需要大量人力对模型回答进行标注,成本高昂;RLVR通过规则将这个过程自动化,成本显著降低。虽然RLVR的规则适用于数学、代码等能应用规则验证答案的领域,但对于开放性问题,又表现平平。
论文中的数据显示,清华的RLPR很好地解决了RLVR的问题。可以预见的是,应用了清华RLPR训练方法的模型能在开放性问题上性能继续提升。
不管未来还有什么新算法,模型训练方法似乎已经从由人类指导往自我进化的方向越走越远。
论文地址:
https://www.arxiv.org/abs/2506.18254
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:RLPR是什么?它解决了什么问题?
A:RLPR是一种新的AI训练方法,全称是基于参考概率奖励的强化学习。它主要解决了传统AI训练方法只能在数学、编程等有标准答案的领域工作,而无法处理文科、社科等开放性问题的局限。RLPR让AI通过自己的语言直觉来评判答案质量,不需要外部验证器。
Q2:RLPR会不会取代传统的AI训练方法?
A:目前不会完全取代,而是提供了一个重要的补充选择。在数学、编程等有明确对错标准的领域,传统验证器仍然有其价值。但在文科、社科、创意等开放性领域,RLPR展现出明显优势。未来可能会形成针对不同应用场景选择最适合方法的格局。
Q3:普通人能使用RLPR训练自己的AI模型吗?
A:目前RLPR主要面向AI研究人员和开发者。普通用户还无法直接使用这种方法训练模型,因为需要相当的技术背景和计算资源。不过,随着技术成熟,未来可能会有更加用户友好的工具和平台,让更多人能够受益于这种先进的训练方法。
来源:至顶AI实验室
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2025
07/01
16:24
分享
点赞

数智时代,openGauss Summit 2025即将发布哪些技术创新破局
“算力+储能”深度融合:超智算发布分布式算力超级节点储能解决方案
联想推出DE6600系列:更智能的存储解决方案
创业公司如何在严格监管行业中实现生死攸关的创新
OpenAI发布GPT-5.2-Codex模型,软件工程自动化能力大幅提升
Waterfox浏览器宣布拒绝AI功能,瞄准Firefox忠实用户
TikTok美国业务出售交易将于下月完成
破局AI数据中心安全瓶颈:Fortinet联合NVIDIA引领隔离式加速新航向
智算中心进化论,科华数据如何做到“更懂”
更高负载、更快建设:2026年数据中心六大趋势
Snowflake数据库更新引发全球大规模服务中断
AI编程初创公司Lovable融资3.3亿美元,英伟达等科技巨头支持
