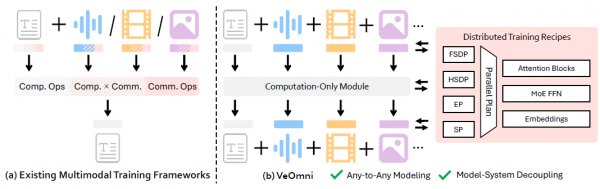
AI似乎正在朝着一个有趣的方向演进,从只能处理单一模态的专用模型,发展为能够同时理解和生成文字、图像、音频、视频等多种媒体的全才模型,也被称为"全模态"的AI系统。然而,训练这样的AI系统面临着巨大挑战。
2025年8月7日,字节Seed团队推出VeOmni框架,通过模块化设计和智能并行策略,将复杂的全模态AI训练简化为"搭积木"式的直观操作。该框架支持30B参数模型达到每GPU 2800 token/s的吞吐量,能处理160K上下文长度,显著降低了多模态AI研发门槛,为推动AI技术普及提供了强大工具。相关论文发表在arXiv上。
想象一下,如果训练一个能够同时理解文字、图片、视频和声音的AI模型就像搭积木一样简单,只需要把不同的积木块组合在一起,不用担心底层的复杂连接问题,这会带来多大的便利?ByteDance的研究团队就创造了这样一个"积木盒子":VeOmni框架,让原本极其复杂的多模态AI训练变得像组装玩具一样直观。
传统的训练方法就像试图用同一套教具去教授完全不同的课程,效果往往不尽人意。更麻烦的是,当你想要扩大训练规模,比如从教一个学生变成教一百个、一千个学生时,现有的方法就会变得极其复杂和低效。这正是VeOmni要解决的核心问题。
VeOmni的核心创新在于提出了一种"模块化训练配方"的概念。如果把传统的AI训练比作做菜,那么以往的方法就像每次做菜都要从头开始,不仅要准备食材,还要自己制作调料,甚至连锅碗瓢盆都要自己打造。而VeOmni则像是建立了一个标准化的厨房系统,你只需要从调料架上拿取现成的调料,从工具柜里取出合适的厨具,就能快速烹饪出美味的料理。
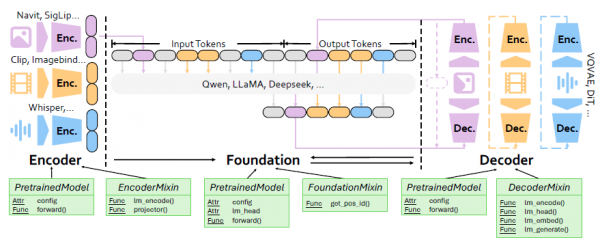
这种模块化设计的巧妙之处在于将复杂的训练过程分解为三个相互独立又能协调工作的部分:编码器、基础模型和解码器。编码器就像是翻译官,负责将不同类型的原始数据(文字、图像、音频等)翻译成AI能够理解的通用语言。基础模型则是大脑中枢,负责处理和分析这些翻译后的信息。解码器则是表达者,将处理后的信息重新转换为人类能够理解的各种形式。
更重要的是,VeOmni设计了一套标准化的接口协议,就像USB接口一样,任何符合标准的设备都能轻松连接。这意味着研究人员可以自由地更换或升级其中任何一个组件,而不需要重新设计整个系统。比如,你想要添加一个新的图像处理模块,只需要确保它遵循VeOmni的接口标准,就能无缝集成到现有系统中。
训练过程的设计很直观,在训练阶段,每个编码器只需要实现一个名为"lm_encode"的功能,将原始数据转换为标准格式的嵌入向量,这些向量随后被插入到基础模型的输入中。解码器也遵循同样的简洁设计,通过"lm_head"功能将模型输出转换为目标模态的数据。
在推理阶段,系统更加智能。当模型生成特定的标记符号时,系统会自动切换到相应的生成模式。比如,当检测到图像开始标记时,系统会自动启动图像生成流程,通过解码器的"lm_embed"功能生成中间嵌入,然后使用"lm_generate"功能产生最终的图像输出。这种设计让多模态生成变得既灵活又高效。
当面对训练大规模AI模型这个挑战时,单台计算机的能力显然是不够的,就像用一个人来搬运几十吨货物一样不现实。这时就需要分布式训练,让多台计算机协同工作,就像组织一个搬运团队一样。但是,如何让这些计算机高效协作,避免互相干扰或资源浪费,这本身就是一门艺术。
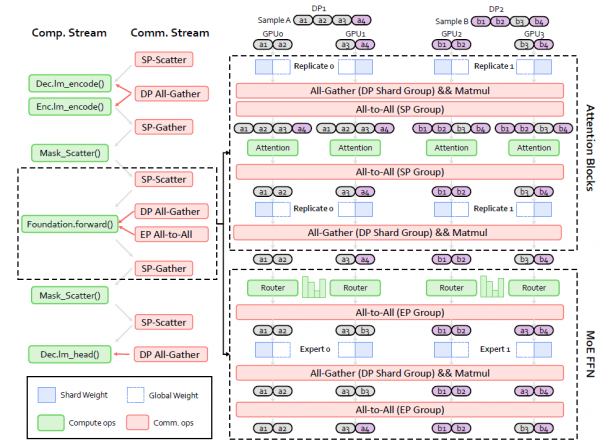
VeOmni在这方面的创新可以用"分工合作"来形容。它提供了多种不同的并行化策略,每种策略都针对特定的场景进行了优化。全分片数据并行(FSDP)就像是将一个大型拼图分发给多个人同时拼装,每个人负责一部分,最后再将结果合并。这种方法的好处是显著减少了每台计算机需要的内存,让原本无法在单台机器上训练的大型模型成为可能。
序列并行(SP)则专门针对长序列训练进行了优化。当处理极长的文本、高分辨率图像或长视频时,传统方法往往会遇到内存不足的问题。VeOmni采用了DeepSpeed-Ulysses技术,将长序列切分到不同的计算设备上处理,就像将一本厚书的不同章节分给不同的人阅读,然后再汇总理解内容。更巧妙的是,VeOmni还开发了异步版本的Async-Ulysses,让通信和计算可以同时进行,大大提高了效率。
专家并行(EP)是为混合专家模型(MoE)设计的特殊策略。MoE模型的工作原理类似于一个专业咨询团队,面对不同类型的问题时,会激活相应的专家来处理。VeOmni让这些"专家"能够分布在不同的计算设备上,同时通过巧妙的通信优化技术,将数据传输的延迟隐藏在专家计算的过程中,实现了近乎无损的性能提升。
最重要的是VeOmni的"可组合n维并行"设计。就像搭建乐高积木一样,你可以自由组合不同的并行策略。比如,你可以同时使用FSDP和SP实现2D并行,或者结合FSDP、SP和EP实现3D并行。这种设计的灵活性意味着研究人员可以根据具体的模型架构和硬件配置,选择最优的并行组合策略。
更重要的是,VeOmni使用了统一的设备网格抽象来管理这些复杂的并行配置。传统方法需要手动管理多个进程组,就像同时指挥几个不同的乐队一样复杂。而VeOmni的设计让这个过程变得像使用遥控器控制电视一样简单,研究人员只需要通过简单的配置就能启用复杂的并行策略。
除了核心的并行化策略,VeOmni还集成了一系列精心设计的系统优化技术,这些技术就像汽车引擎的各种优化部件一样,虽然单独看起来可能不起眼,但组合在一起却能带来显著的性能提升。
动态批处理技术解决了一个常见的效率问题。在传统方法中,为了批量处理数据,系统往往需要将所有样本填充到相同的长度,就像为了装箱整齐而在不同大小的物品间填充泡沫一样,这会造成大量的计算浪费。VeOmni的动态批处理则像是使用可调节大小的包装盒,根据实际内容调整容器大小,配合FlashAttention技术,在保证计算正确性的同时最大化了资源利用率。
在计算核心优化方面,VeOmni集成了包括RMSNorm、LayerNorm、RoPE、SwiGLU等在内的高度优化算子核心,以及专门针对MoE操作的优化实现。这些优化就像为发动机更换了高性能零部件,每个组件都经过精心调校,确保在各种不同的硬件配置下都能发挥最佳性能。
内存优化策略包括层级重计算、激活卸载和优化器状态卸载等技术。这些技术的作用类似于智能内存管理,根据实际需要动态调整内存使用策略。比如,不常用的数据可以暂时存储到速度较慢但容量更大的存储设备中,需要时再调回高速内存,这样就能在有限的内存条件下训练更大的模型。
检查点系统使用了ByteCheckpoint技术,实现了高效的模型保存和恢复。这个系统不仅支持在不同的分布式配置间进行模型迁移,还能确保训练过程的可靠性。就像汽车的自动保存功能一样,即使遇到意外情况,也能从最近的保存点继续,而不需要从头开始。
元设备初始化技术让大型模型的初始化变得更加高效。传统方法在初始化大型模型时需要分配实际的物理内存,而VeOmni可以在"虚拟"设备上完成初始化,然后通过DTensor格式进行参数分片和并行加载,显著加速了大规模模型的启动过程。
为了验证VeOmni的实际效果,研究团队进行了一系列详尽的实验,涵盖了从8个GPU到128个GPU的大规模集群,测试了从7B到72B参数规模的不同模型。这些实验就像是对一辆新车进行全方位的路试,从城市道路到高速公路,从日常通勤到长途旅行,全面测试其性能表现。
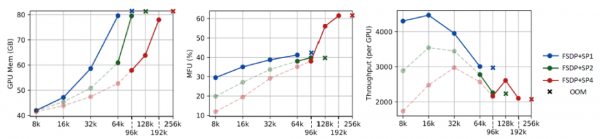
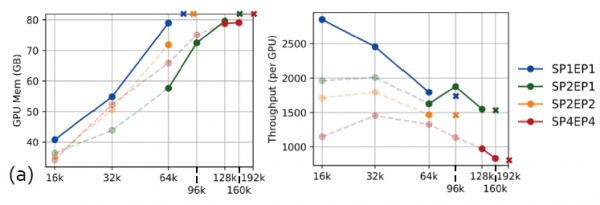
在使用Qwen2-VL 7B模型的实验中,VeOmni展现出了令人印象深刻的扩展能力。在8个GPU的配置下,系统能够支持高达192K的上下文长度训练,模型FLOPs利用率达到61.5%。当扩展到72B参数的模型时,即使在128个GPU的大规模配置下,系统仍能稳定支持96K上下文长度的训练,MFU达到54.82%。这些数字背后代表的是系统在处理超长序列时的出色能力,这对于处理长文档、高分辨率图像或长视频等任务具有重要意义。
更令人兴奋的是在混合专家模型上的测试结果。使用基于Qwen3-30B-A3B的30B参数MoE模型,VeOmni实现了超过2800 tokens/sec/GPU的训练吞吐量,能够扩展到160K的上下文长度。这个性能水平意味着研究人员可以在相对较短的时间内训练出具有强大多模态能力的大型模型。
与现有的先进框架TorchTitan的对比实验进一步证明了VeOmni的优势。在相同的硬件配置和模型设置下,VeOmni在吞吐量和内存效率方面都表现更优。特别是在长序列训练场景下,当TorchTitan因为内存不足而无法继续训练时,VeOmni仍能稳定运行并保持良好的性能。
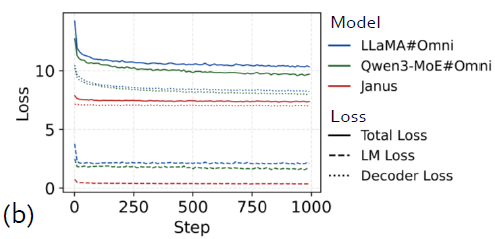
收敛性研究涵盖了三种结构不同的全模态模型,包括Janus、LLaMA#Omni和Qwen3-MoE#Omni。这些模型分别专注于不同的任务组合,从纯图像理解和生成,到跨越文本、图像、视频、音频的全模态处理。实验结果显示,所有模型在使用VeOmni训练时都表现出稳定的收敛行为,验证了框架的可靠性和通用性。
这些实验数据不仅展示了VeOmni在技术指标上的优势,更重要的是证明了其在实际应用中的可行性。研究团队使用了多个领域的真实数据集,包括FineWeb-100T用于文本理解、ShareGPT4V用于图像理解、LLaVA-Video用于视频理解、Voice Assistant用于音频理解,以及ImageNet用于图像生成任务。这种全面的测试确保了VeOmni能够应对真实世界中的复杂训练需求。
VeOmni提供了全模态AI训练中的技术难题的解决思路。
从技术发展的角度来看,VeOmni降低了进行大规模多模态AI研究的门槛。现在,研究人员可以将更多精力投入到模型设计和算法创新上,而不是被系统工程问题所困扰。
在商业应用方面,VeOmni使得更多的公司能够开发自己的全模态AI产品。过去,开发这样的产品需要巨大的技术投入和专业知识,现在中小型公司也能够利用VeOmni快速构建出具有竞争力的AI产品。这种技术民主化可能会催生更多创新的应用场景。
教育领域也将从中受益。VeOmni的简洁设计和清晰文档使其成为优秀的AI教学工具。计算机科学和AI专业的学生可以通过实际操作VeOmni来深入理解分布式机器学习的原理和实践。
从更广泛的社会影响来看,VeOmni可能会加速多模态AI技术的普及和应用。当创建能够同时理解和生成文字、图像、音频、视频的AI系统变得更加容易时,我们可能会看到这些技术在教育、医疗、娱乐、工业设计等各个领域的广泛应用。
论文地址:https://arxiv.org/abs/2508.02317
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
A:VeOmni是一个模块化训练框架,专为加速全模态大语言模型(omni-modal LLMs)开发而设计。它通过模型中心的分布式配方库解耦模型定义与并行逻辑,支持高效3D并行(如FSDP、SP和EP)。例如,在128个GPU上训练30B参数的混合专家模型时,吞吐量超2,800 tokens/sec/GPU。该框架还提供轻量级接口,以最小代码更改集成新模态。
A:VeOmni使用模型中心配方(如FSDP、SP和EP)解耦通信与计算,使不同模态模块(如视觉编码器)可独立处理。它采用轻量接口(基于HuggingFace的PreTrainedModel),简化多模态集成;它的复合架构包括解耦的编码器、基础模型和解码器。灵活并行组合(如FSDP+SP+EP)处理长序列和MoE模型,减少工程开销。
A:实验中,VeOmni在128 GPU上训练30B参数模型时,支持160K上下文长度,吞吐量达2,800+ tokens/sec/GPU。对于7B模型,它能处理192K序列长度,模型浮点利用率(MFU)为61.5%。它的n维并行设计能高效处理数据流和负载平衡。该系统在8-128 GPU规模下优于现有框架(如TorchTitan),确保稳定收敛。