
阿里推出Ovis2.5:多模态大语言模型的又一重要突破 原创
当人工智能遇到视觉理解,会碰撞出怎样的火花?阿里团队最新发布的Ovis2.5多模态大语言模型给出了令人惊艳的答案。
Ovis2.5作为Ovis2的继任者,在视觉感知和多模态推理能力上实现了质的飞跃。这款模型最大的创新在于引入了原生分辨率视觉感知技术,能够以图像的原始分辨率处理图像,避免了传统固定分辨率拼接方法带来的画质损失。更令人兴奋的是,它还具备了一种被称为"思考模式"的深度推理能力,能够进行自我检查和修正,就像一个真正会思考的智能助手。
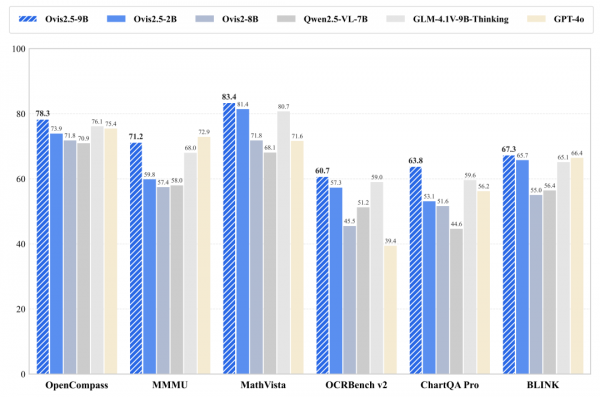
在OpenCompass多模态排行榜上,Ovis2.5-9B以78.3的平均分数创造了新的纪录,在参数少于40B的开源多模态大语言模型中确立了领先地位。而Ovis2.5-2B也以73.9的成绩在同等规模模型中保持了最佳表现,延续了Ovis系列"小模型,大性能"的传统优势。
突破传统视觉理解的技术革新
传统的多模态大语言模型在处理图像时,通常需要将图像切分成固定尺寸的小块,这种做法就像是把一幅完整的画作撕成碎片再重新拼接,不可避免地会破坏图像的整体结构和细节信息。特别是在处理复杂图表、技术图纸等视觉密集内容时,这种方法的局限性更加明显。
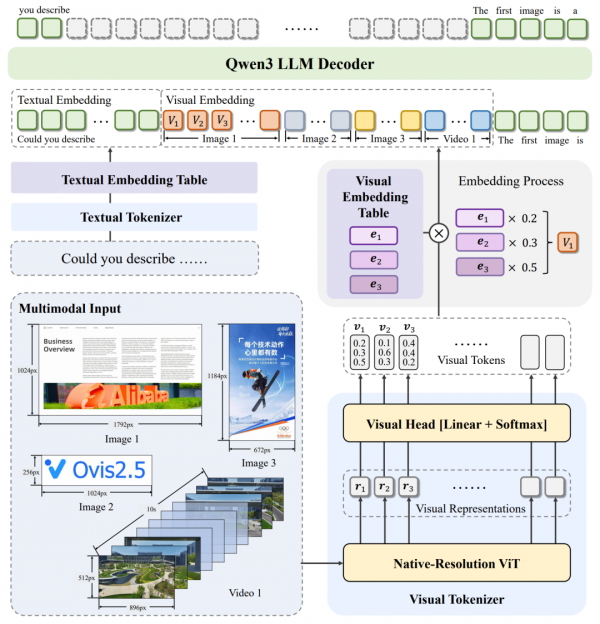
Ovis2.5采用了一种全新的原生分辨率视觉变换器(NaViT),这就像给模型配备了一副能够适应任何画幅尺寸的"智能眼镜"。无论是宽幅的全景图还是高分辨率的详细图表,模型都能以图像的原始分辨率直接处理,保持了图像的完整性和细节丰富度。这种技术在处理包含大量文字信息的图表或复杂图形时表现尤为出色,能够准确捕捉到传统方法容易遗漏的关键信息。
为了增强空间感知能力,研究团队还在每个视觉变换器模块中集成了旋转位置编码(RoPE)技术。这种技术就像为模型提供了一套精密的空间定位系统,让它能够更好地理解图像中各个元素的位置关系,这对于分析高分辨率图像尤其重要。模型的视觉编码器基于siglip2-so400m-patch16-512进行初始化,确保了强大的基础视觉理解能力。
在语言模型层面,Ovis2.5将原有的Qwen2.5升级为Qwen3,这一升级显著提升了模型在复杂任务上的深度推理能力和整体多模态性能。整个架构依然保持了Ovis系列的核心设计理念,包括视觉分词器、视觉嵌入表和大语言模型三个核心模块的协调工作。
革命性的深度推理"思考模式"
Ovis2.5最引人注目的创新是引入了可选的"思考模式"。这种模式让模型具备了类似人类的反思和自我修正能力,不再局限于传统的线性思维链推理。当面对复杂问题时,模型能够进行中间步骤的自我评估,发现推理中的错误并及时纠正,最终得出更加准确和可靠的结论。

这种深度推理能力是通过训练模型学习包含<think>...</think>标签的"思考风格"数据实现的。这些数据教会了模型如何进行反思和自我纠正的高级认知过程。用户可以根据任务的复杂程度选择是否启用这一模式:对于简单任务保持关闭状态以获得更快的响应速度,而对于复杂问题则可以启用该模式,用稍长的处理时间换取更高的准确性。
这种设计哲学体现了研究团队对实际应用场景的深刻理解。在日常使用中,并非所有问题都需要深度思考,但当遇到需要仔细分析的复杂情况时,这种能力就变得极其宝贵。这就像是给AI配备了"快思考"和"慢思考"两种模式,让它能够根据问题的难度自适应地调整思维深度。
系统化的五阶段训练策略
Ovis2.5的卓越性能来源于其精心设计的五阶段训练流程。这个过程就像培养一个全才学生,从基础技能开始,逐步建立起复杂的认知能力。
预训练阶段分为三个递进式步骤。第一阶段专注于视觉嵌入表的训练,使用图像-描述配对数据建立基础的视觉理解能力。在这个阶段,研究团队冻结了大部分参数,只训练最后的视觉变换器层、视觉头部和视觉嵌入表,确保训练的稳定性。图像被调整到特定的像素数量范围(448²到896²像素),同时保持原始宽高比。
第二阶段转向全参数训练,涵盖所有模块以建立核心的视觉理解能力并适应对话格式。训练数据扩展到包括OCR、图像描述和视觉定位任务的对话数据。支持的分辨率范围显著扩大到1792²像素(约320万像素),并激活每个视觉变换器块中的旋转位置编码,以增强模型的空间感知能力。
第三阶段继续全参数训练,重点提升模型遵循多样化多模态指令的能力。训练语料丰富到包含纯文本、多图像和视频等新输入类型,覆盖通用问答、多语言对话、OCR、图表分析、知识问答、STEM和医学等广泛领域。为了培养超越线性思维链的深度推理能力,研究团队加入了带有"思考风格"标签的样本,教会模型进行反思和自我纠正。
后训练阶段包含两个关键步骤。直接偏好优化(DPO)阶段对整个模型进行全参数训练,使用DPO作为主要偏好目标,并辅以负对数似然目标来稳定优化过程。对于每个查询,系统生成多个候选回答,并根据标签形成多个偏好对。
强化学习阶段使用群体相对策略优化(GRPO)进一步提升推理能力,建立在DPO阶段确立的对齐基础之上。为了专注于高级认知优化同时保持通用能力,这个阶段只更新语言模型参数,保持视觉模块冻结状态。
高效训练基础设施的技术突破
训练像Ovis2.5这样的大型多模态模型面临着巨大的基础设施挑战。研究团队开发了针对性的优化方案,实现了3到4倍的端到端训练速度提升。
数据打包技术解决了由于图像、视频和文本数据大小差异导致的计算负载不平衡问题。传统训练中,不同长度的样本需要填充到统一尺寸,这导致了大量的计算浪费和GPU空闲时间,特别是在处理多样化的多模态数据时更加明显。新的数据打包策略将多个较短样本组合成单个较长序列,最小化填充需求,减少计算浪费,并在GPU间创建更平衡的工作负载,直接提升了训练吞吐量。
混合并行框架基于Megatron开发,结合了数据并行、张量并行和上下文并行三种标准技术。这种方法有效减少了大规模模型训练的内存占用,显著提升了训练吞吐量和效率。随着计算密集型视觉主干网络的使用,模型架构规模不断增加,这种先进的并行策略变得至关重要。
全面的性能评估与突出表现
Ovis2.5在多个关键领域都展现出了卓越的性能。在综合性能评估中,使用OpenCompass套件对八个关键基准进行了全面测试,包括MMBench、MMStar、MMMU、MathVista、HallusionBench、AI2D、OCRBench和MMVet。Ovis2.5-9B和Ovis2.5-2B分别获得78.3和73.9的平均分数,在各自规模的开源模型中都实现了最佳表现。
在多模态推理方面,Ovis2.5在视觉和结构化数学任务中表现尤为突出。在MathVista和WeMath基准测试中取得了开源模型的最高排名,展现了在视觉组合和概念整合任务中的卓越能力。在其他数学基准测试如MathVerse、MathVision、LogicVista和DynaMath中也始终排在前两名。除了数学能力,模型在通用学术推理方面的能力也通过MMMU(71.2分)和更具挑战性的MMMU-Pro(54.4分)得到了验证。
OCR和图表分析能力是Ovis2.5的另一个亮点。在大规模双语OCRBench v2测试中,Ovis2.5不仅超越了所有领先的开源竞争对手,甚至在某些指标上超过了专有的GPT-4o模型。这种最先进的性能延伸到了复杂图表分析领域,在新推出的ChartQA Pro基准测试中表现优异,该基准包含从传统图表到复杂信息图的多样化可视化内容。
视觉定位能力的评估通过标准参考表达数据集RefCOCO、RefCOCO+和RefCOCOg进行。Ovis2.5在比较的开源模型中取得了90.1的最佳平均分数。特别值得注意的是,模型在更具挑战性的RefCOCOg数据集上表现突出,该数据集以复杂的非显著对象描述而闻名,Ovis2.5在验证集和测试集上都超越了所有竞争对手。
在多图像和视频理解方面,Ovis2.5展现出了强大的跨模态序列理解能力。在多图像领域,模型在BLINK和MMT-Bench等基准测试中分别获得67.3和69.3的高分,显示出卓越的跨图像推理能力。在视频理解方面,通过VideoMME、MVBench、MLVU和TempCompass等多样化视频基准测试,Ovis2.5保持了强劲且一致的性能表现。
至顶AI实验室洞见
Ovis2.5代表了多模态人工智能发展的重要里程碑。它不仅在技术架构上实现了创新突破,更在实际应用性能上达到了新的高度。模型既保持了Ovis系列的核心优势,又在视觉感知精度、推理深度和处理效率等方面实现了全面提升。这种进步不仅对学术研究具有重要意义,也为多模态AI技术的实际应用开辟了新的可能性。
https://arxiv.org/pdf/2508.11737
Q&A
Q1:Ovis2.5的原生分辨率视觉感知技术有什么优势?
A:Ovis2.5采用的原生分辨率视觉变换器能够以图像的原始分辨率直接处理图像,避免了传统固定分辨率拼接方法造成的画质损失和结构破坏。这种技术特别适合处理复杂图表、技术图纸等视觉密集内容,能够保持图像的完整性和细节丰富度,在高分辨率图像分析中表现尤为出色。
Q2:Ovis2.5的"思考模式"是如何工作的?
A:"思考模式"是Ovis2.5的革命性功能,让模型具备了类似人类的反思和自我修正能力。当启用时,模型会进行中间步骤的自我评估,发现推理错误并及时纠正。用户可以根据任务复杂程度选择是否启用:简单任务关闭以获得快速响应,复杂问题启用以换取更高准确性。
Q3:Ovis2.5在哪些应用场景中表现最突出?
A:Ovis2.5在多个关键领域都表现卓越,特别是在OCR和图表分析、数学推理、视觉定位以及多图像视频理解方面。它在复杂图表解读、学术论文分析、多模态内容理解等需要精细视觉感知和深度推理的场景中具有明显优势,非常适合教育、科研、商业分析等专业应用领域。
来源:至顶AI实验室
好文章,需要你的鼓励



让AI看图功能瘦身90%:希腊塞萨洛尼基大学发现图像修复“中奖彩票“神经网络
希腊塞萨洛尼基大学研究团队开发出MIR-L算法,通过"彩票假说"发现大型图像修复网络中的关键子网络。该算法采用迭代剪枝策略,将网络参数减少90%的同时保持甚至提升修复性能。MIR-L能同时处理去雨、去雾、降噪等多种图片问题,为资源受限设备的实时图像处理提供了高效解决方案,具有重要的实用价值和环保意义。

人工智能使用大揭秘:OpenRouter公司百万亿规模数据分析报告
这项由OpenRouter公司团队和Andreessen Horowitz(a16z)投资机构联合开展的研究,于2025年12月发表。

卡内基梅隆大学提出DistCA:让AI训练告别“木桶效应“的神奇技术
卡内基梅隆大学团队提出DistCA技术,通过分离AI模型中的注意力计算解决长文本训练负载不平衡问题。该技术将计算密集的注意力任务独立调度到专门服务器,配合乒乓执行机制隐藏通信开销,在512个GPU的大规模实验中实现35%的训练加速,为高效长文本AI模型训练提供了新方案。
2025
08/19
15:46
分享
点赞

NVIDIA Nemotron 3 系列开放模型: 击穿AI“工程墙”开启“Agentic AI”的“Linux时刻”
W.AWARDS金网奖2026未来商业计划领航秀峰会收官
人工智能使用大揭秘:OpenRouter公司百万亿规模数据分析报告
智能化与全球化并进,IBM中国下一个40年思考
通用汽车推出原生Apple Music应用并支持空间音频
GMV推进卫星导航技术助力自动驾驶运输与物流发展
英伟达考虑增产H200芯片满足中国市场激增需求
IBM推出开源智能体CUGA 任务完成率超五成
OpenAI支持的生物技术公司Chai Discovery获1.3亿美元B轮融资
八问智能时代:西云数据的八个答案
塑造2026年的八大智能手机趋势
AI架构师荣获《时代》杂志年度人物称号
