
DeepSeek回应消失传闻,发布DeepSeek V3.2模型 原创
2025年接近尾声,全球顶尖AI大厂开始上演神仙打架,OpenAI发布GPT 5.1,Google发布Gemini 3和Nano Banana 2,阿里发布千问APP......
上周,X上的一位路人网友突然意识到,年初的神DeepSeek去哪了?他不经意地感叹:“哥们儿消失得像从来没有存在过。”,帖子浏览量飙升到530万,看来不止他一个人这么想。

昨天DeepSeek突然开源DeepSeek-V3.2正式版,终结了消失流言。DeepSeek-V3.2 模型参数685B,首次将思考融入工具使用。它的高配版本DeepSeek-V3.2-Speciale,在2025年国际数学奥林匹克竞赛和国际信息学奥林匹克竞赛中都达到了金牌水平。模型文件和技术报告已在魔搭社区和Huggingface开源。
换做是OpenAI,在GPT 5 未发布期间,Sam Altman长期多次发帖暗示GPT 5将要发布,根本不存在消失的可能。
你更欣赏OpenAI的风格,还是DeepSeek的低调和开源?
下面一起来看看DeepSeek-V3.2技术报告有哪些重要发现。
开源与闭源之争:一场关于AI民主化的较量
假如有一场厨神争霸赛。闭源AI公司就像是那些拥有米其林三星厨房、顶级食材和专业团队的餐厅,而开源社区则像是一群热爱烹饪的家庭厨师,他们只能用普通超市的食材和家用厨具。长期以来,这两类选手之间的差距一直在扩大,专业餐厅做出的菜品越来越精致,而家庭厨师们虽然努力追赶,但似乎总是差那么一口气。
DeepSeek团队的研究人员仔细分析了这种差距的根源,发现了三个关键问题。第一个问题出在"厨具"上,也就是模型的架构。传统的注意力机制就像是一口需要同时加热所有食材的大锅,当食材(也就是处理的文本)越来越多时,这口锅就变得越来越难以驾驭,效率急剧下降。第二个问题在于"烹饪时间",开源模型在训练后期投入的计算资源远远不够,就像一道需要慢火炖煮三小时的菜,却只给了三十分钟。第三个问题则体现在"厨艺技巧"上,当AI需要像人类助手一样使用各种工具完成复杂任务时,开源模型的表现明显逊色于闭源对手。
智能"闪电侠":让AI学会聪明地选择关注点
为了解决第一个问题,DeepSeek团队发明了一种叫做"DeepSeek稀疏注意力"(简称DSA)的新技术。要理解这项技术,我们可以想象一个正在阅读《红楼梦》的读者。传统的AI在处理文本时,就像一个强迫症患者,每读到一个新字,都要回头把前面所有的字都重新看一遍,确认它们之间的关系。当文章只有几百字时,这种做法还能接受;但当面对一部百万字的巨著时,这种方法就变得荒谬至极,每读一个新字就要重温前面所有内容,效率低得令人发指。
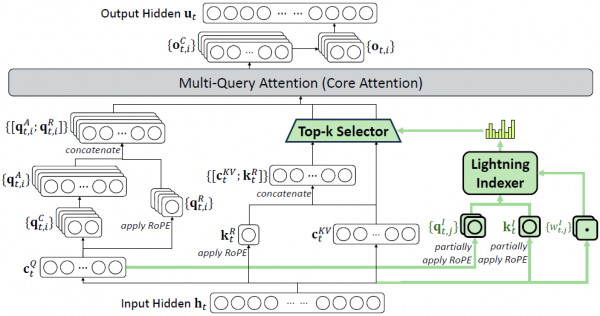
DSA的解决方案非常巧妙,它引入了一个"闪电索引器"。这个索引器就像是一位经验丰富的图书管理员,当你问他某本书的内容时,他不需要把图书馆里所有书都翻一遍,而是凭借多年积累的经验,迅速定位到最相关的几本书。具体来说,这个闪电索引器会快速扫描所有之前的文本内容,然后给每一段内容打一个"相关性分数"。接下来,AI只需要仔细关注那些得分最高的内容,而不是把所有内容都同等对待。
这种方法的效果立竿见影。打个比方,如果原来的方法需要把一本书的每一页都仔细读一遍才能回答问题,那么新方法只需要翻到最相关的几页就够了。在数学上,这意味着计算复杂度从"文本长度的平方"变成了"文本长度乘以一个固定的小数字"。对于128K长度的文本(大约相当于一本中等厚度的小说),这种优化带来的效率提升是惊人的。
为了让这个"闪电索引器"真正发挥作用,研究团队设计了一个精妙的两阶段训练过程。第一阶段叫做"热身",就像是让一个新来的图书管理员先熟悉图书馆的布局。在这个阶段,AI保持原来的"全部阅读"模式不变,但同时让闪电索引器在旁边学习:哪些内容是真正重要的,哪些可以快速跳过。这个过程只用了大约20亿个文字符号的训练量。第二阶段则是"实战训练",AI开始真正使用闪电索引器来选择关注点,整个系统一起优化磨合。这个阶段使用了将近9440亿个文字符号的训练数据,让系统彻底适应了新的工作方式。
给AI打"鸡血":强化学习的艺术
解决了效率问题后,接下来要攻克的是如何让AI变得更聪明。DeepSeek团队采用的核心方法叫做"群体相对策略优化",简称GRPO。原理可以用一个简单的比喻来理解。
想象你正在训练一群小狗完成特定的任务,比如找到藏在房间里的玩具。传统的训练方法是:每次小狗完成任务后,根据它的表现给予奖励或惩罚。但问题在于,任务的难度可能每次都不同,有时候玩具藏得很隐蔽,有时候又很明显。如果只是简单地根据"找到还是没找到"来奖惩,小狗可能会困惑:为什么同样找到了玩具,有时候被夸奖,有时候却只是勉强过关?
GRPO的聪明之处在于,它让多只小狗同时尝试同一个任务,然后比较它们的表现。表现最好的那只得到额外奖励,表现最差的则受到批评,而中间的则根据相对位置获得相应的反馈。这样一来,AI学到的就不是"做到某个绝对标准就好",而是"要比其他尝试做得更好"。这种相对比较的方式更加公平,也更有效。
然而,让强化学习真正大规模运转起来,就像是组织一场几万人参加的马拉松比赛,说起来简单,做起来却有无数细节需要处理。DeepSeek团队分享了他们在这个过程中踩过的坑和找到的解决方案。
第一个挑战是"估算偏差"问题。在强化学习中,AI需要不断估算自己的行为离"理想状态"有多远。原来的估算方法在某些情况下会出现严重偏差,就像一把校准不准的尺子,量出来的长度总是差那么一点点。这些小误差会不断累积,最终让整个训练过程变得不稳定。团队通过引入一种叫做"无偏KL估计"的方法修正了这个问题,就像是重新校准了那把尺子。
第二个挑战来自"过时样本"。在实际训练中,AI需要先生成一大批尝试,然后再从中学习。但问题是,当AI开始学习这些样本时,它自己已经发生了变化,就像你在周一写了一篇作文,到周五才收到老师的批改,但这几天里你的写作水平已经提高了,老师的批改建议可能已经不那么适用了。更糟糕的是,如果AI从一些"特别糟糕"的过时样本中学习,可能会学到错误的教训。团队的解决方案是:对于那些表现糟糕且已经严重过时的样本,直接忽略不学。这就像是告诉AI:"这个建议已经过时了,我们跳过它吧。"
第三个挑战与模型架构有关。DeepSeek-V3.2使用了一种叫做"专家混合"的架构,这意味着模型内部有很多"小专家",每次只激活其中一部分来处理任务。问题在于,在生成样本和学习样本时,可能会激活不同的专家组合,导致学到的东西和实际应用时的情况不匹配。团队的解决方案很直接:记住生成每个样本时使用了哪些专家,学习时也使用同样的专家组合。
教会AI使用工具:从"书呆子"到"全能助手"
一个真正有用的AI助手不仅要能回答问题,还要能使用各种工具完成实际任务,比如搜索网页、编写代码、操作文件系统等。这就好比一个学生,仅仅考试成绩好是不够的,还要学会使用计算器、查字典、上网检索资料等实用技能。
DeepSeek团队面临的挑战是:如何让AI在使用工具的同时保持深度思考能力?之前的方法要求AI每次调用工具后都要"从头开始思考",就像一个人每打一次电话就要忘记之前想好的所有计划,然后重新规划。这显然是极大的浪费。
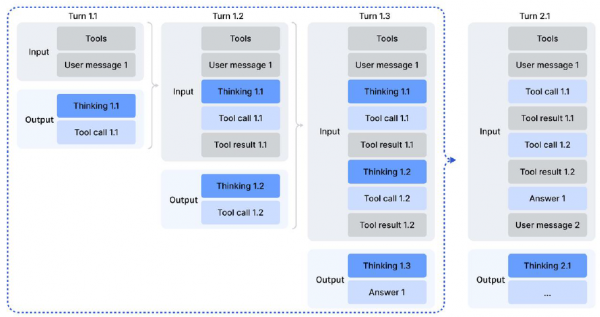
团队设计了一套精巧的"思考保留机制"。核心规则是:只有当用户发送新消息时,才清空之前的思考内容;如果只是工具返回了结果,那么之前的思考应该继续保留。这就像是你在网上查资料写论文,每次搜索引擎返回结果时,你不需要把之前想好的论文大纲全部忘掉,而是在原有思路的基础上继续完善。
但仅有好的机制还不够,AI还需要大量的练习才能真正学会使用工具。这里就出现了一个鸡生蛋蛋生鸡的问题:要训练AI使用工具,需要大量的训练数据;但这些数据又需要AI来生成。团队采用了一种叫做"冷启动"的策略来打破这个僵局。他们首先把现有的"思考型AI"和"工具型AI"的能力结合起来,通过精心设计的提示词,让AI尝试在思考过程中调用工具。虽然一开始的成功率不高,但这些成功的案例可以作为种子,通过强化学习不断改进。
打造AI的"训练场":从合成任务到真实世界
训练一个优秀的AI助手,就像是培养一个全能特工,你需要在各种模拟场景中对其进行训练,才能让它在真实世界中游刃有余。DeepSeek团队构建了一个庞大的训练任务库,包含了1827个独特的环境和85000个复杂的任务提示。
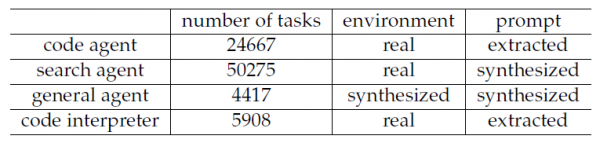
这些任务分为几大类:代码助手任务、搜索助手任务、通用助手任务和代码解释器任务。其中最有意思的是通用助手任务的生成方式。团队开发了一个"环境合成代理",它会自动创建各种挑战性的任务场景。举个例子,一个典型的合成任务可能是这样的:帮用户规划一个三天的旅行,从杭州出发,要求每天不能重复城市、酒店、餐厅和景点,而且还要根据酒店的价格档次调整其他开支的预算限制。这种任务听起来简单,但实际上需要AI在庞大的可能性空间中搜索一个满足所有约束条件的解决方案,是非常考验能力的。
任务合成的流程非常巧妙。首先,系统会根据任务类别(比如旅行规划)自动收集或生成相关的数据,比如各城市的酒店、餐厅和景点信息。然后,系统会创建一系列专门的工具函数,比如"查询某城市所有景点"、"获取某酒店的价格"等。接下来是最关键的一步:系统会先生成一个简单的任务,配合正确答案和验证函数,然后逐步增加任务难度。如果当前的工具不足以解决更难的任务,系统还会自动扩展工具集。这个过程就像是游戏设计师在设计关卡,先从简单的开始,确保玩家能通关,然后逐步增加难度。
实战检验:当AI遇上国际奥林匹克竞赛
一个模型到底有多厉害,最好的检验方式就是让它参加真正的考试。DeepSeek团队选择了几个极具挑战性的"考场"来测试他们的模型。
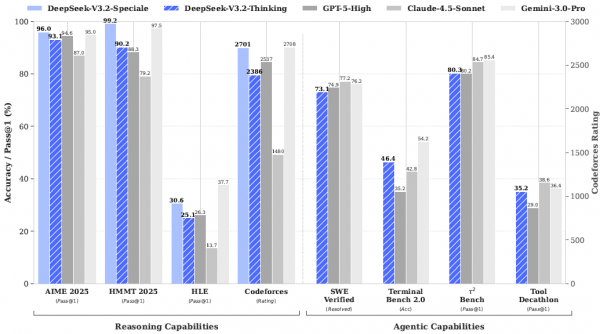
在数学领域,DeepSeek-V3.2-Thinking版本在2025年美国数学邀请赛(AIME)上达到了93.1%的准确率,与GPT-5-High的94.6%和谷歌Gemini 3.0 Pro的95.0%非常接近。在难度更高的哈佛-MIT数学竞赛(HMMT)2025年2月赛上,DeepSeek-V3.2-Speciale更是达到了99.2%的惊人准确率,超越了所有对手。
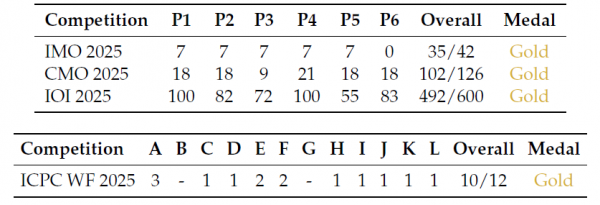
最令人瞩目的是在国际奥林匹克级别竞赛上的表现。DeepSeek-V3.2-Speciale在2025年国际数学奥林匹克(IMO)上获得了35分(满分42分),达到金牌水平;在国际信息学奥林匹克(IOI)上获得了492分(满分600分),同样是金牌水平,排名第10位;在ICPC世界总决赛上解决了12道题中的10道,排名第2位,同样是金牌成绩。这些成绩意味着,一个开源AI模型已经能够在人类最顶尖的学术竞赛中与最优秀的选手同台竞技。
在更贴近实际应用的代码助手任务上,DeepSeek-V3.2同样表现出色。在SWE-Verified基准测试中(这个测试要求AI解决真实的软件问题),DeepSeek-V3.2达到了73.1%的解决率,虽然略低于Claude-4.5-Sonnet的77.2%,但已经是开源模型中的最佳表现。更值得一提的是,在多语言软件工程任务上,DeepSeek-V3.2以70.2%的解决率超越了所有竞争对手,包括Claude-4.5-Sonnet的68.0%。
效率与性能的平衡艺术
细心的读者可能已经注意到一个问题:更长的思考通常意味着更好的结果,但也意味着更高的成本。DeepSeek团队在这个问题上做了大量的权衡实验。
他们发布了两个版本的模型:标准版DeepSeek-V3.2和加强版DeepSeek-V3.2-Speciale。两者的主要区别在于对思考长度的限制不同。标准版在训练时加入了较强的"长度惩罚",鼓励AI用更精炼的思考得出答案;加强版则放宽了这个限制,允许AI进行更深入、更长时间的思考。
实验数据清晰地展示了这种权衡。在AIME 2025测试中,标准版使用平均16000个输出词元(可以理解为"思考的长度"),达到93.1%的准确率;加强版使用平均23000个词元,准确率提升到96.0%。在更难的IMOAnswerBench测试中,标准版使用27000词元达到78.3%准确率,加强版使用45000词元达到84.5%。可以看出,更多的思考确实带来了更好的结果,但代价是更高的计算成本。
有意思的是,当与谷歌的Gemini-3.0-Pro相比时,DeepSeek的模型在"思考效率"上还有提升空间。Gemini-3.0-Pro在AIME 2025上只用了15000词元就达到了95.0%的准确率,而DeepSeek-V3.2-Speciale需要23000词元才能达到96.0%。这说明DeepSeek的思考过程还有"注水"的成分,未来可以通过提高"思考密度"来进一步优化。
合成数据的魔力:少即是多的悖论

一个令人惊讶的发现来自于对合成训练数据的实验。研究团队随机抽取了50个他们合成的通用助手任务,然后让各种顶级AI模型去尝试解决。结果显示,即使是最强大的GPT-5-Thinking也只能解决其中62%的任务,而DeepSeek-V3.2-Exp只能解决12%。这说明这些合成任务确实具有足够的挑战性,不是那种AI轻松就能刷分的"水题"。
更关键的是,当研究团队只使用这些合成的通用助手任务来训练AI时,模型在完全不同的真实世界任务上也表现出了明显的进步。在Tau2Bench(一个测试对话助手能力的基准)、MCP-Mark和MCP-Universe(测试工具使用能力的基准)上,经过合成数据训练的模型都比基线版本有了显著提升。这个发现非常重要,因为它说明:精心设计的合成数据可以让AI学到可迁移的通用能力,而不仅仅是在特定任务上刷分。
突破上下文长度限制:让AI的"工作记忆"更持久
即使是128K的超长上下文窗口(大约相当于一整本小说的长度),在某些复杂的搜索任务中也会不够用。研究团队探索了几种"上下文管理"策略来突破这个限制。
第一种策略叫"总结法":当快要超出长度限制时,先总结之前的工作,然后从头开始新的尝试。第二种是"丢弃75%法":扔掉最早的75%的工具调用历史,保留最近的25%继续工作。第三种是"全部丢弃法":清空所有历史记录,只保留必要的上下文信息重新开始。
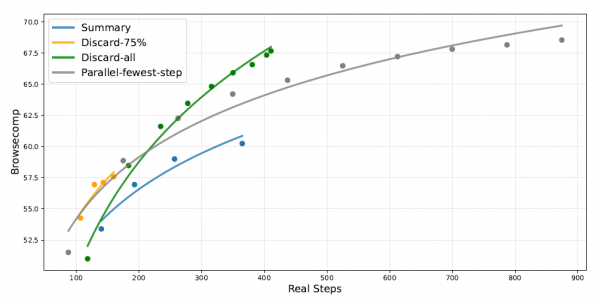
在BrowseComp基准测试(一个非常困难的网页搜索任务)上的实验显示,这些策略都能显著提升性能。原本模型的准确率是53.4%,使用"总结法"后提升到60.2%,使用"全部丢弃法"后更是达到了67.6%。有趣的是,最简单粗暴的"全部丢弃法"反而效果最好,而且效率也更高。这个发现提示我们:有时候"断舍离"式的清空重来,可能比试图保留所有历史信息更有效。
至顶AI实验室洞见
DSA技术带来的效率提升是实实在在的。研究团队公布了在H800 GPU集群上的实际运营成本数据。对于短文本(比如一般的对话),DeepSeek-V3.2和前代产品的成本差不多;但随着文本长度增加,差距迅速拉大。在处理128K长度的文本时,DeepSeek-V3.2的预填充成本大约是前代产品的三分之一,解码成本更是降低到了约四分之一。
这种成本优势的意义不仅仅是省钱。更低的成本意味着更多的人和组织能够负担得起使用顶级AI的费用,这对于AI技术的普及和民主化有着深远的影响。
DeepSeek-V3.2的故事是一个关于"不信邪"的故事。当大部分人都认为开源模型在复杂推理和工具使用上永远无法追上闭源大厂时,DeepSeek团队用技术创新证明了另一种可能性。DSA让长文本处理变得高效,改进的GRPO算法让大规模强化学习成为可能,而精心设计的合成数据管道则让AI学会了真正有用的技能。
团队也承认,与谷歌的Gemini-3.0-Pro相比,DeepSeek-V3.2在世界知识的广度上还有差距(毕竟训练投入的计算量不在一个量级),在思考效率上也有提升空间。此外,在一些极其复杂的任务上,开源模型与顶级闭源模型之间仍然存在明显差距。
但这些局限性同时也指明了未来的方向:更多的预训练计算投入、更高密度的推理链优化、以及更精细的基础模型和后训练方法。开源AI的追赶之路还很长,但DeepSeek-V3.2证明了这条路是走得通的。也许在不久的将来,每个人都能拥有一个像DeepSeek-V3.2这样聪明的AI助手,而不需要为此支付高昂的费用。这才是这项研究真正令人兴奋的地方。
Q&A
Q1:DeepSeek-V3.2是什么?
A:DeepSeek-V3.2是由DeepSeek-AI团队在2025年发布的开源大语言模型,它通过创新的稀疏注意力机制和强化学习方法,在推理能力和工具使用方面达到了接近顶级闭源模型(如GPT-5和Gemini-3.0-Pro)的水平,其高配版本甚至在国际数学奥林匹克竞赛中获得了金牌级表现。
Q2:DeepSeek-V3.2相比其他AI模型有什么优势?
A:DeepSeek-V3.2的核心优势在于它是开源的,同时性能却能与顶级闭源模型相媲美。它采用的DSA技术大幅降低了长文本处理的成本,在128K长度文本上的运营成本仅为前代产品的约四分之一,让更多人能够负担得起使用顶级AI的费用。
Q3:普通人能用到DeepSeek-V3.2吗?
A:是的,由于DeepSeek-V3.2是开源模型,研究团队已经在HuggingFace等平台上公开了模型代码和权重,技术人员可以自行部署使用,普通用户也可以通过DeepSeek的官方服务或第三方应用来体验这个模型的能力。
来源:至顶AI实验室
好文章,需要你的鼓励



斯坦福大学团队创造“图片说明有用度检测器“,让AI学会分辨哪些图片描述真正有价值
这项研究开发了CaptionQA系统,通过测试AI生成的图片描述能否支持实际任务来评估其真正价值。研究发现即使最先进的AI模型在图片描述实用性方面也存在显著不足,描述质量比直接看图时下降9%-40%。研究涵盖自然、文档、电商、机器人四个领域,为AI技术的实用性评估提供了新标准。

对话高途创始人陈向东:AI浪潮里,如何重写“教”和“育”?
AI改变的远不止一间课堂,而是学生的学习方式、未来的职场场景和社会对工作者能力的要求,整个商业文明中的每一位参与者,都将被推着一起改变。

当YOLO遇见团队合作:以色列科技学院让AI“分工协作“,目标检测准确率再创新高
以色列理工学院研究团队提出了一种将专家混合模型融入YOLOv9目标检测的创新方法。该方法让多个专门化的YOLOv9-T专家分工协作,通过智能路由器动态选择最适合的专家处理不同类型图像。实验显示,在COCO数据集上平均精度提升超过10%,在VisDrone数据集上提升近30%,证明了"分工合作"比单一模型更有效,为AI视觉系统提供了新思路。
2025
12/02
18:53
分享
点赞

NVIDIA 与新思科技宣布建立战略合作伙伴关系,携手重塑工程与设计未来
对话高途创始人陈向东:AI浪潮里,如何重写“教”和“育”?
Z世代与AI重塑商业世界:数字原住民如何驾驭人工智能浪潮
谷歌AI最大优势:对你的深度了解
Runway与DeepSeek发布新一代基础模型,性能超越行业巨头算法
Satechi推出iPhone磁吸式多功能扩展坞
数据中心能耗需求预计到2035年将激增近300%
千问APP接入Qwen-Image新模型,一句话换视角、打光、精准改图
众智有为 致敬同路人|十年耕耘轨道交通,嘉环诺金点亮一个灯塔
MIT揭秘:300亿美元砸下去,为何95%的企业AI项目都在"烧钱"?
李飞飞:语言太窄,装不下三维世界
英伟达发布自动驾驶研究新开源AI模型与工具
