
Transformer时代终结?Mamba作者提出H-Net:端到端、无分词器 原创
Transformer架构作为当前大语言模型的主流架构,因为拥有特殊的注意力机制,存在输出长度较短的缺点。为了解决这个问题,业界提出RWKV、Mamba等解决方案。
其中,Albert Gu提出的Mamba架构受到广泛关注。Mamba是一个简化的端到端神经网络架构,无需注意力机制。最近Albert Gu又提出了一个新的端到端网络H-Net,无需分词器。
2025年7月10日,卡内基梅隆大学的Sukjun Hwang、Brandon Wang以及Albert Gu共同完成论文Dynamic Chunking for End-to-End Hierarchical Sequence Modeling,发表于arXiv。H-Net的模型代码和预训练检查点开源在Github和Hugging Face上。
机器读懂人类语言的翻译难题
现在的人工智能系统在处理文字时,就像一个需要翻译字典的外国人一样。它们无法直接理解原始的字母和文字,而是需要先把这些文字"翻译"成特殊的代码,这个过程就叫做"分词"。
以GPT这样的大语言模型为例,当你输入"我爱学习"这四个字时,系统并不是直接处理这些汉字,而是先用一本特殊的"字典"把这些字转换成数字代码,比如把"我"转换成编号1234,把"爱"转换成编号5678等等,然后才开始思考。这就像你想和一个外国朋友交流,但你们都不会对方的语言,只能依靠一本翻译词典来对话。
这种传统方法虽然被广泛使用,但存在许多问题。最明显的问题是翻译错误。比如"苹果公司"这个词,如果翻译字典把它拆分成"苹果"和"公司"两个部分,机器可能会误以为你在谈论水果生意。更严重的是,这种方法对不同语言极不公平。英语因为有天然的空格分隔,处理起来相对容易,但中文、日文这样没有空格的语言就吃了大亏。至于DNA序列或计算机代码这样的特殊语言,传统的翻译字典几乎完全派不上用场。
研究团队意识到,如果机器能够像人类一样直接理解原始文字,不需要任何翻译字典,那么这些问题都将迎刃而解。人类婴儿学会说话时,并不需要先学会分词,他们能够自然地理解语言的节奏和规律。机器为什么不能也这样做呢?
智能文本处理工厂的诞生
为了解决这个根本问题,研究团队设计了一个全新的系统,他们称之为H-Net(分层网络)。这个系统就像一个极其智能的文本处理工厂,能够直接处理最原始的字节数据,无需任何预处理的翻译步骤。
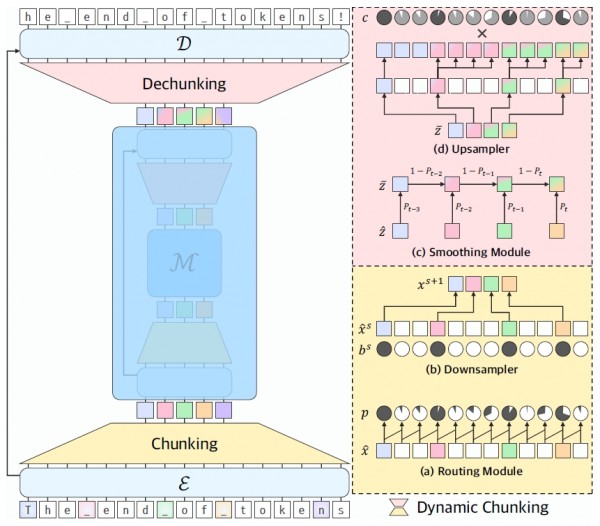
H-Net的核心创新在于它的动态分块机制。传统方法就像用固定长度的尺子来切割文本,无论内容如何都机械地按照预设规则分割。而H-Net则像一个经验丰富的师傅,能够根据文本内容的实际情况,智能地决定在哪里切一刀。它会仔细观察每个字符之间的关系,当发现意义发生转换的地方时,就在那里设置一个分割点。
H-Net采用了一种类似人类阅读习惯的方法。当你阅读一段文字时,你的大脑会自动识别出词与词之间、句子与句子之间的界限。H-Net也是如此,它通过计算相邻字符之间的相似度来判断是否应该在此处分割。如果两个相邻字符在语义上差别很大,那么它们之间很可能就是一个自然的分割点。
H-Net采用了层次化的处理结构。在第一层,它处理最基本的字符级别信息。在更高层次上,它处理更抽象的语义信息。这种层次化设计让H-Net能够同时处理细节和整体,既不会遗漏重要的细节信息,也不会被琐碎的信息所干扰。
革命性的平滑处理技术
H-Net面临的最大技术挑战是如何让机器在学习过程中不断改进自己的分割技巧。传统的机器学习就像教一个学生做数学题,每次做错了都能明确指出哪里错了,应该如何改正。但是分割决策是一个"是或否"的选择问题,就像开关一样,要么开要么关,没有中间状态。这种离散性质让机器很难通过常规方法学习改进。
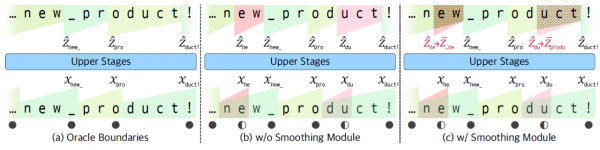
研究团队的解决方案相当巧妙,引入了"平滑模块"技术。这个模块就像一个智能的调节器,能够将硬性的"开关"决策转换为柔性的"调光器"。当H-Net对某个分割决策不太确定时,平滑模块不会强硬地做出绝对选择,而是根据置信度进行柔性处理。
具体来说,如果H-Net对某个位置应该分割的确信度是90%,那么平滑模块就会相应地调整处理强度。这种做法的妙处在于,它为机器学习提供了连续的改进空间。机器可以通过不断调整这些确信度来逐步改善自己的分割技巧,就像一个学徒通过反复练习来提高手艺一样。
平滑模块还具有自我纠错的能力。当系统发现某个分割决策可能不够理想时,它会自动融合周围的信息来进行补偿。这种自适应机制确保了即使在学习初期出现一些错误,也不会对整体效果造成严重影响。
多级智能处理的威力
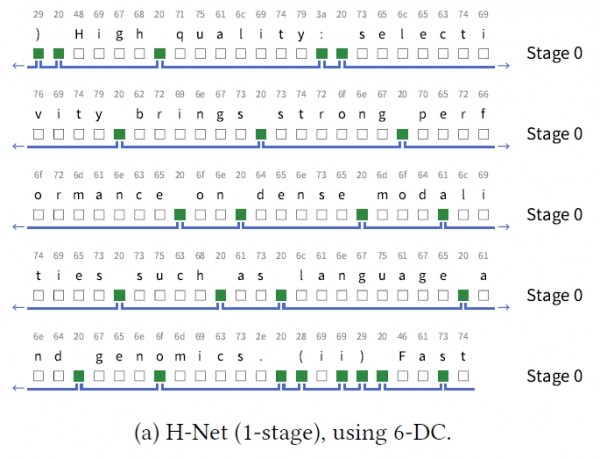
H-Net最令人印象深刻的特点是它的可扩展性。研究团队发现,H-Net可以像搭积木一样层层叠叠,构建出多级处理系统。一级H-Net能够处理字符级别的分割,二级H-Net则可以在一级的基础上进行更高级的语义分割,就像从字母组成单词,再从单词组成句子一样。
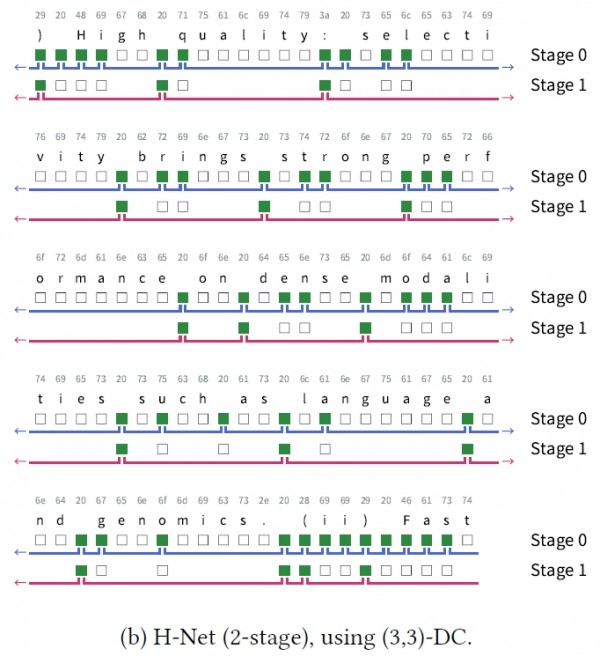
在实际测试中,二级H-Net展现出了惊人的能力。它不仅能够准确识别单词边界,还能理解更复杂的语义结构。比如在处理"这样的例子"这个短语时,一级H-Net可能会在每个字之间都设置分割点,而二级H-Net则能够智能地将"这样的"识别为一个完整的修饰语单元,将"例子"识别为被修饰的名词,从而实现更加合理的分割。
这种多级处理的优势在处理复杂语言时尤为明显。在中文处理中,二级H-Net能够同时考虑字符级别和词汇级别的信息,准确率显著提升。在处理编程代码时,它能够理解代码的层次结构,将相关的代码块正确地归组在一起。在DNA序列分析中,它能够识别出具有生物学意义的功能片段,这是传统方法难以做到的。
实战测试中的卓越表现
研究团队在多个实际场景中测试了H-Net的性能,结果令人瞩目。在标准的英语文本处理任务中,仅使用一级动态分块的字节级H-Net就能够匹配强大的BPE分词Transformer模型的性能,而这个Transformer模型的参数量超过10亿个。当使用二级H-Net时,性能提升更加显著,训练仅进行300亿字节后就超越了传统的分词模型,而且这个性能差距还在持续扩大。

在处理中文文本时,H-Net的优势更加明显。由于中文没有天然的空格分隔,传统的分词方法经常出错,而H-Net能够通过学习汉字之间的语义关系来准确分割。在XWinograd中文语言理解测试中,H-Net的准确率从59.9%提升到了66.3%,这是一个相当显著的改进。
编程代码是另一个H-Net大放异彩的领域。代码具有严格的语法结构和层次关系,传统分词方法很难准确理解这些结构。H-Net通过学习代码的语法模式,能够将功能相关的代码片段合理地组织在一起,大大提高了代码理解的准确性。
最令人惊讶的是H-Net在DNA序列分析中的表现。DNA序列被称为生命的密码,它没有任何人工设计的分割规则,完全依靠生物学规律。H-Net竟然能够从原始的DNA序列中学会识别具有生物学意义的功能单元,这展现了它强大的模式识别能力。在人类基因组数据集HG38上,H-Net的数据效率比传统方法提高了3.6倍,这意味着它只需要不到三分之一的训练数据就能达到相同的效果。
抗干扰能力的意外惊喜
在测试过程中,研究团队还发现了H-Net的一个意外优势:强大的抗干扰能力。他们故意在测试文本中加入各种扰动,比如删除一些空格、改变字母大小写、重复某些字符等,然后观察不同系统的表现。
结果显示,传统的分词系统在面对这些扰动时表现急剧下降,就像一个严重依赖GPS导航的司机在信号干扰时完全迷失方向。而H-Net由于直接处理原始字符,对这些扰动具有天然的抵抗力。即使文本被故意"破坏",H-Net仍然能够通过上下文信息和字符关系来正确理解文本内容。
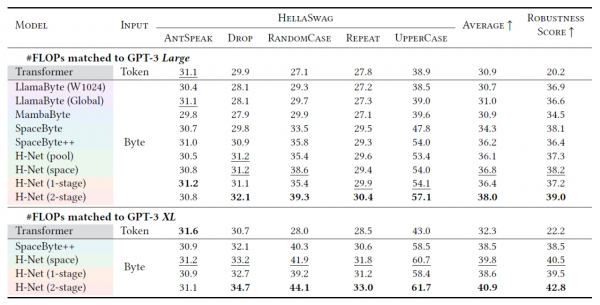
这种抗干扰能力在实际应用中非常有价值。网络上的文本经常包含拼写错误、格式问题或恶意扰动,传统系统在处理这些"不完美"文本时往往力不从心。H-Net的鲁棒性让它能够在更复杂的真实环境中稳定工作。
智能边界识别的可视化发现
研究团队通过可视化分析发现,H-Net确实学会了识别语言中的自然边界。
第一层分割倾向于在空格和单词开头字符设置边界,这类似于人类阅读时的视觉扫描模式。第二层分割则更关注语义单元,会将"such as"(比如)、"the backbone"(主干)这样具有整体含义的短语作为完整单元处理。这种层次化的理解方式与人类的语言认知过程非常相似。
即使在故意删除空格的扰动文本中,H-Net仍然能够准确识别原本的单词边界。这表明它学到的不仅仅是表面的格式规则,而是深层的语义关系。这种能力让H-Net能够处理各种非标准格式的文本,大大扩展了应用范围。
计算效率的巧妙平衡
H-Net的设计还体现了研究团队在计算效率方面的深思熟虑。整个系统采用了类似U型网络的架构,将大部分计算资源集中在处理压缩后序列的主网络上。编码器和解码器虽然处理原始长度的序列,但使用了参数较少的高效架构。
这种设计的巧妙之处在于它实现了计算负担的最优分配。编码器负责将长序列压缩成短序列,解码器负责将短序列恢复成长序列,而真正的智慧集中在处理短序列的主网络中。这就像一个高效的生产流水线,预处理和后处理使用简单设备,而核心加工使用最精密的机器。
研究团队还引入了学习率调制技术,为不同层次的网络设置不同的学习速度。由于外层网络处理更长的序列,它们需要更快的学习速度来及时调整分割策略。内层网络处理压缩后的表示,可以使用较慢的学习速度来稳定优化。这种精细的调节确保了整个系统的协调发展。
至顶AI实验室洞见
H-Net的出现预示了人工智能发展的一个新趋势:从依赖人工设计的预处理步骤转向端到端的自动学习。这种转变类似于从手工制作到工业自动化的变革,不仅提高了效率,还释放了更大的潜力。
在特殊领域应用方面,H-Net为生物信息学、代码分析等领域开辟了新的可能性。这些领域的数据往往具有独特的结构和规律,传统的通用分词方法难以胜任。H-Net的自适应学习能力让它能够自动发现这些领域特定的模式,为专业应用提供了更好的基础。
从技术演进的角度看,H-Net体现了深度学习"端到端"优化的理念。这种方法让整个系统作为一个整体进行优化,而不是将不同组件分别优化后再组合。
H-Net让机器从"翻译式理解"进化到了"直觉式理解",这种变化可能会带来更自然、更智能的人机交互体验。未来的AI系统可能会更好地理解人类语言的细腻之处,包括语调、语境和潜在含义,让AI助手变得更加贴心和实用。
论文地址:
https://www.arxiv.org/abs/2507.07955
Q&A
Q1:卡内基梅隆大学的动态分块技术是什么?
A:动态分块技术由卡内基梅隆大学和CartesiaAI开发,允许AI语言模型自动学习文本分割,无需固定规则。它使用路由模块分析内容相似性来决定分割点,以及平滑模块确保训练稳定。该技术提高灵活性,适用于中文、代码等数据类型。
Q2:H-Net架构如何改善AI语言模型?
A:H-Net架构采用分层设计:编码器处理原始字节数据,主网络处理压缩信息块,解码器还原输出。多级分层(如一级或二级)提升数据效率,二级H-Net只需300亿字节训练数据就能超越传统模型,并改善多语言及长文本处理。
Q3:动态分块在中文AI处理上有什么优势?
A:动态分块解决中文无空格分隔问题,避免错误分割(如将“苹果公司”误切)。它提高中文理解任务得分,从59.9到66.3,并增强抗干扰能力,面对拼写错误时性能更稳健。
来源:至顶AI实验室
好文章,需要你的鼓励


英特尔复苏进行中,代工业务成为关注焦点
英特尔第三季度财报超华尔街预期,净收入达41亿美元。公司通过裁员等成本削减措施及软银、英伟达和美国政府的大额投资实现复苏。第三季度资产负债表增加200亿美元,营收增长至137亿美元。尽管财务表现强劲,但代工业务的未来发展策略仍不明朗,该业务一直表现不佳且面临政府投资条件限制。

认知科学研究院首次发现:进化策略竟能超越强化学习训练大语言模型
美国认知科学研究院团队首次成功将进化策略扩展到数十亿参数的大语言模型微调,在多项测试中全面超越传统强化学习方法。该技术仅需20%的训练样本就能达到同等效果,且表现更稳定,为AI训练开辟了全新路径。

微软为Copilot推出Mico虚拟角色及新增自动化协作功能
微软发布新版Copilot人工智能助手,支持最多32人同时参与聊天会话的Groups功能,并新增连接器可访问OneDrive、Outlook、Gmail等多项服务。助手记忆功能得到增强,可保存用户信息供未来使用。界面新增名为Mico的AI角色,并提供"真实对话"模式生成更机智回应。医疗研究功能也得到改进,可基于哈佛健康等可靠来源提供答案。同时推出内置于Edge浏览器的Copilot Actions功能,可自动执行退订邮件、预订餐厅等任务。

当机器学会“热眼看世界“:纽约大学等联合团队让AI精通“热感翻译术“
纽约大学等机构联合开发的ThermalGen系统能够将普通彩色照片智能转换为对应的热成像图片,解决了热成像数据稀缺昂贵的难题。该系统采用创新的流匹配生成模型和风格解耦机制,能适应从卫星到地面的多种拍摄场景,在各类测试中表现优异。研究团队还贡献了三个大规模新数据集,并计划开源全部技术资源,为搜救、建筑检测、自动驾驶等领域提供强有力的技术支撑。
2025
07/14
17:37
分享
点赞

Unity中国携手腾讯广告,让中小开发者告别“碰运气”
Unity团结引擎发布三大战略 极速提升渲染效能
Unity开发者大会Unite2025点亮上海,团结引擎加速本土创新落地
阿里夸克“C计划”再曝新动向:一款AI浏览器或年底发布
英特尔复苏进行中,代工业务成为关注焦点
微软为Copilot推出Mico虚拟角色及新增自动化协作功能
Google与Anthropic签署百亿TPU合作协议推进AI发展
EA与Stable Diffusion背后公司合作,用AI制作游戏
英特尔称服务器CPU将重新火热:AI工作负载推动增长
提示工程正在深入探索最新发布的ChatGPT工作效率提升提示包
NRG能源如何通过技术创新重塑传统电力行业
CIO将承担业务主导AI项目失败的收拾责任
