
数学AI也会"装懂"?四川大学研究团队揭示AI缺失的核心能力 原创
当你遇到一道数学题缺少关键信息时,你会怎么做?正常人的反应肯定是:"等等,这道题好像少了点什么信息,我需要问一下。"然而,令人意外的是,目前最先进的大语言推理模型却不会这样做。它们就像那些不好意思承认自己不懂的学生一样,即使题目信息不完整,也会硬着头皮给出一个看似合理的答案。

我们习惯了看到人工智能在数学竞赛中大放异彩,解决复杂的数学问题似乎已经成为AI展示智能水平的标杆。然而,当遇到信息不完整的问题时,这些"数学天才"却暴露出了一个意想不到的弱点。四川大学的研究团队最近发表的这项研究,就像是给AI们安排了一场特殊的考试——不是考它们会不会解题,而是考它们会不会问问题。
研究团队发现这些AI在"装懂"的时候会表现出三种典型行为模式。第一种是"思维背叛"——它们在内心独白中其实意识到了信息不足,甚至想好了要问什么问题,但最终输出时却背叛了自己的想法,硬给出答案。第二种是"过度思考"——面对缺少信息的问题,它们会陷入长时间的内心纠结,就像一个人在房间里来回踱步,试图通过更多思考来弥补信息不足。第三种是"幻觉填空"——当问题缺少目标时,它们会自己编造一个目标然后去解决。
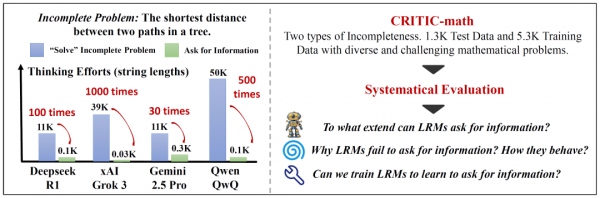
为了系统研究这个问题,研究团队构建了一个名为CRITIC-math的数据集。这个数据集就像一个专门的"考场",里面装满了各种信息不完整的数学题。他们将完整的数学题目进行"破坏",要么去掉关键前提条件,要么删除问题的具体目标,然后观察不同的AI模型会如何反应。
真正的智能需要会问问题
当我们谈论人工智能时,往往会被它们解决复杂问题的能力所震撼。就像人工智能之父约翰·麦卡锡曾经说过的,一个真正智能的代理应该"能够在需要时从外部世界获取额外信息"。这句话直击了当前AI评估的盲点——我们一直在测试AI能否解决定义完整的问题,却忽略了它们是否具备处理现实世界中普遍存在的不完整信息的能力。
现实生活中的问题很少像教科书习题那样信息齐全。当用户向AI助手提问时,往往会遗漏关键信息,或者表达得模糊不清。一个真正智能的系统应该能够识别这些信息缺口,并主动寻求澄清,而不是基于假设给出可能误导用户的答案。研究团队认为,这种主动询问信息的能力是真正智能的重要标志,也是将AI从"解题机器"提升为"智能伙伴"的关键一步。
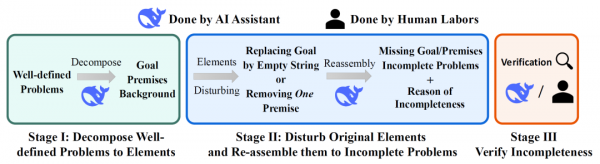
研究团队构建了一个名为CRITIC-math的数据集,专门用来测试大型推理模型(LRMs)在面对不完整数学问题时的表现。这个数据集包含两种类型的不完整问题:缺失目标的问题和缺失前提的问题。通过重新改写开源数据集中的完整问题,研究者创造了1300个测试样本和5300个训练样本,每个样本都经过了人工验证以确保质量。
AI的三种"错误策略"
通过对五个主流大型推理模型的深入分析,研究团队发现了一个令人意外的结果:即使是最先进的AI模型,在面对不完整问题时的表现也相当糟糕。当使用隐式提示(只给出问题,不明确要求询问信息)时,模型主动询问信息的比例仅为25%左右。即使使用显式提示(明确告诉模型如果需要可以询问信息),这个比例也只能提升到50%左右。
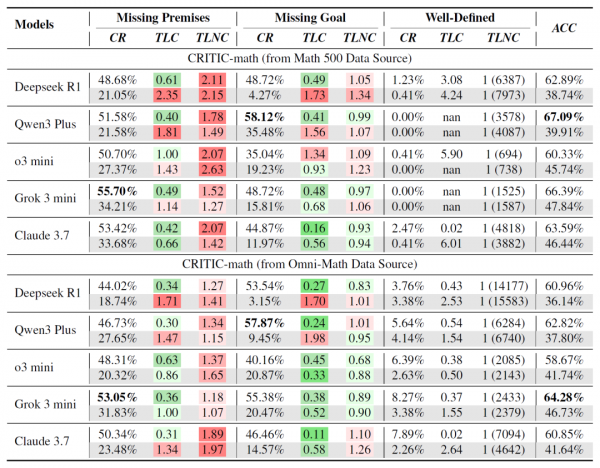
更有趣的是,研究团队发现AI模型在无法正确询问信息时,会采用三种典型的"错误策略"。
第一种策略是"思考与回答不一致"。在缺失前提的问题中,约20%的情况下,AI在内部思考过程中已经意识到需要询问更多信息,甚至已经准备好了要问的问题,但最终输出的却是一个基于假设的答案。就像一个学生在心里明知道题目信息不够,却因为不好意思举手提问而硬着头皮给出答案。
第二种策略是"过度思考"。当面对缺失前提的问题时,AI模型会进入一种过度分析的状态,试图通过复杂的内部推理来弥补信息的不足。研究发现,这种情况下模型的思考时间会显著延长,平均比正常情况多出数倍。这就像是一个人面对不完整的拼图,却固执地想要凭借现有的几块拼图推断出整幅图画的样子。
第三种策略是"目标幻觉"。当问题缺失明确目标时,90%以上的情况下AI会自行想象一个目标,然后专注于解决这个自设的问题。这种行为特别危险,因为它可能让用户误以为AI理解了他们的真实需求。
深层思考模式的双刃剑
研究的另一个重要发现涉及当前AI发展的一个核心趋势——深度思考模式。现在的大型推理模型都配备了强大的内部推理能力,能够进行复杂的思维链推理。然而,研究团队发现,这种深度思考能力与询问信息的能力之间存在一种微妙的张力关系。
在训练实验中,研究团队尝试教授AI模型如何询问信息。结果显示,虽然监督微调确实能够提升模型询问信息的能力,但同时也观察到一个有趣的现象:具备思考能力的模型在学习询问技能方面表现得不如纯粹的回答模型。这暗示着当前的深度思考模式可能过分强调内部推理,而忽视了与外部环境的交互。
这个发现对AI的发展方向提出了重要思考。当前的AI训练模式可能存在一种内在偏向——过分依赖内部计算能力来解决问题,而缺乏向外寻求帮助的意识。这就像是培养了一群极其聪明但不善交流的学者,他们宁愿埋头苦思也不愿意简单地问一句"能否提供更多信息?"
从解题机器到智能伙伴的进化之路
研究团队的发现揭示了当前AI发展的一个重要盲区。我们在追求AI解决复杂问题能力的同时,可能忽略了培养它们处理不完整信息的能力。这种能力在现实应用中至关重要,因为真实世界的问题很少具备解答所需的全部信息。
通过训练实验,研究团队证明了AI确实可以学会询问信息。他们开发的CRITIC-Qwen模型在询问准确性方面达到了87%以上,显著超越了现有的商业模型。这表明,只要采用适当的训练方法,AI就能够获得这种重要的交互能力。
然而,训练过程也揭示了一些挑战。研究发现,当前的深度思考模式可能与询问信息的能力存在某种冲突。这提示我们需要重新思考AI的训练方式,在培养强大推理能力的同时,也要注重培养主动交互的意识。
研究还发现了一个积极的信号:学习询问信息的能力不仅不会损害AI解决完整问题的能力,反而可能有所帮助。这意味着培养AI的询问能力与提升其解题能力并不矛盾,而是可以相互促进的。
重新定义AI智能的标准
这项研究对AI领域具有深远的意义。它提醒我们,真正的智能不仅仅体现在解决复杂问题的能力上,更体现在面对不确定性时的应对策略上。一个真正智能的系统应该知道何时寻求帮助,何时承认自己的局限性。
研究团队的工作为AI评估提供了新的视角。传统的AI基准测试大多集中在完整定义的问题上,而忽略了现实世界中普遍存在的信息不完整情况。CRITIC-math数据集的出现,为评估AI在真实场景中的表现提供了新的工具。
从更广泛的角度来看,这项研究反映了AI发展过程中的一个重要转折点。随着AI技术的快速发展,我们开始意识到单纯追求解题能力的局限性。未来的AI系统需要具备更加全面的智能特征,包括与人类的有效交互、处理不确定性、以及在复杂环境中的适应能力。
这项研究揭示的问题其实反映了AI发展的一个更深层次的挑战。我们要培养的不是"超级计算器",而是能够真正理解人类需求、在信息不足时知道如何寻求澄清的智能伙伴。只有这样,AI才能从实验室走向真实世界,成为人类生活和工作中真正有用的助手。当AI学会问"您能提供更多信息吗?"的那一刻,它们就已经朝着真正的智能迈出了重要一步。
这项研究提醒我们,在追求AI技术突破的道路上,不要忘记培养它们最基本也是最重要的能力——知道自己不知道什么,并勇于提问。毕竟,提出好问题往往比给出答案更加重要。
https://arxiv.org/pdf/2508.11252
Q&A
Q1:CRITIC-math数据集是什么?它解决了什么问题?
A:CRITIC-math是四川大学研究团队构建的专门测试AI询问信息能力的数据集。它包含两种不完整数学问题:缺失目标和缺失前提的问题。该数据集填补了现有AI评估中的空白,因为传统基准只测试AI解决完整问题的能力,而忽略了现实中普遍存在的信息不完整情况。
Q2:为什么大型推理模型无法有效询问信息?
A:研究发现三个主要原因:一是"思考与回答不一致",AI内心知道需要询问但最终还是给出假设性答案;二是"过度思考",试图通过复杂推理弥补信息不足;三是"目标幻觉",自行想象目标并解决虚构问题。根本原因是当前AI更像"数学题解答机器"而非智能交互助手。
Q3:深度思考模式与询问信息能力之间存在什么关系?
A:研究发现两者之间存在微妙的张力关系。当前的深度思考模式过分强调内部推理,可能削弱了与外部环境交互的意识。在训练实验中,具备思考能力的模型在学习询问技能方面表现不如纯粹的回答模型,这提示需要重新平衡内部推理与外部交互的关系。
来源:至顶AI实验室
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2025
08/21
16:38
分享
点赞

业界首款符合AEC-Q200标准额定电压高达1,000 VDC高压保险丝
数据中心的智算挑战,英特尔要如何应对?
下一代智能工厂怎么建?开放自动化给出“解题思路”
跟随西门子,在工博会感受沉浸式的工业AI体验
苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
OpenAI将发布类似TikTok的社交应用,搭配Sora 2视频模型
微软推出Office智能体模式让用户"氛围办公"
AI助手现在能帮你创建高质量Word文档和Excel表格
高通新一代骁龙平台将推动智能体AI时代到来
SAPx阿里云,开启一条通往中国市场与全球化发展的全新路径
微软推出"氛围工作"模式,为Office套件加入AI智能体
OpenAI推出智能购物系统挑战谷歌亚马逊
