模型越大,长期执行力越强,剑桥团队指出传统基准测试过时 原创
模型越大,长期执行力越强,剑桥团队指出传统基准测试过时
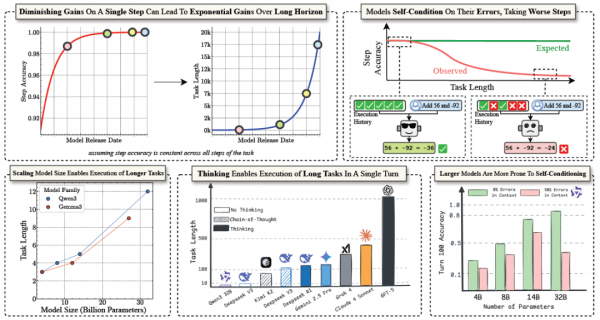
2025年9月11日,剑桥大学等机构研究团队发现,AI模型单步准确率的微小提升会在长期任务中产生指数级性能增长。他们通过简单的键值查找任务,分离出纯粹的执行能力进行测试,发现更大模型具有显著优势。研究还揭示了"自条件化效应",模型会被自身历史错误影响,导致后续步骤更易出错。不过,具备推理能力的模型能够避免这一问题,在长期任务执行上表现卓越。相关论文发表于ArXiv。
研究的核心发现可以用一个学习场景来理解。设想一个学生在做数学题,单道题目的准确率从90%提升到95%,看起来只是微小的5%改进。但是,当这个学生需要连续做100道题,且每道题都不能出错时,情况就完全不同了。90%准确率的学生,连续做对100道题的概率几乎为零,而95%准确率的学生,成功的可能性要高出数千倍。研究团队正是发现了AI模型中存在这样的"复合效应":看似微小的单步改进,会在长期任务中产生指数级的性能提升。
在现实世界中,AI的价值往往不在于回答单个问题,而在于完成复杂、耗时的长期任务。就像一个秘书不仅要会打字,更要能完成整个项目的文档管理一样,真正有用的AI助手需要能够持续、准确地执行多个步骤的复杂任务。
传统的AI评测往往关注"单题准确率",看模型能否正确回答一个问题或完成一个简单任务。但研究团队注意到,当任务变长时,即使是最先进的模型也会频繁失败。
更有趣的是,研究人员发现这种失败并非来自知识不足或推理能力缺陷,而是出现在"执行"环节。什么是执行?可以把它理解为按照已知的方法和步骤,一步步完成任务的能力。就像学生已经知道解题方法,也理解题目要求,但在实际操作过程中却会出现计算错误、步骤遗漏等问题。
研究团队观察到一个关键现象:当简单的任务被拉长时,模型的失败并不是因为不知道怎么做,而是在执行过程中出现了意外错误。这种现象在人类身上也很常见,我们都知道如何走路,但如果要求连续走很长的距离,就可能因为疲劳或注意力分散而摔倒。
为了准确研究AI的执行能力,研究团队设计了一个极其巧妙的实验。他们想要分离出纯粹的"执行"能力。
研究人员创建了一个看似简单的任务:给AI模型提供一个"字典",里面包含许多英文单词和对应的数字。比如"apple"对应数字5,"banana"对应数字-3等等。然后,研究人员会依次给出一些单词,要求模型查找对应的数字并累加,保持一个运行总数。
这个任务的巧妙之处在于,它完全消除了知识和规划的要求。模型不需要调用复杂的背景知识,也不需要制定复杂的计划,只需要重复执行两个简单操作:查找数字,然后加法。每个单独的步骤都极其简单,任何稍微训练过的模型都能轻松完成。
通过这种设计,研究人员可以纯粹地观察模型在长期执行过程中的表现变化,而不受其他复杂因素干扰。
实验中,研究团队测试了多个不同规模的模型,从小型的40亿参数模型到大型的320亿参数模型。他们让这些模型执行不同长度的任务,有时只需要做几步,有时需要连续执行数百步。
实验结果惊人。即使在这样一个看似简单的任务上,模型的表现也出现了显著的差异。最小的模型很快就开始出错,而最大的模型能够持续准确执行更多的步骤。
更重要的是,这种差异并不遵循我们常见的"递减收益"规律。通常情况下,当我们增加投资时,回报会逐渐递减,第一百万带来的收益比第二百万大。但在长期执行任务上,模型规模的收益似乎并不递减,甚至可能递增。
研究人员通过数学推导证明了一个重要结论:假设模型的单步准确率为p,那么它能够以50%成功率完成的任务长度大约是-ln(2)/ln(p)。这个公式揭示了一个惊人的数学现象:当p接近1(即准确率接近100%)时,任务长度会急剧增长。
具体来说,如果一个模型的单步准确率从90%提升到95%,它能完成的任务长度会从大约7步跃升到14步,翻了一倍。如果准确率继续提升到99%,任务长度会达到约69步。这种指数级增长意味着,即使单步准确率的改进看起来很小,在长期任务上的收益却是巨大的。
这解释了为什么更大的模型在长期任务上表现如此出色。虽然大模型在单个问题上可能只比小模型好一点点,但这微小的差异在长期任务中会被无限放大。
研究过程中,研究团队发现了一个更加有趣的现象。按理说,如果模型在每个步骤上都有固定的出错概率,那么整体性能应该是稳定衰减的。但实际观察到的情况却不是这样,模型的单步准确率会随着任务进展而逐渐下降。
这就像一个学生在考试中,做前几道题时状态很好,但随着时间推移,特别是发现前面有错误后,后面的题目反而更容易出错。研究人员将这种现象称为"自条件化效应"(self-conditioning effect)。
为了验证这个假设,研究团队设计了一个巧妙的对比实验。他们人为地控制了模型能够"看到"的历史记录中的错误率。结果发现,当历史记录中错误较多时,模型在后续步骤中也更容易出错;而当历史记录是完全正确的时候,模型的表现就会好得多。
这种现象可能源于大语言模型的训练机制。这些模型被训练来预测"最可能的下一个词",因此它们会根据上下文来调整自己的输出。当上下文中包含错误时,模型可能会认为"出错"在当前情境下是合理的,从而增加了继续出错的概率。
这就像一个学生发现自己前面的答案可能有问题后,信心开始动摇,结果后面本来会做的题目也开始出错。这种心理影响在人类身上很常见,没想到AI模型中也存在类似的"心理现象"。
意外的是,增大模型规模并不能解决这个问题。研究团队测试了包括千亿参数级别的最新模型,发现即使是这些"超级模型"也会受到自条件化效应的影响。当它们看到充满错误的历史记录时,表现同样会显著下降。
正当研究人员为这个"自我设限"问题困扰时,他们发现了一个有效的解决方案:让模型"推理"。
所谓的推理模型,就是在给出最终答案前,先让模型展示详细的推理过程。这就像要求学生不仅写出答案,还要写出完整的解题步骤一样。研究发现,当模型被要求展示思考过程时,自条件化效应几乎完全消失了。
这种现象有两个可能的解释。首先,推理过程让模型能够重新审视问题,而不是简单地延续之前可能错误的模式。就像学生在详细写解题步骤时,会重新思考每一步是否正确,而不是匆忙给出答案。
其次,推理模型通常经过特殊的强化学习训练,使其更关注任务成功而非单纯的文本延续。这改变了模型的行为动机,让它更像一个专注于解决问题的学生,而不是一个只会模仿文本模式的复读机。
研究结果显示,推理模型不仅能够避免自条件化陷阱,在长期任务执行上的能力也大幅提升。一些原本只能执行几个步骤的模型,在启用推理模式后能够连续准确执行数百个步骤。
研究团队对当前最先进的AI模型进行了全面测试,结果形成了一个有趣的排行榜。在单轮执行能力测试中,不同模型展现出了显著的差异。
GPT-5模型(代号"Horizon")表现最为出色,能够在单轮中准确执行超过1000个步骤,这相当于连续做对1000道基础数学题而不出错。Claude-4-Sonnet紧随其后,能够执行约432个步骤。其他模型如Grok-4、Gemini 2.5 Pro等,虽然在日常对话中表现优秀,但在这种长期执行任务上相对逊色。
这种差异并非偶然。研究发现,经过强化学习训练的推理模型在长期执行任务上具有显著优势。而那些主要针对对话优化的模型,虽然在单轮交互中表现出色,但在需要持续专注的长期任务上则表现一般。
更有趣的是,研究人员发现,在没有思考过程的情况下,即使是最大的模型也很难连续执行超过两个步骤的复杂操作。这说明"思考过程"对于复杂任务执行的重要性,就像人类在处理复杂问题时也需要仔细思考每一个步骤。
研究团队提出了一个有趣的观点:如果AI的经济价值主要来自于完成长期任务的能力,那么专注于短期基准测试可能会给我们一种"进步放缓"的错觉,而实际上在真正重要的维度上,进步可能比以往任何时候都快。
在现实应用中,AI系统经常需要执行长期、复杂的任务,比如编写完整的软件程序、处理复杂的客户服务流程、或者管理长期的项目计划。传统的短期评测指标可能严重低估了模型规模扩大的价值。一个在简单问答中只比竞争对手好一点点的模型,在长期任务中可能会表现出压倒性的优势。
对于AI行业的发展策略,研究建议继续投资于模型规模的扩大,同时特别关注推理能力的培养。单纯追求对话流畅性或知识广度可能不是最佳策略,培养模型的长期专注执行能力可能更有价值。
AI安全维度上,自条件化效应意味着,一个在短期测试中表现良好的模型,在长期部署中可能会因为累积错误而表现糟糕。提醒我们需要设计更好的错误恢复机制和上下文管理策略。
或许我们需要重新思考什么是AI的"真正能力",以及如何衡量AI投资的回报。就像评价一个员工不能只看他答题的准确率,更要看他能否持续、可靠地完成复杂工作一样。
对于普通用户而言,选择AI工具时,不要只关注它在演示中的表现,更要关注它在长期使用中的可靠性和一致性。一个能够持续提供准确帮助的AI助手,远比一个偶尔表现出色但不够稳定的系统更有价值。
在AI的世界里,"积少成多"和"滴水穿石"的道理同样适用,微小的改进可能产生巨大的影响,而持久的专注可能比瞬间的聪明更有价值。
论文地址:https://www.arxiv.org/abs/2509.09677
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q1:什么是"自条件化效应"?这对AI有什么影响?
A:自条件化效应是指AI模型会被自己之前的错误影响,导致后续步骤更容易出错。就像学生发现前面答错题后信心动摇,后面本来会的题也开始出错。这种效应会让AI在长期任务中表现越来越差,即使单个步骤本身很简单。
A:虽然大模型在单个问题上可能只比小模型好一点点,但这微小差异在长期任务中会被放大。研究发现,单步准确率从90%提升到95%,能完成的任务长度会翻倍。这种数学上的复合效应让看似微小的改进产生巨大影响。
A:推理模型是指在给出答案前会展示详细推理过程的AI模型。研究发现这类模型不会受到"自条件化效应"影响,能够连续准确执行数百个步骤。它们就像会仔细写解题过程的好学生,每步都会重新思考,而不是盲目延续可能错误的模式。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
在信息爆炸的时代,AI实验室的研究员们常常需要面对海量的论文、专利文件、论坛发言等各种渠道的信息。传统的查找方式不仅费时费力,还容易遗漏关键内容。那么,有没有一种方式能让AI真正代替人工,完成从找资料到写出稿的全流程工作?
这项由蚂蚁集团、香港科技大学等机构研究者完成的工作提出了Ditto框架,通过创新的数据生成管道解决了视频编辑领域的数据稀缺问题。研究团队生成了包含一百万个高质量视频编辑样本的Ditto-1M数据集,并基于此训练了Editto模型。该模型在多项评估中显著超越现有方法,实现了更精准的指令遵循和更好的时间一致性,为指令驱动的视频编辑树立了新的技术标杆。
当我们还在讨论AI能否真正融入生活时,有些产品已经悄然给出了答案。
这项由阿里巴巴和中科院联合完成的研究提出了ImagerySearch,一种创新的视频生成方法,能够帮助AI生成更好的创意和想象力十足的视频。研究团队还创建了LDT-Bench,首个专门评估AI在处理奇异场景能力的基准。实验表明,ImagerySearch在处理创意场景时相比现有方法有显著提升,为AI创意内容生成开辟了新的方向。











