
阿里团队突破多角色动画难题:FantasyPortrait让静态照片开口说话更自然 原创
考虑这样一个场景,在你手机里躺着无数张静态照片,突然有一天它们都能像电影里的魔法画像一样动起来,不仅能眨眼微笑,还能跟着你提供的参考视频做出各种生动表情。更神奇的是,一张合影里的每个人都能独立地做出不同动作,而不会互相干扰。这听起来像科幻电影情节,但阿里研究团队已经把它变成了现实。
传统的人像动画技术就像给雕像穿衣服一样笨拙。它们依赖面部关键点和3D面部模型这些"硬性模板"来驱动表情变化,就好比用固定的钢丝框架来操控木偶。这种方法在处理相同人脸时还算凑合,但当你想让一个亚洲面孔模仿欧洲人的表情时,就会出现严重的"水土不服"——面部扭曲、动作僵硬、背景闪烁等各种问题接踵而至。更要命的是,这些传统方法完全无法处理多人动画场景,因为不同人的特征会相互"串台",就像收音机调频不准时会收到好几个电台的声音混在一起。
阿里团队面对的挑战就像同时指挥一个交响乐团,每个乐手(角色)都要演奏不同的曲子,却要保持整体和谐。传统技术就像用同一根指挥棒试图控制所有乐手,结果自然是一团糟。研究团队需要找到一种既能让每个"乐手"独立演奏,又能保证整体协调的全新方法。
FantasyPortrait这个名字本身就透露着研究团队的雄心——不仅要让肖像动起来,还要让它们像幻想世界里的魔法画像一样栩栩如生。这套系统的核心创新在于三个关键突破:首先是"表情增强学习策略",其次是"掩码交叉注意力机制",最后是专门构建的多角色表情数据集和评估基准。
表情的隐式密码:从几何约束到情感理解
传统的人像动画技术就像考古学家复原古代雕像,需要依靠精确的测量数据和几何模型。而FantasyPortrait采用的方法更像一位敏感的心理学家,它不再拘泥于面部的几何结构,而是学会了理解表情背后的情感内涵。

研究团队设计的"隐式表情表示"系统就像一个情感翻译器。当系统观看驱动视频时,它不是简单地记录"嘴角上扬15度"或"眉毛抬高8毫米"这样的机械数据,而是提取出更深层的表情密码:唇部的运动节奏、眼神的情感流向、头部姿态的自然韵律,以及最关键的情感表达模式。
这种方法的巧妙之处在于,它将人脸表情的复杂性进行了智能分层。简单的动作如眨眼和转头,由于遵循较为固定的物理规律,相对容易掌握。而复杂的情感表达如微笑中的细微变化、愤怒时的肌肉紧张状态等,则需要更加精细的理解和建模。
为了解决这个分层问题,研究团队提出了"表情增强学习策略"。这个策略就像培养一位专业演员,让系统重点练习那些最难掌握的表演技巧。具体来说,对于嘴部动作和情感表达这两个最具挑战性的部分,系统会使用专门的"可学习标记"进行精细分解,每个标记负责理解特定的肌肉群或情感维度。
这些精细化的特征随后会通过多头交叉注意力机制与视频中的语义信息进行深度交互,就像一位演员在理解剧本后,将内心的情感转化为具体的面部表情。通过这种方式,系统不仅能够准确再现参考视频中的表情变化,还能在不同身份之间实现更加自然的表情迁移。
多角色协调的艺术:掩码注意力的精妙平衡
当画面中出现多个角色时,挑战就像同时操控几个提线木偶——每个木偶都有自己的表演任务,但操作线缆却可能相互缠绕。传统技术在这种情况下往往会出现"表情泄露"现象,就是一个角色的笑容意外地传染给了另一个本该保持严肃的角色。
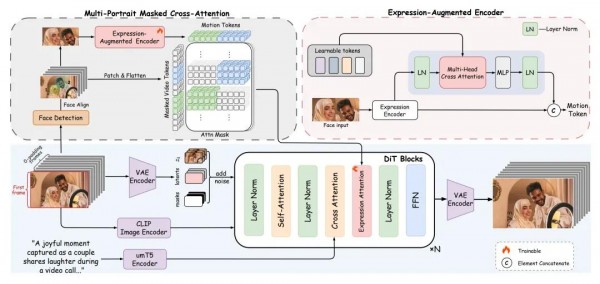
FantasyPortrait通过"掩码交叉注意力机制"解决了这个难题。这个机制的工作原理就像给每个角色分配了一个专属的"表情频道"。系统首先会识别画面中每个人物的面部区域,然后为每个区域生成对应的掩码映射。这些掩码就像隐形的边界线,确保每个角色的表情特征只在其专属区域内发挥作用。
具体的实现过程颇为精巧。系统会从驱动视频中提取每个角色的面部掩码,然后使用三线性插值将这些掩码映射到潜在空间中。在这个潜在空间里,多角色的动作嵌入会通过专门设计的交叉注意力层与预训练的扩散变换器的每个块进行交互。关键在于,注意力的计算过程中加入了掩码约束,这样就能确保每个角色的表情驱动信号只影响画面中对应的人物区域。
这种设计的巧妙之处在于既保证了角色间的独立性,又维持了整体画面的协调性。就像一场精心编排的舞蹈表演,每个舞者都有自己的动作序列,但整体上又形成了和谐统一的视觉效果。实验结果显示,没有这个掩码机制的系统在处理多角色场景时会出现严重的相互干扰,导致表情混乱和视觉违和感。
技术架构的深度解析:从输入到输出的完整流程
FantasyPortrait的整体架构就像一个高度精密的表情工厂,输入端是静态肖像和参考动作视频,输出端是流畅自然的动画效果。这个"工厂"的生产流水线包含几个关键环节。
首先是原料处理阶段。系统使用预训练的变分自编码器(VAE)将输入的视频数据从像素空间转换到潜在空间,这一步就像将复杂的三维雕塑投影成二维蓝图,既保留了关键信息又便于后续处理。在训练过程中,系统会向这些潜在表示中逐步添加高斯噪声,然后学习逆向去噪的过程,这种方法能够让模型更好地理解和生成高质量的视频内容。
接下来是特征提取和处理阶段。系统会使用人脸检测算法定位和对齐面部区域,然后通过预训练的隐式表情提取器获得身份无关的表情特征。这些特征被分解为四个主要组成部分:唇部运动、眼部注视和眨眼、头部姿态,以及情感表达。每个组成部分都承载着不同层面的表情信息,为后续的精细化控制奠定基础。
核心处理阶段是表情增强学习模块的工作。对于那些复杂的非刚性运动(主要是情感表达和唇部运动),系统会使用可学习的标记进行精细分解和增强。这些标记通过多头交叉注意力机制与视频标记进行交互,能够捕获区域特定的语义关系。处理完成后,增强的特征会与相对简单的头部姿态和眼部运动特征进行融合,形成最终的运动嵌入。
对于多角色场景,系统会为每个角色单独提取运动嵌入,然后将它们沿着长度维度进行连接,形成综合的多角色运动特征。这些特征随后通过掩码交叉注意力机制与扩散变换器的各个层级进行交互,确保每个角色的表情控制既精确又独立。
最后的生成阶段采用了最先进的扩散变换器架构。与传统的U-Net结构不同,这种基于变换器的设计能够更好地处理序列建模任务,特别是在视频生成方面表现出色。系统使用了因果3D VAE进行时空压缩,同时整合了多语言文本编码器来处理文本条件输入。
整个推理过程采用30步采样策略,通过分类器无关引导机制来平衡生成质量和多样性。研究团队将表情特征的引导尺度设置为4.5,这个参数是通过大量实验优化得出的最佳平衡点。
数据集构建:为多角色动画奠定基础
要训练一个能够处理多角色动画的系统,首先需要解决数据稀缺的问题。目前公开可用的多人表情视频数据集几乎是空白,这就像想要学习指挥交响乐却找不到合适的乐谱一样困难。

研究团队从OpenVid-1M和OpenHumanVid这两个大型视频数据库中筛选构建了Multi-Expr数据集。整个数据处理流程就像淘金一样精细:首先使用YOLOv8检测器识别每个视频片段中的人物数量,只保留包含两人或更多人物的片段;然后通过美学评分和拉普拉斯算子过滤掉低质量、模糊或有瑕疵的内容;最后利用MediaPipe检测的面部关键点计算关键面部区域的角度和运动变化,选择出具有清晰表达性面部运动的片段。
经过这道道筛选工序,最终的Multi-Expr数据集包含约30000个高质量视频片段,每个片段都配有CogVLM2生成的描述性标注。这些标注不仅描述了画面内容,还捕捉了情感和表情的细微变化,为训练提供了丰富的语义信息。
除了训练数据集,团队还构建了ExprBench评估基准,这是首个专门针对表情驱动视频生成的标准化评估体系。ExprBench分为单人和多人两个子集:ExprBench-Single包含200张肖像图片和100个驱动视频,ExprBench-Multi包含100张肖像图片和50个驱动视频。
这些评估素材涵盖了极其丰富的场景:从真实人物到拟人化动物,从卡通角色到各种风格化头像;从录音棚、表演舞台到直播间等不同环境;从眼皮下垂、眉毛抽动等细微表情到快乐、悲伤、愤怒等强烈情感。每个驱动视频都经过精心剪辑,长度约5秒,包含大约125帧,确保有足够的表情变化信息用于测试。
实验验证:全方位性能评估
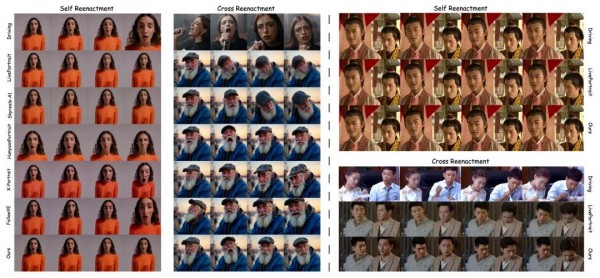
为了验证FantasyPortrait的效果,研究团队设计了一套全面的评估体系,就像给新药做临床试验一样严格。他们选择了多个当前最先进的人像动画方法作为对比基准,包括LivePortrait、Skyreels-A1、HunyuanPortrait、X-Portrait和Follow-Your-Emoji等。

定量评估采用了多个维度的指标。在视频质量方面,使用FID(Fréchet Inception Distance)和FVD(Fréchet Video Distance)来评估生成视频的整体质量和真实感;在重建精度方面,采用PSNR(峰值信噪比)和SSIM(结构相似性)来衡量生成结果与原始视频的相似程度;在动作准确性方面,使用LMD(地标平均距离)评估表情动作的精确性,使用MAE(平均角度误差)评估眼部运动的准确性。
对于跨身份重现这个最具挑战性的场景,团队使用了AED(平均表情距离)、APD(平均姿态距离)和MAE来分别评估表情迁移、头部姿态控制和眼部运动的准确性。这些指标就像体检报告中的各项数值,从不同角度反映系统的健康状况。
实验结果令人振奋。在所有关键指标上,FantasyPortrait都取得了最佳成绩。特别是在表情和头部运动相似性指标(LMD、MAE、AED和APD)上,改进幅度尤为显著。这些数据证明了隐式表情表示结合表情增强学习确实能够更有效地捕捉细致的面部表情和情感动态,同时保持卓越的跨身份迁移能力。
在多角色实验中,系统同样表现出色,验证了掩码交叉注意力机制能够实现对多个角色的稳健而精确的控制。基于传统方法的LivePortrait在处理多角色场景时出现了明显的不连续性,就像拼图游戏中强行拼接不匹配的碎片一样违和。
定性评估的结果更加直观地展示了技术优势。在单角色场景中,即使驱动视频包含显著的摄像机运动和身体姿态变化等干扰因素,FantasyPortrait仍能保持出色的视觉质量,而其他基准方法在这种干扰下会出现明显的瑕疵和错误表情。在多角色场景中,传统方法容易在不同角色的驱动区域和静态背景区域之间产生明显的不连续性,而FantasyPortrait通过在潜在空间中进行掩码交叉注意力处理,能够更自然地整合来自不同身份的表情特征。
深度解析:为什么这套方法如此有效
为了彻底理解FantasyPortrait成功的原因,研究团队进行了详尽的消融实验,就像拆解一台精密机器来研究每个零件的作用一样。
表情增强学习模块的验证实验揭示了一个重要发现:并非所有类型的面部运动都需要同等程度的增强处理。研究团队比较了三种配置:完全不使用增强学习、对所有特征都使用增强学习,以及只对唇部和情感特征使用增强学习的选择性方案。
结果显示,缺少增强学习会显著降低AED分数,说明精细表情学习能力受损。有趣的是,APD和MAE指标在各种配置下都保持相对稳定,这表明头部姿态和眼部运动遵循更加刚性、易于学习的运动模式,增强学习对这些刚性运动的改善作用有限。但对于唇部运动和情感动态这些复杂的非刚性运动,没有增强学习时性能下降就变得明显。
这个发现验证了研究团队选择性应用增强学习的设计理念:全面增强对刚性运动几乎没有益处,还会不必要地增加计算复杂度,而针对性的增强能够在保持效率的同时显著提升关键部分的性能。
掩码交叉注意力机制的重要性在多角色应用中得到了充分体现。实验结果表明,没有这个机制时,多个个体的面部驱动特征会相互干扰,导致所有评估指标大幅下降。更直观的视觉结果显示,缺少掩码注意力会导致角色间的面部表情相互干扰,产生冲突的输出,几乎完全消除了模型跟随驱动视频的能力。相比之下,精心设计的掩码交叉注意力机制有效地让模型能够独立控制不同的个体。
多表情数据集的作用也得到了验证。实验显示,仅在单肖像数据集上训练对单肖像动画保持了相当的性能,但在多肖像场景中会导致大幅性能下降,甚至出现视觉瑕疵。这表明虽然多表情数据集对单肖像动画可能不那么关键,但对于在复杂多肖像动画任务中取得高质量结果来说是不可或缺的,这有助于模型获得跨多个个体的细致面部表情表示能力。
技术局限与未来展望
任何技术创新都不是完美无缺的,FantasyPortrait也有其局限性。研究团队诚实地指出了两个主要限制。
首先是计算效率问题。扩散模型需要的迭代采样过程就像精工细作的手工艺品制作,虽然能产生高质量结果,但相对较慢的生成速度可能会限制实时应用。目前系统需要30步采样才能生成最佳效果,这在实时视频通话或直播场景中可能不够流畅。未来的研究方向包括探索加速策略,比如知识蒸馏、采样步数优化等技术来提高计算效率。
其次是伦理和安全考量。高保真度的肖像动画技术虽然有广泛的正面应用前景,但也存在被恶意使用的风险,比如制作虚假视频进行欺诈或传播不实信息。研究团队强调需要开发强大的检测和防御机制来减轻这项技术可能带来的伦理风险。这包括数字水印技术、真伪检测算法,以及相关的法律法规建设。
从技术发展角度看,FantasyPortrait代表了人像动画技术的一个重要里程碑,但距离完美还有很长的路要走。未来的改进方向可能包括更高的时间分辨率、更精细的表情控制、更强的个性化适应能力,以及与其他模态(如语音、文本)的更好整合。
另一个有趣的发展方向是如何将这项技术扩展到更大规模的场景,比如群体动画、虚拟演唱会等应用。随着计算能力的提升和算法的优化,我们可能很快就能看到这些更加宏大的应用场景。
至顶AI实验室洞见
FantasyPortrait不仅仅是一项技术突破,更是人工智能在理解和生成人类表情方面的重要进步。它让静态的照片拥有了生命力,让远程交流变得更加生动,让创意表达有了新的可能性。
虽然当前还存在一些技术限制,但这项研究为未来的多媒体技术发展指明了一个充满希望的方向。对于普通用户来说,这意味着不久的将来,我们可能会看到更加智能和自然的视频通话体验、更加生动的数字人助手,以及前所未有的创意内容制作工具。这项研究证明了科技确实在让我们的数字世界变得更加丰富多彩和富有表现力。
论文地址:
https://arxiv.org/pdf/2507.12956
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:FantasyPortrait与传统人像动画技术的最大区别是什么?
A:最大区别在于FantasyPortrait使用隐式表情表示而非传统的几何模型。传统方法像用固定模板操控木偶,而FantasyPortrait更像理解情感内涵的心理学家,能够更自然地处理跨身份表情迁移,避免面部扭曲等问题。
Q2:FantasyPortrait技术能处理多少个角色同时动画?会不会出现表情串台?
A:技术上可以处理多个角色,通过掩码交叉注意力机制确保每个角色独立控制。研究团队测试了双人场景并取得良好效果,理论上可扩展到更多角色。掩码机制有效防止了表情串台现象。
Q3:FantasyPortrait生成的视频质量如何?能用于商业应用吗?
A:在多项评估指标上都达到了当前最佳水平,特别是表情精度和视觉质量方面显著超越现有方法。不过由于采样速度较慢,目前更适合离线制作而非实时应用。随着算法优化,未来有望满足更多商业场景需求。
来源:业界供稿
好文章,需要你的鼓励


AI编程智能体工作原理及使用注意事项
OpenAI、Anthropic和Google的AI代码助手现在能够在人工监督下连续工作数小时,编写完整应用、运行测试并修复错误。但这些工具并非万能,可能会让软件项目变得复杂。AI代码助手的核心是大语言模型,通过多个LLM协作完成任务。由于存在上下文限制和"注意力预算"问题,系统采用上下文压缩和多代理架构来应对。使用时需要良好的软件开发实践,避免"氛围编程",确保代码质量和安全性。研究显示经验丰富的开发者使用AI工具可能反而效率降低。

从流水线到智能大脑:AI智能体如何学会自主思考、使用工具和记忆信息
这项研究由北京交通大学研究团队完成,系统阐述了人工智能智能体从"流水线"范式向"模型原生"范式的转变。研究表明,通过强化学习,AI可以自主学会规划、使用工具和管理记忆等核心能力,而不再依赖外部脚本。论文详细分析了这一范式转变如何重塑深度研究助手和GUI智能体等实际应用,并探讨了未来多智能体协作和自我反思等新兴能力的发展方向。

英伟达与AI芯片竞争对手Groq达成授权协议并聘用其CEO
英伟达与AI芯片竞争对手Groq达成非独家授权协议,将聘请Groq创始人乔纳森·罗斯、总裁桑尼·马德拉等员工。据CNBC报道,英伟达以200亿美元收购Groq资产,但英伟达澄清这并非公司收购。Groq开发的LPU语言处理单元声称运行大语言模型速度快10倍,能耗仅为十分之一。该公司今年9月融资7.5亿美元,估值69亿美元,为超200万开发者的AI应用提供支持。

Prime Intellect团队发布开源训练全栈:INTELLECT-3模型超越多数大型前沿模型
Prime Intellect团队发布开源AI训练全栈INTELLECT-3,这个106亿参数模型在数学、编程等测试中超越多个大型前沿模型。团队完全开源了包括prime-rl训练框架、环境库、代码执行系统在内的完整基础设施,为AI研究社区提供了高质量的训练工具,推动AI技术民主化发展。

