
嵌套学习:谷歌又一个Transformer级别的研究?AI学习就像做梦一样层层嵌套 原创

人类可以一边聊天一边记住新朋友的名字,而ChatGPT却像个健忘症患者,聊完就忘,下次见面还得从头介绍自己?这个看似简单的问题,其实困扰着全世界最聪明的AI研究者们。

2025年11月,谷歌研究院的科学家Ali Behrouz、Meisam Razaviyayn、Peiling Zhong和Vahab Mirrokni在神经信息处理系统大会NeurIPS 2025上发表了一篇论文,提出了嵌套学习(Nested Learning)新理论框架,就像给AI的大脑做了一次CT扫描,让我们清晰地看到了深度学习内部那些隐藏的层层结构。
从失忆症说起:为什么AI总是记不住新东西
想象一下有这样一个人:他记得自己出生后到某个时间点之前的所有事情,但从那个时间点之后,他就再也无法形成新的长期记忆了。每天早上醒来,他都不记得昨天发生了什么,只能不断重复体验着当下这个短暂的时刻。这种情况在医学上叫做顺行性遗忘症,最著名的案例就是电影《记忆碎片》中的主角。
谷歌的研究团队发现,现在的大型语言模型(比如ChatGPT、Gemini这些)其实就患有一种数字版的顺行性遗忘症。这些AI的知识被分成两块:一块是远古记忆,也就是在训练阶段学到的东西,被牢牢锁在模型的参数里;另一块是即时记忆,也就是当前对话窗口里的内容。问题是,这两块记忆之间有一道无法逾越的鸿沟,对话窗口里的新信息永远无法真正写入到模型的长期存储中去。
这就好比你有一个超级学霸朋友,他上学时候学的东西都记得清清楚楚,但毕业后就再也学不会任何新知识了。你告诉他今年的诺贝尔奖得主是谁,他当时能记住,但下次见面又忘了。这显然不是真正的智能,对吧?
大脑的智慧:为什么人类不会毕业即失忆
为了解决这个问题,研究团队把目光投向了人类大脑。神经科学家们发现,人脑之所以能持续学习新东西,靠的是一种叫做神经可塑性的能力,大脑可以根据新的经历不断重塑自己。更有趣的是,记忆的形成并不是一步到位的,而是分成两个阶段。
第一个阶段叫在线巩固,发生在学习之后很短的时间内,甚至在清醒状态下就开始了。这就像你刚学会一首新歌,哼着哼着就越来越熟练。第二个阶段叫离线巩固,主要发生在睡眠期间。你有没有过这种经历:晚上背单词怎么都记不住,睡一觉起来突然就记住了?这就是离线巩固在起作用,大脑在你睡觉的时候偷偷复习白天学的内容,把它们从临时文件夹转移到永久存档里。
研究团队特别关注的是第一个阶段,因为这是现有AI最缺失的能力。他们发现,人脑的秘密武器有两个:一是统一且可重复使用的结构,大脑各个部分的基本构造都差不多,就像乐高积木一样可以灵活组合;二是多时间尺度更新,不同的神经元以不同的频率更新自己的状态,有的像蜂鸟翅膀一样快速振动,有的像树懒一样慢悠悠地变化。
这两个特点合在一起,让大脑能够同时处理刚才发生的事和很久以前学到的知识,而且能够让它们互相影响、互相更新。这就像一个管理良好的公司,有处理日常事务的前线员工,也有制定长期战略的高层管理者,大家各司其职又密切配合。
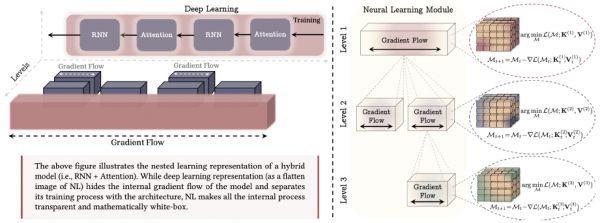
揭开俄罗斯套娃:什么是嵌套学习
现在我们来到了这篇论文最核心的部分。研究团队提出了一个全新的视角来理解深度学习,他们把它叫做"嵌套学习"。这个名字非常形象就像俄罗斯套娃一样,层层嵌套,每一层都有自己的生命。
传统的深度学习观点认为,神经网络就是一堆层叠在一起的处理单元,信息从底层流向顶层,然后输出结果。这个观点没错,但它就像只看到了俄罗斯套娃的外表,而没有打开看看里面有什么。嵌套学习的观点则是:每一个处理单元本身就是一个完整的学习系统,有自己的学习目标、学习规则和学习节奏。
让我用做饭来打个比方。传统观点认为,做一道菜就是按顺序执行一系列步骤:洗菜、切菜、炒菜、调味、装盘。但嵌套学习的观点是:每个步骤本身都是一门学问。比如切菜这个步骤,厨师需要根据食材的特性、菜肴的要求、自己的刀工水平等因素,不断调整切法,这本身就是一个学习如何切菜的过程。同样,调味也不是机械地加盐加糖,而是品尝、调整、再品尝、再调整的学习过程。整道菜的烹饪,其实是由一系列相互嵌套的学习过程组成的。
在神经网络的世界里,这个道理同样适用。以往我们以为训练神经网络是一个单一的过程,但嵌套学习告诉我们,这个过程内部其实包含着多个层次的小型学习。有的学习发生在每个时间步(比如处理每一个单词),有的学习发生在每个批次(比如更新一次参数),有的学习发生在整个训练过程中(比如从头训练到结束)。这些不同层次的学习相互嵌套、相互影响,共同构成了我们看到的深度学习。
联想记忆:AI学习的基本单元
要理解嵌套学习的精髓,我们需要先理解一个基础概念:联想记忆。这个概念听起来很学术,但其实我们每天都在使用它。
想象你闻到一股烤面包的香味,突然想起了小时候奶奶家的厨房,这就是联想记忆在起作用。你的大脑把烤面包香这个钥匙和奶奶家厨房这个宝藏关联在一起,当钥匙出现时,宝藏就被自动打开了。
在数学上,联想记忆可以被描述为一种映射,给定一组"钥匙"和一组"宝藏",联想记忆就是学会如何从钥匙找到对应的宝藏。看起来很简单,但这个简单的概念却是理解所有学习过程的关键。
研究团队指出了一个重要的区别:记忆和学习是两回事。记忆是因为某个输入而产生的神经更新,而学习是获取有效和有用记忆的过程。换句话说,记忆只是把信息存进去,而学习是要存得巧妙、存得有用。就像你可以把一大堆东西塞进衣柜里(这是记忆),但要让衣柜整整齐齐、想找什么一眼就能找到(这是学习),就需要更高级的技巧了。
这个区分非常关键,因为它告诉我们:神经网络的每一个组成部分,本质上都是在做同一件事,学习如何建立有效的"钥匙-宝藏"关联。不管是处理文本的注意力机制,还是存储知识的全连接层,甚至是帮助训练的优化器,它们都可以被理解为不同形式的联想记忆系统。
训练一个神经网络就像教一个学生记单词
让我们从最简单的例子开始,一步步揭开嵌套学习的神秘面纱。假设我们要训练一个只有一层的简单神经网络来完成某个任务。按照传统的理解,我们给网络看一堆训练数据,计算它犯了多少错误,然后用梯度下降这个方法来调整网络的参数,让错误变小。重复这个过程很多次,网络就学会了。
但嵌套学习给出了一个更有趣的解读。每次我们用梯度下降更新参数时,其实是在做这样一件事:把输入数据这个钥匙和错误信号这个宝藏关联起来。这里的错误信号是一个技术概念,研究团队给它起了一个很有诗意的名字局部惊讶信号。
什么是局部惊讶信号?想象你在教一个学生记英语单词。你给他看一个单词apple,他猜这个词的意思是橙子,然后你告诉他正确答案是苹果。这时候,学生大脑里产生的那种"哦,原来不是橙子是苹果啊"的感觉,就是惊讶。这个惊讶信号告诉大脑:你之前的猜测和正确答案之间有差距,需要调整。
神经网络的学习过程与此类似。每次网络看到一个输入并做出预测后,都会收到一个反馈,告诉它预测和正确答案之间的差距有多大。这个差距信号就是局部惊讶信号。网络需要学会的,就是把每个输入和它对应的惊讶信号关联起来,这样下次遇到类似的输入时,就知道该怎么调整了。
从这个角度看,训练一个简单的神经网络就是训练一个联想记忆系统,它学习的是"输入-惊讶"之间的关系。这是嵌套学习的第一层含义。
当学生学会做笔记:动量优化器的秘密
事情变得更有趣了。在实际训练神经网络时,我们通常不会用最简单的梯度下降,而是会用一些更聪明的方法,比如带动量的梯度下降。动量是什么?简单说,就是让网络记住之前几步的调整方向,而不是每一步都从零开始。
让我继续用教学生的比喻。假设这个学生不仅要记单词,还学会了做笔记。每次他猜错一个单词后,不仅会记住这个单词的正确意思,还会在笔记本上记下来"我经常把水果类的单词搞混"。这样,下次遇到类似情况时,他可以先翻翻笔记,看看自己以前犯过什么错误,然后更有针对性地学习。
在数学上,动量就像这个笔记本。它会累积过去的梯度信息,帮助网络在正确的方向上走得更稳、更快。但是,研究团队发现了一个惊人的事实:这个笔记本本身也是一个联想记忆系统!动量在做的事情,就是把一系列的梯度压缩、记忆到自己的参数里。
这意味着什么?意味着当我们用带动量的梯度下降来训练一个简单神经网络时,实际上有两层学习在同时进行。外层是神经网络本身的学习(学习输入-惊讶的关联),内层是动量的学习(学习梯度的历史模式)。两层学习相互嵌套,就像俄罗斯套娃一样。
更复杂的套娃:当网络结构也开始学习
现在让我们把视野放得更宽一些。假设我们不是用简单的神经网络,而是用一个更复杂的架构,比如线性注意力机制。注意力机制是现代AI(尤其是Transformer架构)的核心组件,它让模型能够关注输入中最重要的部分。
研究团队发现,线性注意力的工作方式也可以被理解为联想记忆。具体来说,当注意力机制处理一个序列的数据时,它会建立一个记忆矩阵,把每个位置的"钥匙"和"宝藏"关联起来。每看到一个新的输入,这个记忆矩阵就会更新一次。这个更新过程,本质上就是用梯度下降来优化一个内部目标,和我们训练整个网络的过程如出一辙!
所以,当我们用带动量的梯度下降来训练一个包含线性注意力的网络时,实际上有多少层学习在同时进行呢?让我们数一数:首先是注意力机制内部的学习(更新记忆矩阵),然后是动量的学习(累积梯度历史),最后是整个网络参数的学习(基于累积后的梯度更新权重)。这就是三层嵌套的学习!
研究团队进一步指出,这些不同层次的学习有不同的更新频率。注意力机制的记忆矩阵每看到一个新词就更新一次,这是最高频率的学习。动量每处理一批数据更新一次,频率稍低。网络的整体参数则是在整个训练过程中缓慢调整,频率最低。
这个多频率的特性,正好对应了人脑中快速神经元和慢速神经元的分工。快速更新的部分负责处理眼前的信息,慢速更新的部分负责积累长期的知识。嵌套学习为我们揭示了:深度学习模型内部天然就存在这种多时间尺度的结构,只是我们以前没有注意到而已。
优化器也是学生:Adam的真面目
如果说上面的发现已经足够令人惊讶,那么接下来的内容可能会彻底颠覆你对深度学习的认知。研究团队不仅分析了简单的动量,还把目光投向了更先进的优化器,比如大名鼎鼎的Adam。
Adam是目前训练神经网络最常用的优化器之一,它不仅记录梯度的历史(像动量一样),还记录梯度变化幅度的历史,然后根据这两种信息自适应地调整学习步长。听起来很复杂,但研究团队发现,Adam本质上也是一个联想记忆系统,而且是一个更聪明的版本。
普通的动量就像一个只会记"这道题我错过"的学生,而Adam就像一个会记"这道题我错过,而且我经常在这类题上犯错,所以下次要特别小心"的学生。它不仅记住过去的错误,还会分析错误的模式,从而做出更明智的调整。
基于这个洞察,研究团队提出了几种改进优化器的方法。既然优化器是联想记忆,那我们就可以用设计更好的联想记忆的方法来设计更好的优化器。比如,可以让"钥匙"和"宝藏"之间的关联更加丰富(他们称之为更有表达力的关联),或者可以用更强大的记忆模型来替代简单的线性累积(他们称之为更有表达力的记忆),又或者可以在记忆的输出上加一些后处理步骤(他们称之为非线性输出)。
有趣的是,按照最后一种思路设计出的优化器,恰好和另一个叫做Muon的优化器不谋而合。这说明嵌套学习不仅能解释现有的方法,还能指导我们发明新方法,理论和实践在这里完美地统一了。
连续体记忆:告别长期与短期的二分法
传统的记忆理论喜欢把记忆分成短期记忆和长期记忆两类,就像手机的RAM和硬盘一样。但研究团队认为,这种二分法太过简化了。真实的大脑,以及他们理想中的AI,应该有一个连续体的记忆系统,从最短期到最长期,有无数个中间层次,每个层次以不同的频率更新。
想象一下,你的记忆系统不是只有便利贴和日记本两种,而是有一整个抽屉柜,从最上面的随手记到最下面的珍藏档案,中间还有周总结、月计划、年度回顾等等。每一层都有自己的更新节奏,最上面的每天都在换,最下面的可能几年都不动。这些层次之间并不是孤立的,而是信息会慢慢地从上层渗透到下层,最重要的内容最终会被写入最深的档案。
研究团队把这个想法形式化为连续体记忆系统。在这个系统中,有一系列的存储模块排成一列,每个模块负责存储特定时间尺度的信息。最频繁更新的模块处理即时的、快速变化的信息;最慢更新的模块存储长期的、稳定的知识。信息在模块之间流动,从快速模块向慢速模块传递。
这个设计直接对应了人脑中的记忆巩固机制。我们白天学到的东西首先进入"快速通道",然后在睡眠中被复习并转移到更稳定的存储区域。连续体记忆系统正是这个过程的人工实现。
HOPE:一个能自我进化的AI架构
把所有这些想法整合在一起,研究团队创造了一个全新的AI架构,他们给它起了一个充满希望的名字HOPE。这个名字不仅是英文希望的意思,更代表了研究团队对未来AI的期许:一个能够真正持续学习、不断进化的智能系统。
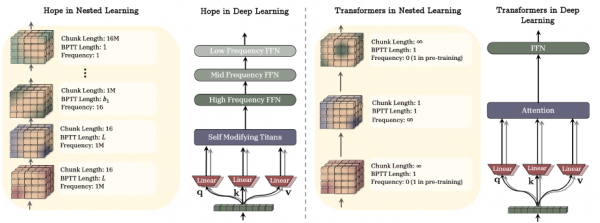
HOPE的核心是一个自我修改的序列模型。什么叫自我修改?简单说,就是这个模型不仅能学习如何处理数据,还能学习如何改变自己的学习规则。这就像一个学生不仅在学知识,还在学如何学习这种元认知的能力。
在技术层面,HOPE结合了两个关键创新。第一个是基于Titans架构的自我修改序列模型,这个模型的参数会在处理每一个输入时发生变化,而变化的方式本身也是可学习的。第二个是连续体记忆系统,提供了多层次、多时间尺度的信息存储能力。
研究团队在多个任务上测试了HOPE的表现。在语言建模任务中,HOPE在维基百科困惑度和LAMBADA数据集上都取得了优异的成绩。在常识推理任务中,包括物理推理、社会智商、布尔问答等多个基准测试上,HOPE也展现出了强大的能力。更令人兴奋的是,HOPE在持续学习任务上表现出色,这正是传统模型最头疼的问题。
与传统的Transformer相比,HOPE的架构更加透明。在嵌套学习的视角下,我们可以清晰地看到HOPE内部每一层学习的目标、更新频率和相互关系。这种透明性不仅有助于理解模型的行为,也为进一步改进提供了明确的方向。
至顶AI实验室洞见
长期以来,深度学习被批评为黑箱,模型的行为很难解释,我们只知道它能工作,但不知道为什么能工作。嵌套学习提供了一种打开这个黑箱的新方式。
通过把模型分解为多层嵌套的优化问题,每一层都有明确的数学目标和更新规则,我们可以精确地追踪信息在模型中的流动和变换。这就像把一个复杂的机器拆开,看清每一个齿轮是如何转动的,以及它们是如何相互咬合的。
更重要的是,嵌套学习揭示了上下文学习(也就是模型在看到一些示例后能够举一反三的能力)是如何产生的。以前,这种能力被认为是大模型的涌现现象,突然就有了,没人知道为什么。但在嵌套学习的框架下,我们可以看到:上下文学习本质上就是高频更新层在压缩和利用当前上下文的信息,而这个过程和低频更新层在训练阶段做的事情是一样的,只是时间尺度不同。
这个发现说明,训练时学习和推理时学习并不是两种截然不同的机制,而是同一种学习机制在不同时间尺度上的体现。模型之所以能够在推理时快速适应新任务,是因为它在训练时就已经学会了如何学习,这正是嵌套结构的力量。
论文最大的贡献可能不只是具体的技术,而是一种新的看问题的方式。它告诉我们,深度学习不是一个扁平的、单层的过程,而是一个立体的、多层嵌套的结构。就像我们打开了俄罗斯套娃,发现里面还有套娃,再打开还有,而每一层都同样精彩、同样重要。
当我们不再满足于堆叠更多的层,而是开始思考如何设计更深层次的嵌套结构时,也许真正的通用人工智能就不再遥远了。
论文地址:https://abehrouz.github.io/files/NL.pdf
Q&A
Q1:嵌套学习和传统的深度学习有什么区别?
A:传统深度学习把神经网络看作层层堆叠的处理单元,信息从下往上流动。嵌套学习则揭示了每一层、甚至每个组件内部都有自己的小型学习过程,这些学习以不同频率进行并相互嵌套。这就像从只看蛋糕的外表,变成理解蛋糕是由面团、奶油、水果等多层材料各自发挥作用共同组成的。
Q2:HOPE架构会不会取代现在的ChatGPT?
A:HOPE目前还是一个研究原型,主要验证嵌套学习理论的可行性。它在持续学习能力上确实展现出优势,但离商业化产品还有距离。不过它提出的连续体记忆和自我修改等思想很可能被整合到未来的AI产品中,让它们具备更强的长期记忆和适应能力。
Q3:普通人怎么理解AI也有记忆问题这件事?
A:你可以把现在的AI想象成一个只能用便利贴做笔记的人——便利贴一撕掉,之前聊的内容就忘了。嵌套学习试图给AI一个真正的记忆系统,从临时便签到永久档案,让AI能像人一样积累经验、持续成长。
来源:至顶AI实验室
好文章,需要你的鼓励


阿里云服务器部署速度跟不上AI需求,GPU配给优先大客户
阿里云CEO吴泳铭在财报电话会议上表示,AI需求增长如此迅猛,以至于服务器部署速度无法跟上客户需求。公司正在对GPU进行配给制,优先满足使用全套阿里云服务的客户需求。过去12个月,阿里巴巴在AI相关基础设施上投入1200亿元人民币,预计三年预算可能超过当前的3800亿元。阿里云智能集团季度营收达56亿美元,同比增长34%。

人大联合腾讯重磅推出LaSeR:让AI学会自我评判的最后一招,竟然只需看一个词!
这项由中国人民大学联合腾讯开发的LaSeR技术,发现了AI在生成答案最后一刻会无意中透露对答案质量的评估。通过观察这个"最后一词效应",研究人员开发出了一种让AI高效进行自我评估的方法,在几乎不增加计算成本的情况下,大幅提升了AI的自我验证能力,为构建更可信的AI系统开辟了新路径。

ChatGPT推出AI购物助手 生成个性化买家指南功能
OpenAI为ChatGPT推出"购物研究"新功能,恰逢假期购物季。该功能面向免费和付费用户开放,支持移动端和网页版。用户询问购物问题时,ChatGPT会提供个性化购物助手服务,通过一系列问题帮助用户筛选价格、用途和功能偏好。该功能基于专为购物任务优化的GPT-5 mini版本,从优质网络资源获取产品信息。OpenAI计划推出即时结账功能,允许用户直接在ChatGPT内购买商品。

南洋理工大学团队发布NEO:从零开始构建真正意义上的“原生“视觉语言模型
新加坡南洋理工大学团队开发的NEO模型颠覆了传统视觉语言AI的设计思路,从模块化拼接转向原生统一架构。仅用3.9亿图文配对数据就实现了与大型模块化系统相媲美的性能,证明了端到端训练的有效性,为AI系统设计开辟了新路径。
2025
11/26
15:11
分享
点赞

国家数据局公布2025年“数据要素×”大赛获奖名单:蚂蚁数科获优秀奖
超1亿用户可随时唤醒千问,夸克发布最新AI浏览器
阿里云服务器部署速度跟不上AI需求,GPU配给优先大客户
ChatGPT推出AI购物助手 生成个性化买家指南功能
Google与英伟达AI芯片竞争升级,Meta寻求合作
Mercy Ships与Presidio、思科携手推动海上医疗数字化变革
日本芯片初创公司Rapidus计划建设1.4纳米芯片制造厂
长虹佳华荣膺微软年度最佳合作伙伴大奖,云智协同驱动中国企业全球化跃迁
Hitachi Vantara推出VSP One高端块存储,赋能AI与任务关键型工作负载新时代
从创意到部署:Ignite 2025呈现AI完整生命周期
戴尔科技集团公布 2026 财年第三财季财报
现已上市:AMD Spartan UltraScale+ FPGA SCU35 评估套件——面向所有开发人员的经济实惠平台
