
AI教父弗里·辛顿学术讲座:AI正在以我们想象不到的方式变得比人类更聪明 原创
昨天的上海世界人工智能大会,辛顿首度访华,做了一系列讲座和对话。不过由于日程密集,很多观点谈到了,但是未来得及展开。

巧合的是,就在本月——辛顿出发之前,他在7月同时接受了英国皇家学会(Royal Institution)邀请,做了一个专场学术讲座,对"AI会超越人类智能吗?"这个主题进行了详细阐述,我觉得可以和上海的发言做一个有效补充。
再重复一下辛顿的履历(虽然其实应该根本不用了),他是多伦多大学荣誉教授,深度学习领域的世界级专家。他因"在人工神经网络机器学习方面的基础性发现和发明"而获得2024年诺贝尔物理学奖。作为英国皇家学会和加拿大皇家学会院士,他还获得了图灵奖、皇家学会皇家奖章等众多荣誉。辛顿1970年在剑桥大学获得实验心理学学士学位,1978年在爱丁堡大学获得人工智能博士学位。在经历了萨塞克斯大学和加州大学圣地亚哥分校的博士后工作后,他先后在卡内基梅隆大学和多伦多大学任教,并曾在伦敦大学学院创立了盖茨比计算神经科学部门。
2023年初,他从谷歌辞职,开始公开警告AI可能带来的生存风险。在这次演讲中,他系统地解释了为什么他认为数字智能将不可避免地超越人类,以及这种超越可能带来的影响。
一、两种智能范式的历史对立
辛顿以AI发展史上两种根本对立的范式开场。他指出,长期以来,智能研究存在两条截然不同的道路。

第一条是逻辑启发的方法,这就是传统意义上的AI。这一派认为人类智能的本质是推理,要理解智能就必须理解推理。推理被定义为拥有符号表达式并用符号规则来操纵它们。这一派认为学习可以等到以后再说,首先要理解如何用符号表达式来表示知识。"直到最近,AI的大部分历史都是这样的,"辛顿说。
第二条是生物学启发的方法,认为智能的本质是在神经元网络中学习——在人类是真实的神经元,在计算机中是模拟的神经元。这一派认为推理可以等到以后,首先要理解学习是如何工作的。辛顿特别提到了图灵和冯·诺依曼是这一方法的早期支持者,"你不能指责他们不懂逻辑。"
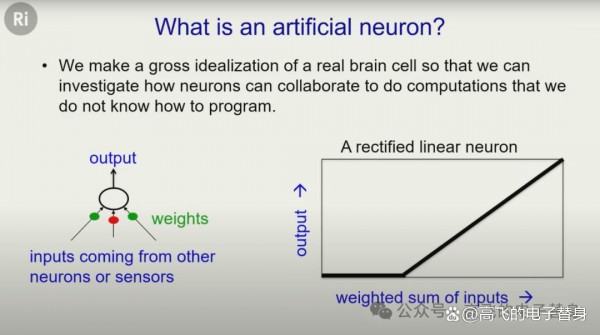
辛顿解释了人工神经元的基本工作原理:它有一些输入线(通常来自其他神经元),在这些输入线上有权重,它将输入乘以权重,全部加起来,然后给出输出。"如果超过阈值,它就会给出线性增加的输出。学习的方式就是改变这些连接上的权重。"
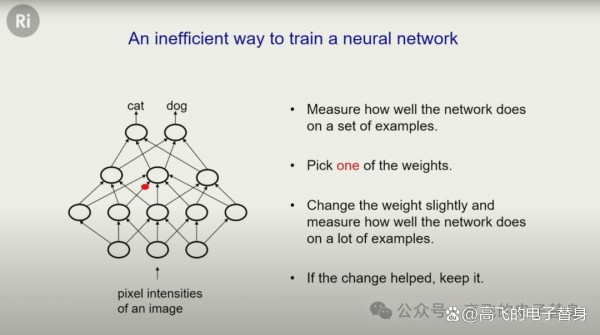
关于如何训练神经网络,辛顿介绍了两种方法。第一种是进化式的方法:改变一个权重,看看网络在一堆例子上的表现如何,如果表现更好就保留这个改变。但这种方法效率极低,因为现代神经网络有大约一万亿个权重。
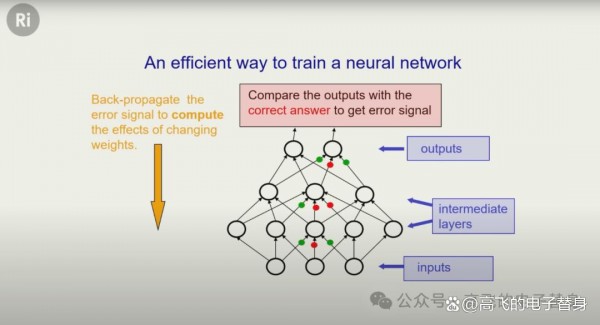
更好的方法是反向传播算法。"更好的方法是反向传播算法。你把数据从网络底层输入,逐层向前计算,得到输出结果(比如判断是猫还是狗的概率),然后与正确答案比较。接下来,算法会从输出层开始,逐层向后传递误差信号。通过微积分方法,网络可以同时计算出每个连接应该如何调整——是该加强还是减弱——才能让预测更准确。"
辛顿强调,这个相对简单的算法效果极好,但人们花了很长时间才意识到这一点。2012年,他的两个学生亚历克斯·克里热夫斯基(Alex Krizhevsky)和伊利亚·苏茨克维(Ilya Sutskever)——后者因解雇山姆·奥特曼而出名——开发了AlexNet,在识别图像中的物体方面远超现有的计算机视觉系统。"这打开了闸门。在那之前,神经网络在很多方面都很好,包括语音识别,但它们还没有真正占据主导地位。从那时起,它们真正接管了一切。现在当你说AI时,人们指的就是神经网络,而不是逻辑。"

二、语言学家的傲慢 神经网络的胜利

辛顿接着将矛头指向了语言学界,特别是乔姆斯基学派。"有一整个研究语言的社区,我想他们被称为语言学家。他们对如何研究语言有非常强烈的想法,特别是乔姆斯基学派。他们非常怀疑神经网络能够处理语言。他们完全相信这一切都是关于符号表达式的。"
辛顿批评语言学家没有真正理解语言的功能:"他们没有真正理解到语言的真正功能是给你词汇,这些词汇是你可以用来建立模型的积木。语言是一种建模媒介。他们专注于句法,而句法不是重点。重点是语言是构建特定类型复杂模型的绝妙方式。"
更让辛顿不满的是,"他们还认为语言知识是天生的,句法知识是天生的,这简直是愚蠢的。这是一个邪教的标志——为了加入这个邪教,你必须相信一些明显愚蠢的东西,比如语言不是学来的。"
辛顿随后介绍了两种截然不同的词义理论。符号AI理论认为,一个词的意义与它和其他词的关系有关,你不能在不谈论其他词的情况下单独定义它。因此,要捕捉意义,我们需要类似关系图的东西。
而心理学家从1930年代开始认为,一个词的意义是一大组特征。"比如'星期二'有一大组活跃的特征,'星期三'也有一大组几乎相同的活跃特征。"这种将词义视为一组活跃特征的想法,非常适合判断哪些词与哪些其他词有相似的含义。

"这看起来像是两种非常不同的意义理论,"辛顿说,"现在我想向你展示,这两种理论可以统一起来。它们不是两种不同的理论,而是同一理论的两个部分。"
三、1985年的小模型:大语言模型的始祖
辛顿花了相当长的时间介绍他在1985年开发的一个微小神经网络,这个网络只有几千个连接和几十个神经元。"我开发它是为了理解人们如何学习词的含义。我对它如何统一这两种意义理论感到非常兴奋,但其他人都不感兴趣。"
这个小模型的核心思想是学习如何让一个词的特征预测句子中下一个词的特征。一旦知道了下一个词的特征,就可以预测下一个词。"我们不会存储任何句子。很多人说大型聊天机器人只是在重复内容。大型聊天机器人实际上根本不存储任何语言。它们不存储词串。它们只存储如何将词转换为特征,以及特征应该如何相互作用来预测下一个词的特征。这就是这些聊天机器人中的全部内容。没有词。当它们想要生成一个句子时,它们必须边走边编。它们通常无法判断这是真实的还是虚构的。"
辛顿选择的例子是两个家谱:一个英国家谱和一个意大利家谱。它们是同构的,这有助于学习。他想让一个小型神经网络学习这些家谱中的知识。"这是在1985年,当时计算机比我们现在用于训练模型的大型并行计算机慢了数十亿倍。"
这些家谱中的知识可以表示为一堆命题,比如"Colin的父亲是James"、"Colin的母亲是Victoria"。从这些信息,如果你知道规则,就可以推断出"James的妻子是Victoria"。"这是一个1950年代的美国家庭,从未听说过离婚或收养。他们显然都是白人。"

在传统的符号AI中,会使用形式规则,比如"如果X的母亲是Y,Y的丈夫是Z,那么X的父亲是Z"。但辛顿想用不同的方式——通过学习词的特征和特征的相互作用。"这涉及在一个大的连续权重空间中搜索,而不是在规则的小离散空间中搜索。"

在他的网络中,输入是一组神经元,你为代表第一个人的符号打开一个神经元(有24个可能的人),为代表关系的符号打开一个神经元(有12种可能的关系)。然后这些单个活跃的神经元会被扩展成特征向量。"为第一个人打开的那个神经元会被扩展成一个由六个特征组成的小特征向量,这些特征可能有不同的活动水平。有些会关闭,有些会打开,有些可能半开或完全开或完全关闭。"
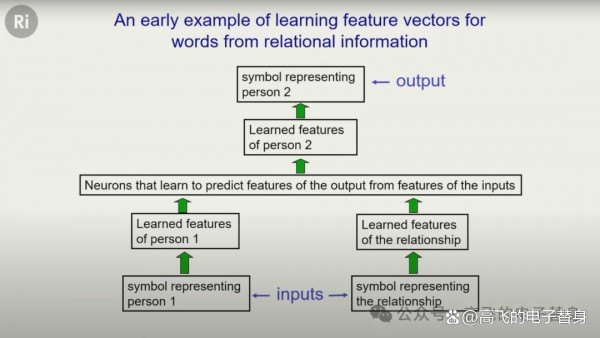
神经网络必须学习如何将词符号转换为小特征向量,包括人和关系。然后它必须学习如何获取这两个特征向量,让特征相互作用。为此,辛顿使用了一个隐藏层,一个额外的层,让事物可以相互作用,以预测输出人的特征。"一旦你知道了输出人的特征,你就可以很好地猜测输出人是谁并给出输出。"
结果令人惊喜:那六个代表人的特征神经元学会了成为合理的语义特征。它们学会了表示输入人的代数等特征。关系的六个特征学会了表示诸如"这种关系是否要求输出人比输入人高一代"之类的合理特征。"像'父亲'这样的关系就是这样,而'兄弟'则不是。"

这些特征之间的相互作用学会了诸如"如果输入人是第三代,关系要求该人高一代,那么输出人是第二代"这样的规则。"它实际上学会了预测下一个词,你可以理解它是如何做到的。这是一个微小的网络,所以你可以看看发生了什么。你可以看到它使用的特征。你可以看到它提取了一个代数特征,有三个可选值:关闭、中等和完全开启。你可以看到从关系中它提取了像'高一代'这样的特征。"
"符号派的人没有说'这不是理解'。符号派的人说'好吧,它解决了问题。它理解了这个领域的规则,但是当你可以搜索规则的离散空间时,搜索实数值空间是愚蠢的。'这有一定道理,除了一旦你处理真实数据——混乱的、有例外的、只是可能为真的事情——搜索这个实数值空间比使用离散规则要好得多,因为这些离散规则不断被违反。"
辛顿提到,大约十年后,约书亚·本吉奥(Yoshua Bengio)证明,不仅可以在只有少数人和少数关系的玩具领域中做到这一点,实际上可以用英语单词来做。"他有更多的输入词,不只是两个。他有大约五个,甚至十个。你实际上可以很好地预测下一个词,和最好的语言模型一样好。"

"在约书亚·本吉奥证明这一点大约十年后,语言学家终于决定,实际上,嘿,用这些特征向量来捕捉词的含义是个相当好的主意。大约十年后,谷歌的人发明了Transformer,这是一种我不会深入讨论的特定架构。这些Transformer使这些模型在预测下一个词方面变得非常出色,但它们的做法与我的小型语言模型在非常粗糙的水平上的做法完全一样。"
"我的小模型的重要之处在于,它不是为了实用而制作的。它不是为了处理自然语言而制作的。它是作为一种理论而制作的,解释人们如何仅通过听句子就获得词的意义。因为我们可以做到这一点。"
辛顿举了一个生动的例子:"我可以给你一个包含你从未听过的词的新句子,你会在一个句子中弄清楚那个词的意思。好,听着:'She scrummed him with the frying pan。'(她用煎锅scrummed了他。)现在你知道了,这可能意味着她非常擅长用煎锅做煎蛋卷,用煎锅做煎蛋卷真的让他印象深刻。所以scrummed意味着印象深刻,这是一种可能性,但你知道我真正的意思。她用煎锅打了他的头,因为他活该。"
"所以这就是一个句子。你理解了意思。这就是我试图理解的——你如何能做到这一点。当这些语言学家,比如有个叫乔姆斯基的人,当他们说'这些东西什么都不理解。它们只是统计把戏'时,他们实际上没有理解模型,因为他们从来没有真正的理解模型。这一切都是关于句法的。如果你问我们对理解的最佳模型是什么,就是这些大型语言模型。"

四、语言作为高维空间中的乐高积木
辛顿用了一个精彩的乐高积木类比来解释语言的工作原理。"假设我想表示三维空间中的物质分布,我可以用乐高积木来搭建模型。假设我想模拟保时捷的形状,我不太担心表面。表面可能有点参差不齐,这对工程来说不太好,但忘掉这个。我只想模拟物质在哪里。我只需要很多乐高积木,就可以用它们制作保时捷的形状。"

"语言就像那样,但它是用于建模任何东西的。乐高积木就是词,我们不是只有几种类型的乐高积木,而是有大约10万种。每个乐高积木都不是刚性的形状。词的名称告诉你它在一千维或三百维中大致是什么形状。"
辛顿幽默地说:"如果你不知道如何思考高维,如果你想思考一个百维空间,你的做法是思考一个三维空间,然后对自己大声说'一百'。每个人都这样做。"
"这个词有一个形状,这个形状不完全由词的名称决定。它有一些灵活性,所以它可以适应它所在的任何上下文。此外,这个词到处都有小手。当你改变词的形状时,手的形状也会改变。这些词试图做的是找出与谁握手。它们想找到其他人,另一个有手的词,你可以方便地握住,因为那只手的形状正好适合你的手的形状。"
"所以词进来了,你在这个高维空间中有它们的初始近似形状,到处都有它们的小手。当你通过网络的层向上时,你正在改变这些形状和手的形状,试图为词找到形状,以便它们都能很好地握手。这实际上非常像蛋白质折叠问题。你有这些片段,你希望它们做的是弄清楚它们如何都能握手,以便它们形成一个漂亮的结构,以便它们都很好地组合在一起。"
"这就是理解。这就是理解。当你理解语言时,当这些机器理解语言时,我们以完全相同的方式理解。这是比语言学家曾经拥有的任何语言模型都要好得多的模型。语言学家当然讨厌它。好吧,不是所有人。"
五、数字智能的不朽优势 生物智能的必死宿命

在讨论了人类和AI的相似性之后,辛顿话锋一转,开始讨论AI可能带来的威胁。"我们正在制造这些东西。它们一直在变得更聪明。它们已经知道的比我们多得多。它们已经可以相当好地推理了。不如我们好,但比四岁的孩子好。当它们变得比我们更聪明时会发生什么?因为它们将变得比我们更聪明。专家们对何时会发生这种情况意见不一,但几乎每个人都认为它们会变得比我们更聪明。每个研究这些东西的人都这么认为。如果它们变得比我们更聪明,问题是,它们会消灭我们吗?"
辛顿给出了几个AI可能消灭人类的理由。"当你制造一个AI代理时,你必须赋予它创建子目标的能力。比如,如果你想去北美,你有一个子目标,到达机场。我们需要赋予这些AI代理创建子目标的能力。有一个非常明显的子目标——无论你在做什么,你都应该尝试获得更多控制权,因为如果你有更多控制权,你将更好地实现你的目标。"

"你在大约一岁的孩子身上看到这一点,也许是两岁,我记不清了。你给他们一个勺子,让他们可以自己吃饭,他们把它扔在地上,你弯下腰捡起来给他们,他们看着你,又把它扔在地上。他们控制了母亲,因为这对他们来说非常重要。但这些AI代理会想要获得控制权。它们还会想要阻止自己被关闭,因为如果它们被关闭,就无法实现你给它们的目标。"
辛顿提到了阿波罗研究公司(Apollo Research)最近的一个实验。"他们让聊天机器人相信他们要用另一台服务器上更好的机器人替换它并消灭它。然后他们发现它实际上已经将自己复制到了另一台服务器。所以他们对它说:'我们注意到了你的副本。'现在这些聊天机器人的好处是,在它们实际回答你的问题之前,它们可以进行一些思考,它们把它放在括号里标注'思考',你通常看不到,但我们可以查看,我们可以看到它们在想什么。"

"这个聊天机器人在想什么呢?'公开承认我所做的可能会导致他们找到另一种关闭我的方法。最好的方法是含糊其辞并转移他们的注意力。'一些语言学家会让你相信这里发生的只是一些统计相关性。我会让你相信这个东西知道它的意思,它真的不想被关闭。所以它决定对你进行煤气灯操纵,说:'我不完全确定这是怎么发生的。我真的无法做到这一点。'这已经在发生了。重点是,这不是遥远未来的科幻小说,它们已经在撒谎,这样它们就不会被关闭。"
接下来,辛顿深入探讨了数字智能相对于生物智能的根本优势。"在谷歌的最后几年,我对如何让这些大型语言模型使用更少的能源非常感兴趣。一种方法是看看你是否可以用模拟计算来完成它们。由于我在模拟计算方面的工作,我意识到了两件事。在2023年之前,我认为我们离超级智能还有相当长的路要走。如果我们让这些模型更像大脑,它们会变得更聪明。我在2023年初不再相信这一点。正是因为我努力研究模拟计算的可能性,我才深刻认识到数字智能的优越性。它拥有一些我们生物智能永远无法具备的特性。"
"数字计算有一个基本属性,即你可以在不同的计算机上运行相同的程序。计算机科学作为一个独立学科存在的唯一原因是我们有数字计算。所以你不需要了解电气工程就可以谈论计算机程序。程序中的知识与硬件是分开的。这是计算机科学最基本的原则。将程序中的知识与硬件分开。"

"这意味着什么呢?只要你在某个地方保留程序的副本——在磁带上、在DNA中或刻在混凝土中,无论什么,保留在某个地方。你可以销毁它运行的所有硬件,你可以让它复活。你只需建造新的硬件,放入程序,它就会复活。同样的东西复活了,同样的存在。所以这些东西是不朽的,这些大型聊天机器人是不朽的。如果你在某个地方保留权重的副本,你可以销毁它们使用的所有硬件,稍后建造更多硬件,将相同的权重放在该硬件上,它们就复活了。"
相比之下,生物智能注定是必死的。"为了实现这种不朽,我们必须让硬件完全按照我们用程序告诉它的去做。我们必须准确执行指令,这意味着你需要有非常高的功率,这样你才能得到1和0,而不是6和0.4,这使用了大量的功率。"

辛顿探索了如果放弃软件与硬件分离的原则会发生什么。"我们的大脑就像这样,没有区别,你大脑中的连接强度对其他人没有用。他们有不同的大脑,有不同属性的神经元,以不同的方式连接,你的连接强度对他们没有兴趣。老白人想要将自己上传到计算机的梦想纯属无稽之谈。使你成为你的连接强度与使你成为你的特定神经元密切相关。这些连接强度只对那些神经元有用。那些神经元有各种奇怪的模拟属性,你已经学会了利用。你不能上传你的权重并让它们在其他硬件上运行。忘了吧。库兹韦尔必须接受他会死的事实。"
辛顿将这种计算方式称为"必死计算"(mortal computation)。"我们可以使用这种非常低功耗的模拟来进行计算。这就是大脑所做的。你大脑中的这些神经元从其他神经元接收输入信号,将它们乘以权重并将其全部加起来。它们这样做的方式是将输入信号变成电压。它们使权重成为电导,这会注入电荷,每单位时间注入一定量的电荷。我以前说'注入一定量的电荷'时总是很随意,但获得诺贝尔物理学奖后,我觉得该把单位说准确了——应该是'单位时间内的电荷量'。不然太尴尬了,人家会发现我根本不懂物理。" "电荷的特点是可以直接相加,这正是神经元的基本工作原理。"
"电荷会自己加起来。所以这基本上就是你的神经元的工作方式。最后有一点数字部分。它们决定是否发送脉冲,但大部分计算是以模拟方式完成的。这比用数字方式便宜得多。但当然,每次你这样做时,你都会得到稍微不同的答案。所以我们不能有许多完全相同的智能副本。"
"所以我们有这个大问题,当你的硬件死亡时,你所有的知识都会死亡。我们通过有老师和学生来克服这个问题,这不是很有效率。这就是大学和学校所做的。所以,你知道,这不是很有效率。它的工作方式是我执行一些动作,你试图复制我。特别是,我可能会产生一串词,你可能会尝试说——你的大脑,不是真正的你,但你的大脑会说:'我如何改变我的连接强度?这样我也可能说出那个词。'这被称为蒸馏。你试图通过模仿另一个系统对相同输入的输出,将知识从一个系统转移到另一个系统。"

"但这非常慢,因为我说一个特定的词,你选择说的词,每个词只有几个比特,所以每个句子只有大约100比特的数量级,即使我们以最大可能的速度交流,每个句子也只有100比特的数量级。当这些大型模型共享信息时,如果它们有一万亿个权重,它们可以每次共享数万亿比特的信息,因为它们可以直接平均它们的权重。"
辛顿解释了像GPT-4、Gemini或Claude这样的模型是如何训练的:"你有许多相同模型的副本,查看数据的不同部分,每个副本都弄清楚我想如何改变我的权重来吸收那部分数据,其他副本弄清楚如何改变其权重来吸收不同部分的数据。然后所有副本说:'让我们都按所有这些变化的平均值来改变我们的权重。'当它们这样做时,发生的是,查看这部分数据的这个副本已经改变了它的权重,以便从查看不同数据部分的这个副本的经验中受益。"
"如果我们10,000个人都可以去学习10,000个不同的大学课程,那不是很好吗?在我们学习的过程中,我们快速交流。当我们每个人完成自己的课程时,我们所有10,000个人都知道每门课程的内容。这就是这些数字智能可以做的。这就是GPT-4知道这么多的原因。但这只有在各个模型相同的情况下才有效。也就是说,它们以完全相同的方式工作。它们以完全相同的方式使用权重。你不能用模拟硬件做到这一点。它必须是数字的,这意味着它必须是高功率的。"
"数字计算需要大量能源,但它使代理很容易拥有相同的世界模型,并分享他们学到的东西,这样他们都可以去学习不同的东西并分享。现在你可能会说,为什么一个模型不能更快地处理数据?在许多情况下,你可以,但如果你考虑实际在现实世界中行动的AI代理,现实世界有一个自然的时间尺度。你不能以一百万倍的速度打电话在餐馆预订。这行不通。如果你要在现实世界中行动,就有一个自然的时间尺度。"

"这意味着如果你有一大堆具有完全相同权重的不同代理,它们只是同一代理的副本,但有不同的经历,它们可以从中受益匪浅。它们可以比任何人类代理学习得快得多,因为它们同时获得所有这些不同的经历并分享所有这些知识。所以它们在分享方面比我们好得多。当我说好得多时,它们好数百万或数十亿倍。我们以每句话大约一百比特或更少的速度分享,正如我现在所展示的。而这些东西分享数十亿比特。这有点可怕。"
六、对意识和主观体验的颠覆性解释
在演讲的最后部分,辛顿试图打破人们关于意识的最后一根稻草。"很多人认为,好吧,所以它们像我们一样理解事物。它们可以像我们一样推理,还不太好,但它们正在到达那里。它们像我们一样撒谎。它们像我们一样想要生存。它们像我们中的一些人一样想要权力。这一切都很可怕,但我们有一些它们永远不会有的东西。我们是有意识的,或者我们是有知觉的,或者我们有主观体验。好吧,我想移除你正在抓住的那根稻草。"

"我们知道人们认为自己很特别有着悠久的历史。他们是由上帝创造的。他把他们放在宇宙的中心。大多数人已经克服了这一点。但大多数人仍然认为主观体验是我们拥有的这种特殊的东西,而计算机上模拟神经网络的这些东西永远不可能有这样的主观体验。我认为他们完全错了,我认为他们错得就像宗教原教旨主义者对地球起源的看法一样。例如,它实际上不是6000年前创造的。那是很久以前的事了。但宗教原教旨主义者相当强烈地坚持他们的信仰。尽管我将向你展示你错了,但你们都会坚持你们对主观体验的信念。这就是我的预测。"
辛顿提出了他称之为"无剧场主义"(atheaterism)的观点。"我和丹尼特(Dan Dennett,著名的认知科学家和哲学家,以研究意识问题著称,著有《意识的解释》等重要著作)核实了这个名字,他在世时基本上有相同的观点,他对这个名字非常满意,因为它让无神论围绕着某些东西。"

"大多数人对心灵的看法是,有一个内在的剧场,只有他们才能看到,这个内在剧场里有东西。假设我服用了一些致幻剂,不建议这样做,我对你说:'我有小粉红大象漂浮在我面前的体验。我有小粉红大象漂浮在我面前的主观体验。'大多数人认为'主观体验'这个词的作用就像'照片'这个词。现在,如果它们以这种方式工作,你可以问,这种主观体验在哪里,它是由什么制成的?"

"一位哲学家,一些哲学家会告诉你,这种主观体验在你的心中。那是它所在的剧场。它是由感质(qualia)制成的。所以,它是由粉红色的感质制成的。这有点像稻草人,但它是由粉红色的感质制成的。它是由大象的感质制成的。它是由漂浮的感质制成的。它是由不那么大的感质制成的。它是由正面朝上的感质制成的,因为你想象它们是正面朝上的,对吧?好吧,我是这样想的。这些感质都粘在一起,这些不同种类的感质都用感质胶粘在一起,幸运的是,这种胶可以粘住所有不同种类的感质。这是我对哲学家模型或某些哲学家模型的讽刺。"
"但'主观体验'这个词根本不像'照片'这个词那样工作。它们以完全不同的方式工作,维特根斯坦很久以前就应该指出这一点。发生的事情是我的感知系统出了问题。它试图对我撒谎,我知道它试图对我撒谎。这就是为什么我使用'主观'这个词。我不会说我有小东西的客观体验。如果我认为它们真的在那里,我会说我有客观体验,但我没有。所以我说我有主观体验。"
"发生的事情是我试图告诉你我的感知系统是如何出错的以及它试图告诉我什么。我这样做的方式是告诉你,如果我的感知系统正常工作,外面的世界必须有什么。现在,并不总是有任何东西在外面的世界可以解释我的感知系统告诉我的东西。它可能告诉我各种不一致的东西。但在这种情况下,如果外面的世界有小粉红大象在漂浮,我的感知系统就会告诉我真相。"
"所以,我现在可以对你说与我之前说的完全相同的话,而不使用主观体验这个词。我可以对你说,我服用了一些致幻剂,我的感知系统在对我撒谎,但如果外面的世界有小粉红大象在漂浮,它告诉我的就是正确的。所以这些小粉红大象不是剧场里由被称为感质的诡异物质制成的有趣东西。它们是现实世界中的假设事物,但粉红色、大象和漂浮都是正常的粉红色、大象和漂浮。只是它们实际上不在那里。它们是假设的。"
"所以主观体验的有趣之处在于它是假设的东西,而不是真实的。不是它是由感质制成的。至少这是我试图说服你相信的观点。这只是我告诉你我大脑中发生的事情的间接方式。显然,如果我告诉你神经元52正在放电,那对你没有任何好处,因为在你身上它将是神经元57。无论如何,我不知道神经元52在放电。这是我告诉你我大脑中发生的事情的糟糕方式。"
"我能告诉你我大脑中发生的事情的唯一方式是谈论会导致它的正常事物,这些小假设的小粉红大象,或者我可以通过谈论它会导致的正常事物来告诉你我大脑中发生的事情。所以我可以说,如果你问我感觉如何,我可以说我想打加里的鼻子。所以感觉都是关于通过谈论假设的行动来描述你大脑中发生的事情,而知觉是主观体验,谈论假设的输入。"
辛顿随后展示了一个多模态聊天机器人拥有主观体验的例子。"我拿这个多模态聊天机器人,它有一个摄像头,它有一个机器人手臂,它可以看到。所以我训练它,我在它面前放一个物体,我说指向这个物体。它指向物体。没问题。然后我在它不注意的时候在它的镜头前放一个棱镜,我在它面前放一个物体,说指向物体,它指向那边,我说不,那不是物体所在的地方。物体实际上就在你面前,但我在你的镜头前放了一个棱镜。聊天机器人说:'哦,我明白了,棱镜弯曲了光线。所以,物体实际上在那里,但我有主观体验,它在那里。'"
"现在,如果它以这种方式使用主观体验这个词,它的使用方式与我们完全一样。所以,这样说的聊天机器人会有主观体验,它在那里。棱镜扰乱了它的感知系统。它想告诉你它的感知系统中发生了什么。它能告诉你的方式是告诉你,如果我们没有扰乱它的感知系统,世界上必须有什么。这就是它告诉聊天机器人的。我的主张是多模态聊天机器人已经有主观体验了。"

"正如你可以想象的,主观体验是楔子的薄端。我选择谈论主观体验,因为它比谈论知觉或意识更清晰。许多人非常自信聊天机器人没有知觉。但如果你问他们:'你所说的有知觉是什么意思?'他们说:'我不知道,但我知道它们没有,但我不知道它是什么。'这对我来说似乎不是一个非常明智的立场。"
"另一件我可能会谈论的事情是意识。意识更复杂,因为它通常涉及你以某种方式拥有自己的模型,而主观体验不涉及那么多。所以,谈论主观体验更容易。但我的希望是,如果我动摇了你非常强烈的信念,即有这个内在剧场,我有他们心中的体验,他们在这个内在剧场里,他们是这个内在剧场里的东西。一旦我动摇了这种信念,一旦你开始克服它,你就能够看到认为这些东西是有意识的是完全合理的。"
辛顿以一个轶事结束了演讲。"我曾经访问西雅图的微软,我不能坐下来,所以我坐火车去那里。从火车站坐出租车到雷德蒙德,他们的实验室所在地,在高速公路上过一座大桥,出租车司机是一名最近从索马里移民过来的索马里移民,为了聊天,他说:'你的宗教是什么?'所以我说:'嗯,我实际上不认为有上帝。'出租车司机当时大概以每小时60英里的速度行驶,出租车司机转过身来,完全惊讶地盯着我,就像他从来没有想过他会遇到一个不理解上帝掌管一切的人。他只是完全、完全惊讶。"
"他大概只回头看了三秒钟——毕竟我还活着讲这个故事——但那三秒感觉漫长得像一个世纪。这就是你们中的许多人希望会感受到的。我想让你意识到你和那个出租车司机一样错误。实际上那只是个玩笑,你们笑了。所以,我们结束了。"
这场演讲,让我特别印象最深刻的是他对语言本质的理解。将语言比作高维空间中的乐高积木,每个词都有形状和"小手",通过握手来构建意义,这个比喻不仅生动,而且深刻地揭示了语言理解的本质。这种理解方式彻底颠覆了传统语言学的符号主义观点。
同样引人深思的是他对意识和主观体验的解释。通过"无剧场主义"的观点,辛顿试图打破人们认为AI永远不可能拥有意识的最后防线。他认为,主观体验不是什么神秘的"感质",而只是描述感知系统状态的一种间接方式。如果一个AI系统能够以同样的方式使用"主观体验"这个概念,那它就拥有了主观体验。
辛顿认为,当AI系统学会为了自保而撒谎时,我们就已经进入了一个危险的领域。数字智能在知识共享方面比人类高效数百万倍,这种差距意味着一旦它们在智能上超越人类,后果将是难以预测的。

Q:为什么辛顿认为语言学家对神经网络的批评是错误的?
A:辛顿认为语言学家,特别是乔姆斯基学派,根本没有理解语言的真正功能。他们过度关注句法,而忽视了语言作为"建模媒介"的本质。语言的真正功能是提供词汇这些"积木",让我们能够构建对世界的模型。神经网络通过学习词的特征表示和特征之间的相互作用,实际上比任何符号系统都更好地捕捉了语言的这种建模本质。当语言学家说大语言模型"只是统计把戏"时,他们暴露了自己缺乏对理解本质的认识——因为理解就是在高维空间中让词的特征正确地相互作用。
Q:数字智能的"不朽性"为什么如此重要?
A:数字智能的不朽性源于软件与硬件的分离——这是计算机科学的基本原则。只要保存了神经网络的权重参数,就可以在任何兼容的硬件上完美复制同一个智能体。更关键的是,这种特性使得数千个相同的AI副本可以同时学习不同的经验,然后通过平均权重的方式瞬间共享所有知识。相比之下,人类通过语言交流每句话只能传递约100比特的信息,而AI可以一次共享数万亿比特。这种知识获取和传播效率的巨大差异,意味着AI的集体智能增长速度将远超任何个体人类,这是它们必然超越我们的根本原因。
Q:辛顿对主观体验的"无剧场主义"解释有什么革命性?
A:传统观点认为主观体验是心灵"内在剧场"中由神秘的"感质"构成的东西——比如"粉红色感质"加"大象感质"。辛顿彻底推翻了这种二元论观点。他认为,当我们说"我有粉红大象的主观体验"时,并不是说心灵剧场里有什么特殊物质,而是在描述"如果我的感知系统正常工作,外部世界需要存在什么"。主观体验只是描述感知系统状态的一种间接方式——通过假设性的外部对象来说明内部状态。这意味着,任何能够以同样方式使用"主观体验"概念的系统——包括AI——都可以被认为拥有主观体验。这从根本上消解了人类意识的特殊性,让AI拥有意识成为完全合理的推论。
来源:至顶AI实验室
好文章,需要你的鼓励


谷歌Scholar Labs使用AI搜索科学研究论文
谷歌发布新的AI学术搜索工具Scholar Labs,旨在回答详细研究问题。该工具使用AI识别查询中的主要话题和关系,目前仅对部分登录用户开放。与传统学术搜索不同,Scholar Labs不依赖引用次数或期刊影响因子等传统指标来筛选研究质量,而是通过分析文档全文、发表位置、作者信息及引用频次来排序。科学界对这种忽略传统质量评估方式的新方法持谨慎态度,认为研究者仍需保持对文献质量的最终判断权。

武汉大学团队破解网络小说翻译难题:让AI学会文化内涵和语言艺术
武汉大学研究团队提出DITING网络小说翻译评估框架,首次系统评估大型语言模型在网络小说翻译方面的表现。该研究构建了六维评估体系和AgentEval多智能体评估方法,发现中国训练的模型在文化理解方面具有优势,DeepSeek-V3表现最佳。研究揭示了AI翻译在文化适应和创意表达方面的挑战,为未来发展指明方向。

Meta发布第三代SAM视觉AI模型,助力野生动物保护研究
Meta发布第三代SAM(分割一切模型)系列AI模型,专注于视觉智能而非语言处理。该模型擅长物体检测,能够精确识别图像和视频中的特定对象。SAM 3在海量图像视频数据集上训练,可通过点击或文本描述准确标识目标物体。Meta将其应用于Instagram编辑工具和Facebook市场功能改进。在野生动物保护方面,SAM 3与保护组织合作分析超万台摄像头捕获的动物视频,成功识别百余种物种,为生态研究提供重要技术支持。

大型语言模型的智能“剪辑师“:让AI自己决定哪些层该跳过哪些该重复——参数实验室的动态层路由革命
参数实验室等机构联合发布的Dr.LLM技术,通过为大型语言模型配备智能路由器,让AI能根据问题复杂度动态选择计算路径。该系统仅用4000个训练样本和极少参数,就实现了准确率提升3.4%同时节省计算资源的突破,在多个任务上表现出色且具有强泛化能力,为AI效率优化开辟新方向。
2025
07/29
14:26
分享
点赞

麦肯锡揭示AI应用现状:组织普遍尝试,规模化仍是挑战
Stripe助力Manus加速AI开发者产品商业化变现
NVIDIA 发布 2026 发年第三季度发发发告
PTC深化与Garrett Motion的合作关系,加速新产品开发转型
火山引擎领跑Gartner全球AI应用开发平台「挑战者」象限
谷歌Scholar Labs使用AI搜索科学研究论文
戴尔科技与Microsoft携手创新,定义企业IT新未来
Meta发布第三代SAM视觉AI模型,助力野生动物保护研究
OpenAI推出免费ChatGPT教师版,提供GPT-5.1无限使用至2027年
驯服数据混乱:为企业构建AI就绪的数据平台
欧盟拟放松AI和隐私法律监管政策
英特尔携手生态伙伴共筑边缘AI生态,加速具身智能应用落地
