
AI届也有自己的拼多多,阶跃星辰推出超省钱的AI模型:Step-3 原创
对于普通用户而言,国内模型通常都能在网页或手机端免费使用,不需要会员费,还是很幸运的。
对于企业用户来说,通过API或者自建服务器使用模型,按量计费而且用量大,模型价格的高低就很重要了。
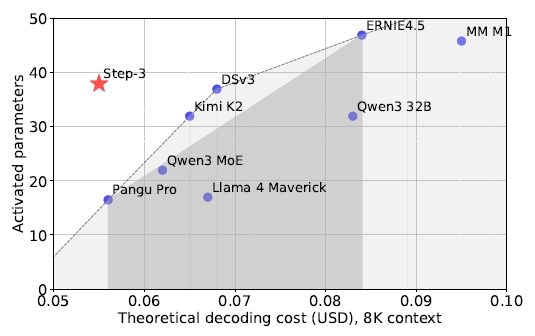
2025年7月,阶跃星辰发布Step-3模型,拥有3210亿参数却比同类模型运行成本低40%。通过创新的多矩阵分解注意力机制和分离式系统设计,Step-3在保持高性能的同时大幅降低推理成本,每GPU吞吐量达4039 tokens/秒,超越竞争对手74%。Step-3相关论文在arXiv上发表。
Step-3的核心秘诀:重新设计AI的"大脑结构"
Step-3的第一个重大创新是多矩阵分解注意力机制(MFA)。简单来说,传统的AI模型处理信息时,就像一个餐厅的服务员需要同时记住所有桌子的所有需求,这对记忆力要求极高,而且效率不佳。Step-3的MFA机制就像给餐厅配备了一个智能管理系统,服务员不需要记住所有细节,只需要记住核心要点,其他信息通过系统快速调取。
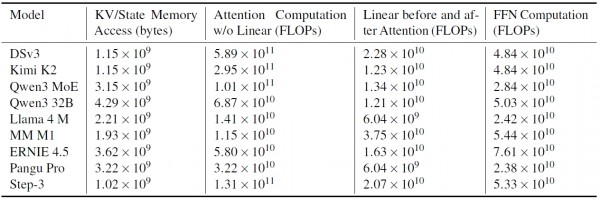
具体来说,传统模型需要为每个"注意力头"分配完整的记忆空间,就像每个服务员都需要一个完整的订单本。而MFA让多个注意力头共享一套精简的记忆系统,大大减少了内存占用。研究数据显示,Step-3的记忆占用比同类模型少了约10%,但性能丝毫不受影响。
这种设计的巧妙之处在于找到了性能和成本的最佳平衡点。研究团队发现,不同硬件平台都有自己的"计算节奏",就像不同餐厅有不同的出菜速度。Step-3的MFA机制能够适应各种硬件的节奏,无论是高端的H800芯片还是中端的H20芯片,都能发挥出理想的效果。
分离式设计:让AI的"前厅"和"后厨"各司其职
Step-3的第二个创新是注意力-前馈网络分离(AFD)系统,这个设计理念就像重新规划餐厅的工作流程。传统AI模型就像一个餐厅把前厅接待、点菜、做菜、上菜全部混在一起,导致效率低下。Step-3将这些功能彻底分离:注意力部分专门负责"理解顾客需求",前馈网络部分专门负责"制作回答"。
这种分离带来了多重好处。首先是可以针对不同任务选择最合适的硬件。处理注意力的部分需要大量内存但计算相对简单,就像餐厅前厅主要需要好的服务空间;而前馈网络部分需要强大的计算能力但内存要求不高,就像后厨主要需要强大的设备。
更重要的是,这种分离设计让整个系统可以采用流水线作业。当注意力部分在处理新问题时,前馈网络部分可以同时为之前的问题生成答案,就像餐厅可以同时接待新客人和为老客人上菜。研究团队实现了三阶段流水线,将每个阶段的处理时间控制在16.6毫秒以内,确保整体响应时间不超过50毫秒。
精准的成本控制:每一分钱都花在刀刃上
研究团队进行了详细的成本分析,就像一个餐厅经理仔细计算每道菜的成本构成。他们发现,在AI推理过程中,注意力部分的成本往往占据主导地位,特别是在处理长文本时。这就像发现餐厅的主要成本不是食材而是服务员的时间。
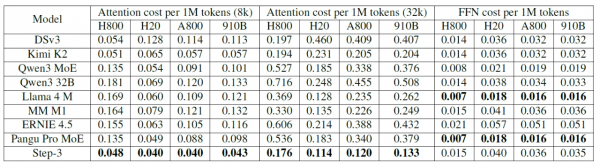
通过对比分析,研究团队发现Step-3在8000字符长度的文本处理中,每百万次推理的成本仅为0.055美元,而DeepSeek-V3需要0.068美元,Qwen3 MoE需要0.062美元。更重要的是,随着文本长度增加,Step-3的成本优势会进一步扩大。在32000字符长度时,Step-3的成本为0.129美元,DeepSeek-V3需要0.211美元,Qwen3 MoE需要0.193美元。
这种成本优势来源于Step-3在硬件友好性方面的精心设计。不同的AI芯片有着不同的计算特性,就像不同的烤箱有不同的加热特点。Step-3的MFA机制的"计算密度"恰好匹配大多数主流芯片的特性,而不是只针对最高端芯片优化。这意味着Step-3可以在更便宜的硬件上也能高效运行,大幅降低了部署成本。
突破传统认知:模型大小不等于运行成本
这项研究的一个重要发现是彻底颠覆了"模型越大越贵"的传统观念。研究团队通过详细分析发现,模型的运行成本主要取决于架构设计而不是参数数量。Step-3虽然有3210亿参数,每次推理激活380亿参数,但运行成本却比许多更小的模型还要低。
这就像发现一道看起来很复杂的菜,实际制作成本可能比简单的菜还要低,关键在于制作工艺而不是食材数量。传统模型就像用最贵的食材但制作工艺低效的菜品,而Step-3就像用精巧工艺制作的高性价比美食。
研究团队特别指出,许多现有模型在设计时过分追求某一方面的优化,就像餐厅只关注食材质量而忽视了制作效率。比如有些模型为了减少内存占用而大幅增加计算量,结果在低端硬件上反而更昂贵。Step-3通过系统性的协同设计,在各个方面都达到了最佳平衡。
实际性能表现:理论转化为现实的成功验证

为了验证理论设计的实际效果,研究团队在Hopper GPU上进行了全面测试。结果显示,Step-3在50毫秒响应时间限制下,每GPU每秒可以处理4039个文本标记,比DeepSeek-V3的2324个提升了74%。这就像同样的厨房设备,Step-3餐厅每小时能服务的顾客数量比竞争对手多了近一倍。
而且,Step-3只需要32个GPU就能达到这个性能,而DeepSeek-V3需要128个GPU才能实现类似的吞吐量。这种效率提升不仅节约了硬件成本,还大大简化了部署复杂度。就像原本需要一整栋楼才能开的餐厅,现在只需要一层楼就够了。
研究团队还测试了Step-3在不同硬件平台上的表现。无论是高端的H800芯片、中端的H20芯片,还是较低成本的A800和910B芯片,Step-3都能保持稳定的性能表现,这种硬件兼容性为实际部署提供了极大的灵活性。
技术创新的深层逻辑:协同设计的威力
Step-3核心在于"模型-系统协同设计"理念的彻底贯彻。研究团队没有孤立地优化某个组件,而是将整个AI系统视为一个有机整体进行统筹设计。
在混合专家模型(MoE)的设计上,Step-3也体现了这种系统性思维。传统模型往往追求极度稀疏的专家配置,认为这样可以减少计算量。但研究团队发现,过度稀疏会导致网络通信瓶颈,就像餐厅的专家厨师分布得太分散,反而增加了协调成本。Step-3选择了适度的稀疏度,确保在不同硬件平台上都能达到理想的效率。
研究团队还开发了专门的通信库StepMesh,专门优化AI推理过程中的数据传输。这个系统采用了多线程异步通信、CPU优化操作等技术,将网络延迟降到了极致。
至顶AI实验室洞见
最让我印象深刻的是,Step-3没有一味追求针对N卡优化,在910B上的运行成本跟N卡相近。
研究团队预见到AI模型会越来越大,上下文长度会越来越长,因此设计了AFD系统可以根据不同的上下文长度动态调整注意力实例的数量。
在支持异构硬件方面,Step-3也展现出了出色的适应性。研究团队发现,可以用较低端的L20芯片来处理注意力计算,用高端芯片专门处理前馈网络计算。这种混合部署方式可以进一步降低总体成本,在保证整体效果的同时优化成本结构。
Step-3证明了通过系统性的协同设计,可以在不牺牲性能的前提下大幅降低AI模型的运行成本。
未来使用AI服务的成本将显著降低,响应速度将明显提升。无论是写作助手、代码生成,还是复杂的推理任务,都将变得更加普及和便宜。AI技术的民主化,让高质量的人工智能不再是少数人的专利,而是人人都能享受的普惠技术。
论文地址:
https://www.arxiv.org/abs/2507.19427
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:Step-3模型如何降低解码成本?
A:Step-3通过硬件感知的模型-系统协同设计(如多矩阵分解注意力MFA和注意力-FFN解耦AFD)显著减少KV缓存大小和计算量,同时保持高注意力表达能力。其解码成本比DeepSeek-V3和Qwen3 MoE 235B等模型低40%,尤其在长上下文任务中优势更明显。
Q2:Step-3的注意力机制MFA有什么创新?
A:MFA通过低秩矩阵分解优化Query-Key电路,在减少KV缓存和计算的同时,保持高注意力表达性。其算术强度(128)与硬件计算-带宽比更匹配,适合多种加速器(如H800/H20),而MLA和GQA设计则存在硬件效率不足的问题。
Q3:AFD系统如何提升Step-3的推理效率?
A:AFD将注意力层和FFN层解耦为独立子系统,分别部署到最优硬件(如H800处理注意力,H20处理FFN),通过3阶段流水线隐藏通信开销,实现50ms/Token的延迟目标。相比传统EP部署,AFD支持动态上下文扩展和异构硬件,成本更低。
来源:至顶AI实验室
好文章,需要你的鼓励


谷歌Scholar Labs使用AI搜索科学研究论文
谷歌发布新的AI学术搜索工具Scholar Labs,旨在回答详细研究问题。该工具使用AI识别查询中的主要话题和关系,目前仅对部分登录用户开放。与传统学术搜索不同,Scholar Labs不依赖引用次数或期刊影响因子等传统指标来筛选研究质量,而是通过分析文档全文、发表位置、作者信息及引用频次来排序。科学界对这种忽略传统质量评估方式的新方法持谨慎态度,认为研究者仍需保持对文献质量的最终判断权。

Meta研究团队发布超大规模视觉推理数据配方:让AI像人类一样“看图解题“的秘密
Meta公司FAIR实验室与UCLA合作开发了名为HoneyBee的超大规模视觉推理数据集,包含250万训练样本。研究揭示了构建高质量AI视觉推理训练数据的系统方法,发现数据质量比数量更重要,最佳数据源比最差数据源性能提升11.4%。关键创新包括"图片说明书"技术和文字-图片混合训练法,分别提升3.3%和7.5%准确率。HoneyBee训练的AI在多项测试中显著超越同规模模型,同时降低73%推理成本。

Meta发布第三代SAM视觉AI模型,助力野生动物保护研究
Meta发布第三代SAM(分割一切模型)系列AI模型,专注于视觉智能而非语言处理。该模型擅长物体检测,能够精确识别图像和视频中的特定对象。SAM 3在海量图像视频数据集上训练,可通过点击或文本描述准确标识目标物体。Meta将其应用于Instagram编辑工具和Facebook市场功能改进。在野生动物保护方面,SAM 3与保护组织合作分析超万台摄像头捕获的动物视频,成功识别百余种物种,为生态研究提供重要技术支持。

多模态AI的“减肥革命“:上海AI实验室让视觉模型效率翻倍的神奇方法
上海AI实验室团队提出ViCO训练策略,让多模态大语言模型能够根据图像语义复杂度智能分配计算资源。通过两阶段训练和视觉路由器,该方法在压缩50%视觉词汇的同时保持99.6%性能,推理速度提升近一倍,为AI效率优化提供了新思路。
2025
07/30
17:56
分享
点赞

PTC深化与Garrett Motion的合作关系,加速新产品开发转型
火山引擎领跑Gartner全球AI应用开发平台「挑战者」象限
谷歌Scholar Labs使用AI搜索科学研究论文
戴尔科技与Microsoft携手创新,定义企业IT新未来
Meta发布第三代SAM视觉AI模型,助力野生动物保护研究
OpenAI推出免费ChatGPT教师版,提供GPT-5.1无限使用至2027年
驯服数据混乱:为企业构建AI就绪的数据平台
欧盟拟放松AI和隐私法律监管政策
英特尔携手生态伙伴共筑边缘AI生态,加速具身智能应用落地
英特尔携本地生态伙伴发布双路冷板式全域液冷服务器,引领数据中心散热与能效革新
向新而生,同“芯”向上 2025英特尔技术创新与产业生态大会在重庆举行
SC25超级计算大会:AMD、英伟达、戴尔发布下一代超算产品
