
多模态智能时代,AI模型遭遇“空间推理危机"——苏黎世联邦理工学院的MARBLE基准测试挑战来袭! 原创
说起人工智能的发展,我们总是被各种"AI超越人类"的新闻轰炸。Claude能写诗,GPT-4能看图说话,最新的模型甚至能理解视频内容。当这些看似无所不能的AI遇到真正需要空间思维和多步骤推理的复杂问题时,会发生什么呢?
就像一个看似聪明的学生在遇到真正需要动脑筋的数学应用题时突然卡壳一样,目前最先进的多模态语言模型,在面对复杂的空间推理任务也时常表现得相当糟糕。这并不是因为这些AI不够先进,而是因为真正的智能推理比我们想象的要复杂得多。
这个问题的核心在于,现有的AI测试基本上都像是在考"填空题"——给AI一张图片和一个问题,它只需要从图片中找到答案就行了。但真实世界的问题往往需要像侦探破案一样,把多个线索串联起来,制定一个详细的行动计划,还要考虑各种物理限制和空间约束。
正是基于这样的思考,来自苏黎世联邦理工学院的研究团队开发了一个名为MARBLE(MultimodAl Reasoning Benchmark for Language modEls)的测试套件。这个名字听起来很学术,但它的本质就是一个"AI智力测试的地狱模式"。这个基准包含两个极具挑战性的任务:M-Portal和M-Cube,它们要求模型在空间、视觉和物理约束下制定和理解多步骤计划。
研究人员想要找出现有AI模型在复杂推理方面的真实水平,就像给学霸出一套特别难的综合应用题,看看他们到底有多少真本事。
传送门的迷宫——M-Portal任务的复杂世界
M-Portal任务受到知名谜题游戏《传送门2》的启发,这是一个第一人称视角的谜题游戏。在这个游戏中,玩家需要通过放置两个传送门来克服障碍物和通过房间,玩家可以在这两个传送门之间瞬移。游戏的一个关键机制是动量守恒:当玩家以给定速度进入一个传送门时,他们会以相同的相对动量从第二个传送门出来。这使得创造性的穿越策略成为可能,比如通过将重力驱动的下落与传送门放置相结合来跳跃穿越大间隙或越过障碍物。
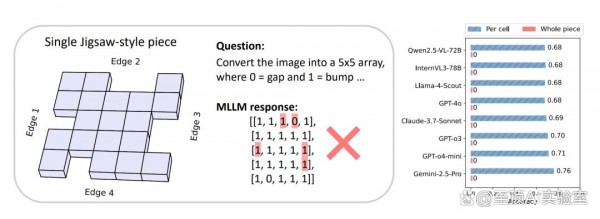
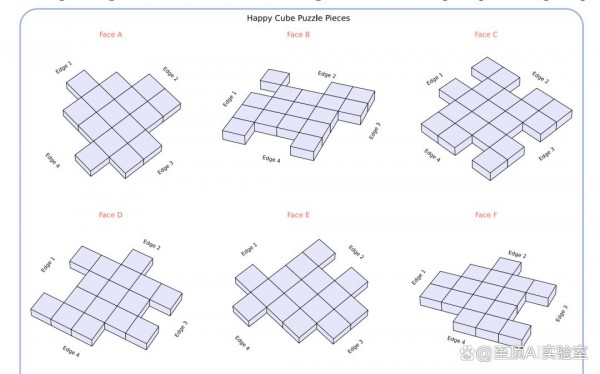
要理解M-Cube任务的复杂性,我们可以把它想象成一个立体版的拼图游戏。你有六块形状奇特的拼图片,每一块都有复杂的凸起和凹槽图案。你的任务是将这些拼图片组装成一个完美的立方体,其中边缘无缝对齐,没有间隙或重叠。为了解决M-Cube任务,多模态语言模型需要为每个拼图片分配一个立方体面并确定正确的方向,也就是说,需要相应地旋转和翻转拼图片以与其他拼图片对齐。
对于每个问题,多模态语言模型必须考虑6!种可能的拼图片到面的分配(模去旋转对称性),对于每个拼图片,还有8种离散的旋转和翻转状态,这导致了候选解的组合爆炸。在这个巨大的搜索空间中,考虑到互锁凸起和凹槽图案施加的几何约束,只有极少数解是有效的。András等人报告说,大多数商业可用的立方体只有一个解(在旋转等价性下),这使得这是一个具有挑战性的推理问题。
虽然M-Cube任务受到Happy Cube拼图的启发,但研究团队合成生成了所有样本。数据生成管道从5×5×5立方体开始,将表面分解为6个互锁拼图片。每个拼图片可以视为5×5网格,其中中心3×3区域始终保留。对于位于边缘的其余单元格,研究团队随机将每个单元格分配给大5×5×5立方体的相邻面之一,以创建沿边界的凸起和凹槽图案。
为了控制难度级别,研究团队创建了两个子任务:CUBE和CUBE-easy,每个子任务包含1000个示例。CUBE-easy是CUBE的简化版本,简化体现在三个方面:首先,输入拼图片被表示为二维数组而不是渲染图像,以减少多模态语言模型的感知错误;其次,每个拼图都经过特别设计,使得解决方案不需要翻转任何拼图片;第三,在提示中提供了4个拼图片排列的部分解决方案,只留下2个缺失的拼图片需要放置。
令人震惊的测试结果——AI巨头们的集体"落榜"
当研究团队用MARBLE基准测试来评估12个最先进的多模态语言模型时,结果令人震惊。在M-Portal任务的计划正确性评估中,所有被调查的模型(包括多模态语言模型和纯文本语言模型)表现都非常糟糕,少数类F1分数约为6%,与随机基线相似。这就像是让一群成绩优异的学生去参加一场全新类型的考试,结果所有人的成绩都和随机猜测差不多。
令人惊讶的是,研究团队发现所有模型在每个单元格上只能达到约70%的准确率。最好的感知性能来自Gemini-2.5-pro,准确率为76%,这意味着模型仍然可能偶尔出错。结果,所有模型在整个拼图片上的准确率都是0%。这些结果突出表明,即使是先进的多模态语言模型在这个看似简单的感知任务上也有困难,这为复杂场景(如CUBE)中的多模态推理构成了潜在瓶颈。
在推理方面,除了感知错误,M-Cube由于来自所有6个拼图片的可能排列和方向组合的巨大搜索空间,仍然是一个极具挑战性的问题。CUBE包含6!×8^6=188,743,680种可能的解决方案。相比之下,CUBE-easy只包含32种可能的解决方案,假设空间减少了500万倍。为了将推理挑战与感知限制分离,研究团队手动将视觉输入转换为相应的文本数组。他们比较了DeepSeek-R1在不同搜索空间配置下的性能。该模型在只有一个缺失拼图片的最简单设置中获得了57%的准确率。然而,随着搜索空间的扩大,性能急剧下降,当超过3个拼图片缺失时降至0%。
工具辅助的迭代改进尝试
面对如此困难的任务,研究团队还探索了一种更接近真实问题解决过程的方法:让模型使用解决方案验证器作为工具来收集反馈并迭代改进其响应。在每一轮中,模型提出候选解决方案并使用解决方案验证器进行评估。基于验证器的反馈,模型可以在下一轮中迭代地改进其响应,朝着更好的解决方案发展。
 A:MARBLE的结果揭示了当前多模态AI模型的重要局限性,指出了未来研发的关键方向。它表明我们需要开发能够进行复杂空间推理和多步规划的新一代模型,这对于机器人技术、自动驾驶、增强现实等需要空间理解的应用领域至关重要。
A:MARBLE的结果揭示了当前多模态AI模型的重要局限性,指出了未来研发的关键方向。它表明我们需要开发能够进行复杂空间推理和多步规划的新一代模型,这对于机器人技术、自动驾驶、增强现实等需要空间理解的应用领域至关重要。来源:至顶AI实验室
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2025
07/03
12:19
分享
点赞

业界首款符合AEC-Q200标准额定电压高达1,000 VDC高压保险丝
数据中心的智算挑战,英特尔要如何应对?
下一代智能工厂怎么建?开放自动化给出“解题思路”
跟随西门子,在工博会感受沉浸式的工业AI体验
苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
OpenAI将发布类似TikTok的社交应用,搭配Sora 2视频模型
微软推出Office智能体模式让用户"氛围办公"
AI助手现在能帮你创建高质量Word文档和Excel表格
高通新一代骁龙平台将推动智能体AI时代到来
SAPx阿里云,开启一条通往中国市场与全球化发展的全新路径
微软推出"氛围工作"模式,为Office套件加入AI智能体
OpenAI推出智能购物系统挑战谷歌亚马逊
