
阿里达摩院与多所高校共推机器人抓取新突破:让灵巧的手学会像人一样安全抓取 原创
在科幻电影中,我们经常看到机器人能够像人类一样灵巧地抓取各种物品,无论是精致的瓷器还是锋利的刀具,都能恰到好处地选择合适的抓取位置。然而在现实世界中,让机器人做到这一点却是一个极其复杂的挑战。现有的机器人抓取技术大多只关注能否成功抓起物体,就像一个力大无穷但笨手笨脚的巨人,虽然能举起重物,却不懂得轻拿轻放,更不知道该握住茶杯的手柄而不是杯身。
正是在这样的背景下,阿里达摩院与多所高校的研究团队开发出了一套名为AffordDex的全新机器人抓取系统。这套系统的独特之处在于,它不仅能让机器人成功抓取物体,更重要的是能让机器人学会像人类一样思考:该抓哪里才安全,该避开哪些危险区域,以及如何做出自然流畅的抓取动作。
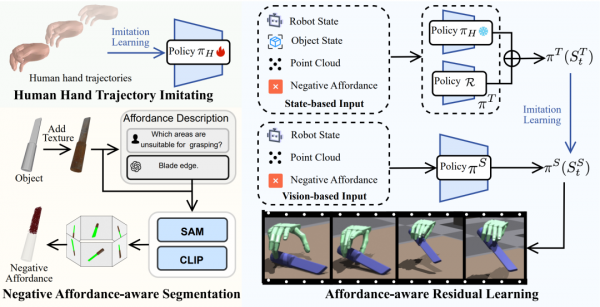
就像教一个孩子学会正确使用餐具一样,研究团队采用了两阶段的训练方法。第一阶段相当于让机器人观摩大量的人类手部动作视频,学习人类是如何优雅地移动手指和手腕的。第二阶段则是在这个基础上,教会机器人识别物体的"禁区"——那些绝对不能碰触的危险部位,比如刀刃、热表面或者易碎部分。
这项研究最令人印象深刻的创新在于引入了"负向功能感知"的概念。简单说来,就是教会机器人学会说"不"。正如一个经验丰富的厨师知道绝不能握住菜刀的刀刃部分,机器人现在也能自动识别并避开物体上那些不适合抓取的区域。研究团队巧妙地利用了最新的视觉-语言模型技术,让机器人能够"看懂"物体的各个部分,并理解哪些地方是禁止触碰的。
从笨拙模仿到优雅掌握:两阶段学习的智慧
在传统的机器人训练中,工程师们往往直接告诉机器人如何完成抓取任务,这就像让一个从未见过筷子的外国人直接学会夹菜一样困难。AffordDex系统采用了一种更加巧妙的方法,将整个学习过程分为两个阶段,就像学习一门艺术一样循序渐进。
第一阶段可以比作是"观摩大师"的过程。研究团队收集了大量人类手部操作的视频数据,这些数据来自OakiInk2数据集,包含了大约2200个右手操作序列。机器人在这个阶段的任务就是专心致志地模仿人类的手部动作,学习如何自然流畅地移动每一个关节。这个过程类似于书法初学者临摹名家字帖,先要掌握基本的笔画和结构,才能谈得上创作。
在这个模仿学习阶段,系统设计了一套精妙的奖励机制。每当机器人的手部姿态越接近人类的参考动作,它就会获得更高的分数。同时,系统还会惩罚那些过于急躁或不平滑的动作,鼓励机器人学会节能高效的运动方式。这就像教孩子写字时,不仅要字形正确,还要笔画流畅,不能用力过猛把纸戳破。
第二阶段则是"学以致用"的关键环节。在掌握了基本的人类动作模式后,机器人需要学会将这些通用动作应用到具体的抓取任务中。这个阶段引入了一个轻量级的"微调模块",就像在原有的动作基础上加上了一个"智能调节器"。这个调节器会根据具体的物体特性和抓取要求,对基础动作进行细微但关键的调整。
整个训练过程还采用了"师生传授"的策略。首先训练一个"老师"策略,这个老师能够获取完整的环境信息,包括物体的精确位置、状态等。然后,老师将自己的知识传授给"学生"策略,而学生只能依靠视觉传感器获取的信息来做决策。这种设计确保了最终部署的机器人能够在真实环境中可靠地工作,即使面对不完美的感知信息也能做出正确的判断。
机器人的"安全意识":负向功能感知的突破
在日常生活中,我们拿起一把菜刀时会本能地握住刀柄而避开刀刃,这种"安全意识"对人类来说是如此自然,以至于我们很少意识到它的存在。然而对机器人来说,学会这种"知道什么不能碰"的能力却是一个巨大的挑战。AffordDex系统的最大创新就在于赋予了机器人这种"安全意识"。
研究团队开发的负向功能感知模块就像给机器人安装了一套"危险检测雷达"。这套系统能够自动识别物体上那些不适合抓取的区域,比如刀具的刃部、瓶子的易碎部分、或者工具的尖锐末端。这个过程的实现相当巧妙,研究团队并没有试图让计算机直接理解"危险"这个抽象概念,而是将问题转化为一个更容易解决的分类任务。
具体来说,系统首先会对原本没有纹理的3D物体模型添加合理的表面材质,这就像给一个素描添加色彩和质感一样。然后从六个不同角度对物体进行拍照,创建一套全方位的视觉档案。接下来,系统会询问先进的视觉-语言模型:"这个物体的哪些部分是不应该触碰的?"比如对于一把刀,模型会回答"刀刃部分"。
最精妙的部分来了。系统不会让计算机直接在图像中寻找"刀刃",而是先使用SAM(Segment Anything Model)技术将物体的每个部分都精确地"圈出来",就像用不同颜色的马克笔在图片上标记不同区域一样。然后使用CLIP模型来判断这些被圈出的区域中,哪一个最符合"刀刃"的描述。这种方法将复杂的理解任务转化为相对简单的匹配任务,大大提高了准确性。
通过这种方式,机器人不仅能识别显而易见的危险,比如刀刃和针尖,还能理解更微妙的抓取禁忌。比如,它知道抓取蜡烛时应该避开烛芯附近的蜡面,抓取耳机时不应该用力捏压音响部分。这种细致入微的"安全感知"让机器人的抓取行为变得更加智能和可靠。
从理论到实践:让机器人在现实世界中大显身手
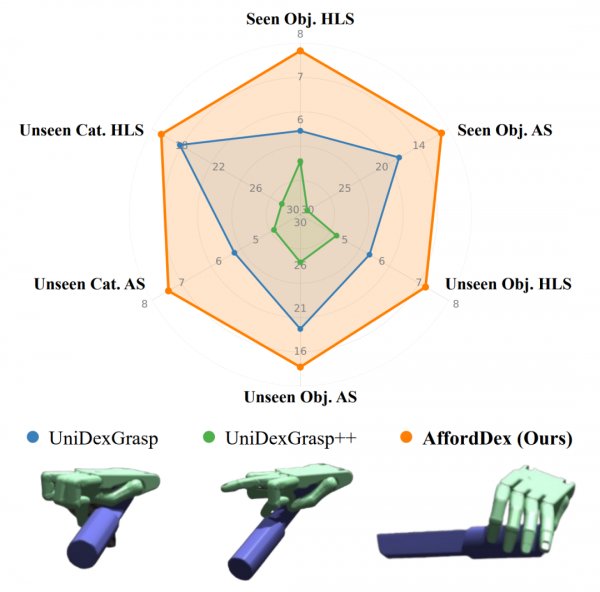
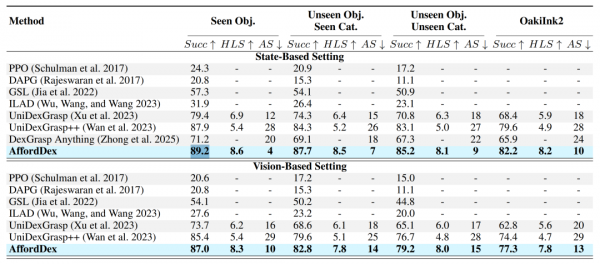
理论上的突破只有在实际应用中得到验证才有意义。研究团队在多个测试环境中对AffordDex系统进行了全面的评估,结果令人印象深刻。在包含3165个不同物体实例的UniDexGrasp数据集上,AffordDex在已知物体上的成功率达到了89.2%,在未见过的物体上也能保持87.7%的高成功率,甚至对完全陌生的物体类别也能达到85.2%的成功率。
更重要的是,这些成功的抓取不仅仅是"能拿起来"那么简单。研究团队引入了两个评估机器人"素养"的新指标:人类相似度评分和功能适宜度评分。人类相似度评分由先进的AI模型通过观看机器人的抓取视频来评估,就像让一位舞蹈老师评判学生的动作是否优雅自然一样。功能适宜度评分则检查机器人是否选择了正确的抓取位置,避开了危险区域。
在这两个关键指标上,AffordDex都表现出色。其人类相似度评分达到8.6分(满分10分),远超其他先进系统的5.4分。功能适宜度评分更是只有4分(分数越低越好),而对比系统普遍在28分左右,这意味着AffordDex几乎总是能选择最安全、最合适的抓取位置。
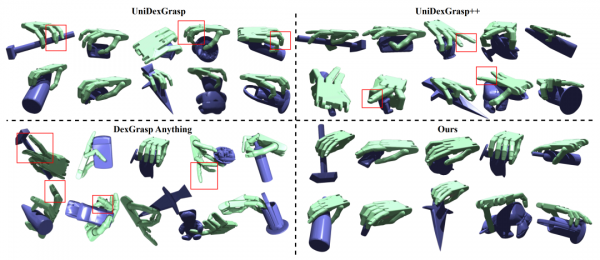
为了验证系统的稳健性,研究团队还进行了一系列消融实验,就像拆解一台精密仪器来了解每个部件的作用一样。实验发现,如果去掉人类动作模仿阶段,机器人虽然仍能完成抓取任务,但动作会变得僵硬不自然,就像一个没有学过礼仪的人吃饭时姿势奇怪但勉强能填饱肚子。如果去掉负向功能感知模块,机器人的抓取成功率会显著下降,更重要的是会频繁触碰危险区域,就像一个不懂安全常识的新手厨师总是用错误的方式拿刀。
实验还显示,AffordDex的设计理念具有很强的通用性。当研究团队将其核心模块应用到其他现有的机器人抓取系统上时,这些系统的表现都得到了显著改善。这证明了AffordDex不仅是一个优秀的独立系统,更是一套可以广泛应用的设计原则和技术方案。
展望未来:机器人助手的美好愿景
AffordDex的成功不仅仅是技术上的突破,更预示着机器人技术即将迎来一个重要的转折点。过去,我们对机器人的期待往往停留在"能完成任务"的层面,就像早期的洗衣机只要能把衣服洗干净就算成功。而现在,我们开始期待机器人能够像人类一样优雅、安全、智能地完成各种操作。
这项研究的意义远远超出了抓取这一个动作本身。它展示了一种全新的机器人学习范式:不是简单地让机器模仿人类的最终结果,而是让机器理解人类行为背后的逻辑和原则。这种"知其然且知其所以然"的学习方式,将为未来的通用机器人奠定坚实的基础。
在不久的将来,我们可能会看到这样的场景:家庭服务机器人能够像熟练的管家一样整理房间,知道该轻拿轻放的瓷器和可以随意移动的塑料制品;医疗机器人能够像经验丰富的护士一样协助手术,精确地递送器械而绝不会误碰敏感部位;工业机器人能够像技艺精湛的工匠一样处理各种材料,既保证效率又确保安全。
当然,任何技术都有其局限性。目前的AffordDex系统主要依赖六个固定视角的图像来理解物体,这在处理具有复杂凹槽或隐蔽结构的物体时可能会遇到困难。研究团队也坦诚地指出了这一点,并建议未来的研究可以探索基于3D体积表示的功能感知方法,就像从平面照片升级到立体扫描一样。
此外,虽然当前系统在测试环境中表现出色,但真实世界的复杂性和不确定性仍然是一个挑战。光照变化、物体磨损、环境干扰等因素都可能影响系统的表现。不过,这些挑战也正是下一阶段研究的动力和方向。
从更广阔的视角来看,AffordDex代表了人工智能发展的一个重要趋势:从单纯追求性能指标向注重安全性、可解释性和人机协调性转变。这种转变不仅体现在技术层面,更反映了我们对人工智能角色的重新思考。我们希望的不是一个完美但冷漠的机器,而是一个既能干又懂事的智能伙伴。
AffordDex最大的价值可能不在于让机器人变得多么强大,而在于让机器人变得更加"懂事"。就像培养一个孩子,我们希望的不仅仅是他能完成各种任务,更希望他知道什么该做、什么不该做,能够在复杂的世界中做出正确的判断。这项研究为实现这样的机器人迈出了坚实的一步,也为我们描绘了一个机器人与人类和谐共处的美好未来。
https://arxiv.org/pdf/2508.08896
Q&A
Q1:AffordDex系统相比传统机器人抓取技术有什么优势?
A:AffordDex最大的优势是让机器人学会了"安全意识"和"优雅动作"。传统系统只关心能否抓起物体,就像力大无穷但笨手笨脚的巨人。而AffordDex不仅成功率更高(89.2%),更重要的是能像人类一样选择安全的抓取位置,避开刀刃等危险区域,动作也更加自然流畅,人类相似度评分达到8.6分。
Q2:负向功能感知模块是如何让机器人知道哪里不能碰的?
A:这个模块就像给机器人安装了"危险检测雷达"。它先给3D物体添加纹理材质,从六个角度拍照,然后询问AI模型哪些部分危险。接着用SAM技术将物体各部分圈出来,再用CLIP模型匹配哪个区域最符合危险描述。这样机器人就能自动识别并避开刀刃、尖锐部分等禁区。
Q3:AffordDex系统这项技术什么时候能应用到实际生活中?
A:虽然研究成果很亮眼,但距离实际应用还需要时间。目前系统主要在实验环境中测试,真实世界的光照变化、物体磨损等复杂情况仍是挑战。不过这项技术为未来的家庭服务机器人、医疗机器人和工业机器人奠定了重要基础,预计在3-5年内可能会看到相关技术的商业化应用。
来源:至顶AI实验室
好文章,需要你的鼓励


OpenAI CEO阿尔特曼承认当前处于AI泡沫期
OpenAI首席执行官Sam Altman表示,鉴于投资者的AI炒作和大量资本支出,我们目前正处于AI泡沫中。他承认投资者对AI过度兴奋,但仍认为AI是长期以来最重要的技术。ChatGPT目前拥有7亿周活跃用户,是全球第五大网站。由于服务器容量不足,OpenAI无法发布已开发的更好模型,计划在不久的将来投资万亿美元建设数据中心。

阿里巴巴突破AI说话人视频生成技术壁垒:首次实现动作自然度、唇同步准确性和视觉质量的完美平衡
阿里巴巴团队提出FantasyTalking2,通过创新的多专家协作框架TLPO解决音频驱动人像动画中动作自然度、唇同步和视觉质量的优化冲突问题。该方法构建智能评委Talking-Critic和41万样本数据集,训练三个专业模块分别优化不同维度,再通过时间步-层级自适应融合实现协调。实验显示全面超越现有技术,用户评价提升超12%。

英伟达发布全新小型开源模型Nemotron-Nano-9B-v2,支持推理开关控制
英伟达推出新的小型语言模型Nemotron-Nano-9B-v2,拥有90亿参数,在同类基准测试中表现最佳。该模型采用Mamba-Transformer混合架构,支持多语言处理和代码生成,可在单个A10 GPU上运行。独特的可切换推理功能允许用户通过控制令牌开启或关闭AI推理过程,并可管理推理预算以平衡准确性和延迟。模型基于合成数据集训练,采用企业友好的开源许可协议,支持商业化使用。

UC Berkeley团队突破AI内存瓶颈:让大模型推理快7倍的神奇方法
UC Berkeley团队提出XQUANT技术,通过存储输入激活X而非传统KV缓存来突破AI推理的内存瓶颈。该方法能将内存使用量减少至1/7.7,升级版XQUANT-CL更可实现12.5倍节省,同时几乎不影响模型性能。研究针对现代AI模型特点进行优化,为在有限硬件资源下运行更强大AI模型提供了新思路。
2025
08/15
16:48
分享
点赞

英伟达发布全新小型开源模型Nemotron-Nano-9B-v2,支持推理开关控制
谷歌翻译将集成AI功能并增加游戏化学习模式
边缘AI基础设施的现实挑战与解决方案
Hugging Face:企业在不牺牲性能下降低AI成本的5种方法
阿里推出Ovis2.5:多模态大语言模型的又一重要突破
对话谷歌副总裁Karen Teo:“短剧”“AI应用”现象级出海,我们看到中国开发者的三种内核
谷歌Gemini大模型登陆甲骨文云平台
Linux的微内核替代方案?Debian/Hurd证明微内核Unix梦想仍在继续
你的每一个问题、每一条评论,我都在记录
2035年最热门的十大颠覆性产业
AI"教父"提出让AI具备母性本能引发争议
生成式AI助力MIT科学家对抗超级细菌
