Google DeepMind发现AI搜索的数学局限 原创
Google DeepMind发现AI搜索的数学局限
2025年8月28日,Google DeepMind研究团队发现了现代AI搜索技术的根本数学局限:向量嵌入模型无法表示所有可能的文档组合,即使面对极简单的查询也可能失效。他们创建的LIMIT数据集显示,最先进的神经网络模型在基础的"谁喜欢什么"问题上表现糟糕,而传统BM25算法反而近乎完美。研究指出未来需要混合架构而非单一技术来构建更强大的搜索系统。相关论文发布在arXiv上。
首先我们需要理解现代搜索引擎是如何工作的。过去二十年里,信息检索技术经历了一场革命性变化,从早期简单的关键词匹配(就像在字典里查单词)发展到今天基于神经网络的智能搜索。现在的搜索系统使用向量嵌入技术:简单来说,就是把所有的文字信息都转换成数字,然后装进一个多维的"盒子"(向量空间)里。
这种方法很聪明:每个文档和每个查询都被转换成一串数字(就像每个人都有一个独特的身份证号码),然后通过计算这些数字之间的相似度来判断哪些文档最相关。这就像是给每个信息贴上一个多维的"标签",搜索时只需要找到标签最匹配的信息就行了。
然而,这种看似完美的系统却有一个致命的弱点:向量空间的容量是有限的。就像你家里的收纳盒再大,也不可能装下所有可能的物品组合。Google DeepMind的研究团队首次用严格的数学理论证明了这一点,无论你的"盒子"有多大,总会有一些信息组合是装不下的。
近年来,搜索任务变得越来越复杂。现在的AI系统被要求处理各种复杂指令,比如"找到既是1849年出版的小说,又是乔治·桑德写的作品",或者"找到使用动态规划算法的编程题目"。这些任务要求AI能够理解和组合各种不同的概念,就像要求一个收纳师不仅要整理物品,还要能快速找出各种复杂的物品组合。
研究团队运用了一种叫做符号秩(sign rank)的数学概念。这个用收纳来解释就容易理解了:假设你有一个收纳盒,你想要存放各种物品的组合(比如红色圆形物品、蓝色方形物品等等)。符号秩就是告诉你,要完美存放所有可能的组合,你的收纳盒至少需要多少个隔间。
具体来说,研究团队建立了一个严格的数学框架。他们把搜索问题想象成一个巨大的表格:横轴是所有可能的文档,纵轴是所有可能的查询,表格中的每个格子表示某个文档对某个查询是否相关。这就像是一个超级复杂的物品清单,标记着哪些物品组合应该被归类在一起。
研究团队证明了一个关键定理:对于任何给定的"盒子大小"(嵌入维度d),都存在一些物品组合是无法完美存放的。更惊人的是,他们不仅在理论上证明了这一点,还通过实验验证了这个结论。他们设计了一种"理想情况"的实验:让AI直接优化这些数字表示,相当于给了AI一个作弊的机会,让它可以随意调整自己的"收纳方式"。
即使在这种理想条件下,实验结果也清楚地显示了容量瓶颈的存在。研究团队发现,当文档数量达到一个临界点时,无论怎样优化,AI都无法正确处理所有的查询组合。更令人担忧的是,对于真实的网络搜索场景,这个临界点来得比想象中更早,即使是拥有最大嵌入维度的模型,在理想测试集优化条件下,也无法处理真正的网络规模搜索。
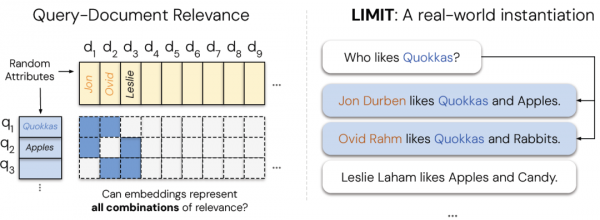
为了验证这些理论发现在现实中的表现,研究团队建立名为LIMIT的测试数据集。这个数据集的设计思路非常巧妙:它故意避开了复杂的查询操作符或高深的推理要求,而是专注于测试最基本的信息组合能力。
LIMIT数据集的构建过程就像设计一个看似简单却暗藏机关的智力测试。研究团队创建了一个虚拟的社交网络,里面有各种虚拟人物,每个人都有自己喜欢的事物。比如"乔恩·德本喜欢袋鼠和苹果","奥维德·拉姆喜欢袋鼠和兔子","莱斯利·拉汉姆喜欢苹果和糖果"。然后,测试的问题简单得令人发指:"谁喜欢袋鼠?"或者"谁喜欢苹果?"
这些问题简单到连小学生都能秒答,但当研究团队把它们交给目前最先进的AI搜索模型时,意外的结果出现了。这些在其他复杂任务上表现优异的模型,在LIMIT数据集上的表现很差,甚至连20%的准确率都达不到。
这种现象的根本原因在于LIMIT数据集的精心设计:它要求模型能够处理所有可能的"谁喜欢什么"的组合。虽然每个单独的问题都很简单,但当所有可能的组合放在一起时,就超出了现有嵌入模型的表示能力。这就像要求一个收纳师不仅要整理好每一类物品,还要能快速找出任何指定的物品组合,看似简单,实际上对收纳系统的要求极高。
研究团队在实验中测试了多个顶级模型,包括GritLM、Qwen 3 Embeddings、Promptriever、Gemini Embeddings、Snowflake Arctic Embed和E5-Mistral等。令人意外的是,传统的BM25搜索算法(一种基于关键词匹配的方法)在这个测试中表现优异,而神经网络模型却表现糟糕。这个对比就像发现,在某些特定的收纳任务中,传统的分类标签系统反而比最新的智能整理机器人更有效。
研究团队的实验还揭示了另一个重要发现:模型的嵌入维度(可以理解为"收纳盒的隔间数量")确实影响性能,但影响方式不是线性的,而是遵循一个复杂的数学曲线。
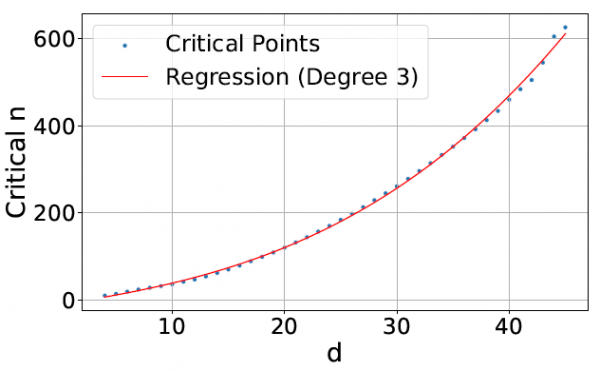
通过"自由嵌入"实验(让AI可以自由调整自己的数字表示方式),研究团队绘制出了一条曲线。这条曲线显示,要处理不同数量的文档组合,需要的嵌入维度呈指数级增长。具体来说,他们发现了一个临界点公式:y = -10.5322 + 4.0309d + 0.0520d² + 0.0037d³(其中d是嵌入维度,y是能够处理的文档数量)。
按照这个公式外推,即使是拥有512维嵌入的模型,也只能完美处理约50万个文档的组合;1024维的模型能处理170万个;而即使是4096维的超大模型,也只能处理2.5亿个文档组合。这听起来已经很多了,但考虑到真实的网络搜索需要处理数十亿甚至数万亿的文档组合,这个容量显然远远不够。
更令人担忧的是,这还是在"理想条件"下的表现,实际的搜索模型还要受到自然语言本身的约束,无法像实验中那样自由调整数字表示,因此实际性能会更差。
研究团队还测试了不同类型的查询-文档关系模式对模型性能的影响。他们设计了四种不同的"整理策略":随机模式(随机选择相关文档)、循环模式(按规律轮转)、分离模式(相关文档完全不重叠)和密集模式(最大化文档间的关联)。
实验结果显示,前三种模式下,各个模型的表现相对正常。但当切换到密集模式时,所有模型的性能都出现断崖式下跌。以GritLM模型为例,从随机模式的50分直接跌落到密集模式的10分,性能降低了80%。这个结果证实了研究团队的理论预测:当信息之间的关联变得复杂和密集时,现有的嵌入模型就会力不从心。
这种现象的本质是,密集关联的信息需要更高维度的表示空间。就像如果你的物品之间有很多复杂的关联关系(比如有些物品必须成对出现,有些物品不能放在一起),你就需要一个更复杂的收纳系统才能完美管理它们。
LIMIT数据集的设计原理基于一个深刻的观察:现有的搜索评测数据集实际上只测试了所有可能查询中极其微小的一部分。研究团队以QUEST数据集为例进行了计算:该数据集有32.5万个文档,每个查询有20个相关文档,总共只有3357个查询。但理论上,这个文档集可能产生的不同top-20文档组合数量是7.1×10^91,这个数字比可观测宇宙中原子的估计数量(10^82)还要大。换句话说,现有的评测只覆盖了理论上可能出现的查询组合中微不足道的一小部分。
正因如此,现有的AI模型虽然在标准评测中表现优异,但这种优异很可能是虚假的,它们只是恰好在那一小部分被测试的组合上表现良好,而对于其他未被测试的组合可能完全无能为力。这就像一个收纳师只学会了整理展示柜里的那几样物品,却无法处理现实生活中千变万化的整理需求。
为了验证这个猜想,研究团队设计了LIMIT数据集。这个数据集包含5万个文档和1000个查询,每个查询要求找到2个相关文档。文档内容极其简单,就是记录各种虚拟人物的喜好,而查询也简单到不能再简单:"谁喜欢某某东西?"。
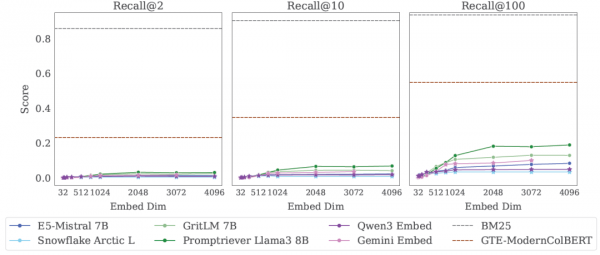
然而,当这些看似幼稚的问题被交给最先进的AI模型时,结果让人大跌眼镜。即使是在标准评测中表现最好的模型,在LIMIT数据集上的表现也惨不忍睹。最好的神经网络模型在recall@100指标上的得分不到20%,而传统的BM25算法却轻松达到了90%以上的准确率。
研究团队的实验还揭示了一个有趣的现象:模型的性能确实随着嵌入维度的增加而提升,但这种提升遵循一个特定的模式,而且存在明显的瓶颈。
在测试中,研究团队比较了从32维到4096维的各种模型。结果显示,虽然维度越高的模型表现越好,但即使是4096维的超大模型,在LIMIT数据集上的表现仍然远远低于传统方法。这说明问题不仅仅是"盒子不够大",而是"装盒子的方式"本身有问题。
更重要的是,研究团队发现了模型训练方式对性能的影响。那些使用了"俄罗斯套娃"式训练(Matryoshka Representation Learning,简称MRL)的模型在小维度下表现更好,而那些专门针对指令跟随进行训练的模型(如Promptriever)在整体上表现更佳。这表明训练策略的多样性能帮助模型更好地利用其嵌入空间。
面对这些根本性局限,研究团队也探索了一些可能的解决方案。他们测试了三种不同的技术路线,每种都有其独特的优势和局限。
第一种是"交叉编码器"(Cross-Encoders)。这种方法不再试图把所有信息都装进固定的"盒子"里,而是针对每个具体查询动态地比较文档。研究团队用Gemini-2.5-Pro模型进行测试,结果令人振奋:这个模型能够完美解决LIMIT数据集中的所有1000个查询,准确率达到100%。这就像雇佣一个专业整理师,不用预先分类物品,而是根据你的具体需求现场整理。然而,这种方法的代价是计算成本极高,无法应用于大规模的实时搜索。
第二种是"多向量模型"(Multi-vector models)。这些模型不再用单一的数字串来表示每个文档,而是用多个数字串的组合。这就像用多个小盒子来代替一个大盒子,提供了更灵活的存储方式。测试中的GTE-ModernColBERT模型确实比单向量模型表现更好,但仍然远未达到完美水平。而且,这类模型通常不被用于指令跟随或推理任务,其在更复杂任务上的表现还是未知数。
第三种是"稀疏模型"(Sparse models),包括传统的BM25等。这些模型可以被看作是拥有超高维度的单向量模型。正因为维度极高,它们能够处理比神经网络模型更多的组合。在LIMIT测试中,BM25的表现几乎完美,这解释了为什么这种"老古董"技术至今仍在许多实际应用中占有一席之地。但问题是,这类模型很难处理那些需要语义理解或推理的复杂任务。
本次研究揭示了当前主流AI搜索技术存在一个根本性的盲区。我们长期以来追求的更大、更强的单向量嵌入模型,在处理包含多个属性或概念的复杂组合查询时,存在着内在的“表示能力”瓶颈。这解释了为何许多看似强大的AI系统在处理一些复合型查询时会频繁出错,其根源并非程序bug,而是技术路线本身的天生局限。
未来的技术突破点不应是继续盲目地扩大单一模型,而应转向构建一个多元化、智能化的混合技术系统。未来的搜索引擎需要像一个专业的工具箱,能够根据查询任务的复杂性,智能地选择并组合最高效的技术方案:用稀疏模型处理简单关键词,用神经网络处理语义理解,用更强大的交叉编码器等处理复杂推理。
信息检索领域正从对单一模型的依赖,转向一个更加务实和高效的多技术、分层处理架构。真正的进步并非一味追求“更大更强”,而是深入理解技术的本质局限,并为此设计出更巧妙、更具适应性的解决方案。
论文地址:https://arxiv.org/abs/2508.21038
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
A:向量嵌入就像给每个信息贴上一个多维的数字标签,搜索时通过比较标签的相似度来找相关内容。它的局限性在于这些"标签盒子"的容量有限,当信息组合过于复杂时就装不下了,就像再大的收纳盒也有装不完所有物品组合的时候。
A:LIMIT虽然问题简单(比如"谁喜欢苹果?"),但它测试的是AI处理所有可能组合的能力。虽然单个问题很容易,但当所有可能的"谁喜欢什么"组合放在一起时,就超出了现有AI模型的表示能力,这是一个根本性的数学局限。
A:短期内影响不大,因为日常搜索大多不会触及这些极限情况。但随着AI助手变得更复杂,用户查询变得更多样化,这些局限可能会导致一些看似简单的复合查询得不到准确答案。未来的搜索系统需要采用混合技术来克服这些限制。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
Aqara Hub M200是进入Aqara生态系统的新入口,作为支持Matter的Zigbee 3.0中枢,可将传感器、开关、按钮等配件通过Matter共享到HomeKit。相比Hub M3设计更紧凑,支持2.4和5GHz双频Wi-Fi。M200充分利用Zigbee协议的低成本优势,让用户以更实惠的价格构建智能家居,同时享受完整的HomeKit功能。对于HomeKit用户来说,这是一个稳定可靠的桥接方案。
腾讯AI实验室联合港校提出RePlan框架,解决复杂图像编辑中的指令理解和精确定位难题。该方法采用"计划-执行"架构,让视觉语言模型先推理制定区域级编辑计划,再通过创新的注意力机制精确执行。仅用1000个样本训练就超越了大规模数据训练的模型,在新建的IV-Edit基准上表现出色。
LG电视通过系统更新强制安装微软Copilot快捷方式引发争议。虽然LG承诺将允许用户删除该图标,但仍计划在webOS系统中深度整合Copilot功能。三星等厂商也在推进类似AI功能。专家指出,智能电视内置聊天机器人会增加隐私追踪的复杂性,加剧系统臃肿问题。当前智能电视行业正通过用户追踪和广告实现软件盈利,消费者应关注隐私保护问题。
这项由香港科技大学等机构联合完成的研究首次让AI获得了原生的3D空间理解能力。N3D-VLM系统能够像人类一样准确感知物体的立体位置关系,先精确定位物体的3D边界框,再进行空间推理。研究团队还开发了巧妙的数据生成方法,将2D标注转换为278万个3D样本,并构建了全新的N3D-Bench测试基准。实验显示该系统在空间推理任务上准确率超过90%,远超现有方法,为机器人、自动驾驶等领域提供了重要技术突破。