
大模型到底哪家强?红杉xbench:告别刷题时代,AI评测应该以解决问题的能力为基准 原创
不知道大家有没有这样一种体验,明明模型在各种AI基准评测中的得分很高,但在真正使用时,却状况百出,基本处于一个低可用,甚至不可用的状态。
为什么会出现这样反常识的现象呢?
这里我们就不得不提一下目前主流的AI基准评测体系,虽然目前AI基准评测体系五花八门,但都有一个共有的特点,题库,通过预设的题库中的题目让AI模型进行解答,通过题目结果进行评测。
貌似很公平,但互联网是有记忆的,只要题库中的题目出现过,理论上都能查到,所以,模型很容易就可以“爆库刷题”,进而在评测中取得高分。
但模型的能力与刷题,或者说会做题其实并没有什么关系。
很显然,我们需要一套全新的基准评测体系,一种基于AI模型真实解决问题能力,而不是做题能力的评测基准。
于是,Xbench就此诞生。
Xbench是知名投资机构红杉中国推出一款全新的AI基准测试工具,旨在真实地反映AI的客观能力,其在评估和推动AI系统提升能力上限与技术边界的同时,会重点量化AI系统在真实场景的效用价值,并采用长青评估的机制,去捕捉AI产品的关键突破。
其实Xbench项目开始于2023年3月,构建伊始也是采用题库模式,不出意外,被爆了,主流模型从20,30分快速刷到了90-100分,Xbench团队于2024年重新评估与更新替换题库,没有意外,又被爆了,再换,再爆…
2025年3月,频繁被爆的Xbench团队停止了更新题库,开始质疑现有评估方式,最终,他们决定跳出“研究视角”惯性,转向“市场与业务视角”,从AI落地真实解决问题的能力出发,在2025年5月底,推出了Xbench,并发布论文《xbench: Tracking Agents Productivity,Scaling with Profession-Aligned Real-World Evaluations》。
研究背景:顶尖学府的跨界合作探索
Xbench由红杉联合全球多所知名高校的研究者一起完成,包括卡内基梅隆大学、麻省理工学院、斯坦福大学、牛津大学、复旦大学等18所知名院校。论文发表于2025年6月,目前已经公开在arXiv上。从作者署名可以看出,这是一个"产学研"结合项目,核心贡献者中既有学术界的研究者,也有来自头猎公司和营销机构的业内专家。
研究团队选择招聘和营销两个领域作为起点,这两个领域都具备一个共同特点:工作流程相对标准化,同时又高度依赖人的经验和判断,而且这两个领域的工作成果可以用相对客观的标准来衡量,招聘的成功率、营销的转化效果都有明确的数据支撑。
核心成果:从技术思维到商业价值
xbench的核心理念非常直接,评测应该与专业实践紧密结合,它不是简单地测试AI的某项孤立能力,而是评估AI在特定专业领域中完成真实任务的表现。
这种评测方式与传统评测有着根本区别。
首先是评测方向的不同,传统评测关注AI在哪些方面存在不足,而xbench关注AI在哪些专业场景中能创造最大价值。
再就是任务的分布不同,传统评测追求任务的多样性,而xbench则聚焦于由领域专家定义的、具有实际价值的任务。
除了以上两点,Xbench相比传统评测,环境和反馈机制也不相同,传统评测通常在静态或模拟环境中进行,而xbench尽量模拟真实工作环境,并使用与业务指标紧密相关的评分标准。
xbench的评测框架设计也非常实用,它先根据市场规模和技术成熟度选择评测领域。市场规模决定了AI能创造的总价值上限,而技术成熟度则影响开发难度。然后由领域专家主导评测任务的设计,确保评测任务与实际工作需求一致,从而确保评测结果能够真实反映AI在实际应用中的价值。
研究团队已经实现了两个具体的评测集:招聘和营销。
在招聘领域,评测任务包括公司映射、人才信息收集和人才筛选,AI需要理解职位要求,知道哪些公司有类似人才,分析这些人才的背景和跳槽可能性,这需要AI具备深度的行业理解能力,而不仅仅是简单的信息检索。
营销领域的评估则关注网红与广告主需求的精准匹配,AI需要根据产品特性、目标受众、预算限制等多维度因素,为客户推荐最合适的网红合作伙伴,这需要AI理解复杂的商业逻辑和市场动态。
这些任务都来源于真实业务场景,并由行业专家参与设计。
方法评析:从能力评测到价值预测
xbench的方法论有几个突出特点,首次将评测与实际业务价值紧密关联,传统评测通常关注模型在特定任务上的准确率,而xbench更关心模型能否提供实际的商业价值,这种转变将AI从实验室带入了实际业务场景。
同时xbench引入了"技术-市场匹配度"(Technology-Market Fit, TMF)的概念,这是一个非常实用的框架,它分析评测指标与成本之间的关系,判断技术是否已经达到了可商业化的程度。具体来说,它通过市场可接受曲线和技术可行曲线的交叉区域,来估计AI每单位任务能创造的价值。
Xbench还建立了长期更新的评测机制,AI领域发展迅速,单一时间点的评测结果很快就会过时,xbench通过持续更新评测结果,跟踪不同AI产品的能力变化,甚至可以发现那些进步迅速的"黑马"产品。
在具体实现上,招聘评测包括50个真实的猎头业务场景,涵盖公司映射、信息检索和人才搜索三类任务,这些任务评估AI在行业知识、人才搜索等方面的能力。
营销评测则要求AI代理根据50个广告主需求,从836个候选网红中找出最合适的匹配。评测过程使用评判模型作为评判器,根据专业评分标准给出1-5的评分。
Xbench最大的挑战在于如何平衡不同利益相关者的需求研究团队需要让学术界认可其科学严谨性,同时要让业界认可其实用价值。这种双重约束导致了一些设计上的妥协。比如在营销任务中,虽然使用了真实的广告需求,但网红数据库相对较小(836个候选者),这与真实的营销环境中数以万计的候选者相比还有不小差距。
还有就是文化和地域的适用性,目前的招聘任务主要基于中国的商业环境,营销任务则更多考虑北美市场,不同文化背景下的商业实践存在显著差异,这可能会影响评估结果的普适性。
结论:不止于排名,更为AI进化指明新方向
研究团队对当前主流AI模型通过Xbench进行了评测,OpenAI的o3模型在两个测试领域都位居榜首。
这个结果并不令人意外,因为o3采用了端到端的强化学习训练,特别针对复杂任务进行了优化。在招聘任务中,o3获得了78.5分的平均成绩,而师出同门的GPT-4o只有38.9分。
同时,模型规模并不是决定性因素:Gemini-2.5-Pro和Gemini-2.5-Flash的表现相当接近,这说明在特定任务上,模型的架构设计可能比参数数量更重要。
Perplexity-Search在招聘任务中的优异表现,甚至超过了其研究版本Perplexity-Research。这个现象反映了过度复杂的推理过程可能会引入更多幻觉,反而降低任务表现。
在营销任务中,各模型的得分普遍较低,最高的o3也只获得了50.8分,因为营销任务的主观性确实更强,需要对文化背景、用户心理有深入理解;同时,当前的AI模型在处理涉及创意和审美判断的任务时还有很大提升空间。
Deepseek R1虽然在数学和编程任务上表现出色,但在这两个商业任务中的表现相对较差,这其实很好的说明了技术能力与商业应用能力之间的差异,能够解决复杂数学问题的AI,不一定能够理解商业场景中的微妙需求。

相比这些评分排名,Xbench还利用TMF分析框架,判断一个AI产品究竟是处于概念炒作阶段,还是已经具备了落地的潜力 。这大大降低了技术选型和投资决策的风险。
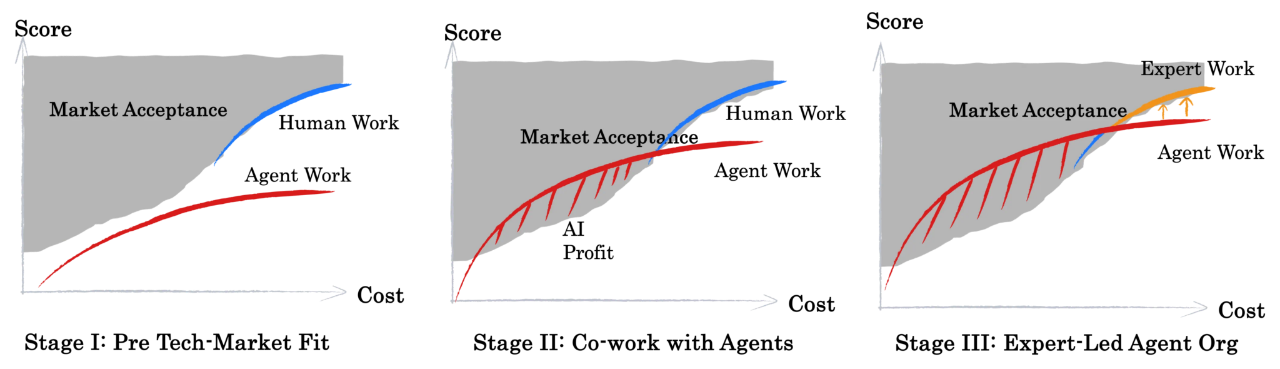
Xbench展望了AI应用的三个阶段。
第一阶段,技术与市场脱节,AI只是一个昂贵的玩具或工具,无法大规模创造价值 。
第二阶段,人机协作,AI开始在一些重复性工作中辅助人类,技术可行性与市场接受度开始出现重叠 。
第三阶段,专业Agent主导,在领域专家的引导下,高度专业化的AI Agent能够系统性地完成核心工作流,专家则从执行者转变为AI的设计者和管理者 。
我们看到,xbench其实为AI评测带来了一个新的视角,不再仅仅关注AI能做什么,而是关注AI能为专业领域创造多少价值。对于AI厂商来说,不再需要去猜测市场需要什么,也不用盲目地在一些通用能力上“内卷”,来自真实业务的考题,就是最直接的需求说明书,攻克这些任务,就意味着离商业成功更近了一步。
至顶AI实验室洞见
xbench的出现,标志着AI发展进入了一个新的阶段,我愿意称之为“下半场”。
AI的上半场,是“大炼模型”的时代,其核心逻辑是通过投入海量的计算资源和数据,不断扩大模型的规模,从而在各种通用能力基准上取得突破,这个阶段诞生了像GPT-4,claude-4这样的里程碑,证明了暴力美学的有效性,也完成了对公众和市场的AI启蒙。
而AI的下半场,将是“精耕场景”的时代,当模型的通用能力达到一个瓶颈期后,竞争的焦点不再是谁的模型更大、参数更多,而是谁能将这些强大的能力,与真实的行业场景做更深度、更高效的结合,从而创造出实实在在的商业价值。
下半场的比赛,需要一套全新的游戏规则,xbench恰恰就是为这个新赛段量身定做的,但同时,xbench又不仅仅是一个评测工具,它更是一个价值导向的指向标,正在引导整个AI生态,从对“智商”的单一崇拜,转向对“价值”的务实追求。
这,或许才是AI技术真正走向成熟的开始。
论文地址:
https://arxiv.org/pdf/2506.13651
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
好文章,需要你的鼓励


依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
今天讲的出海案例是依米康,这家数据中心温控与液冷设备厂商正在把泰国纳入海外交付体系,并用生产线、总装车间和焓差实验室承接算力设施订单。

人民大学、上海AI实验室等联合打造的“全能生物AI“:一个模型搞定分子、蛋白质和自然语言的终极尝试
BioMatrix是首个将分子序列、分子三维结构、蛋白质序列、蛋白质三维结构和自然语言统一在单一语言模型中的生物基础模型,在80项任务中77项达到最优或第二优。

Salesforce推出Help Agent,简化AI客服部署流程
Salesforce正式推出Help Agent,这是基于Agentforce平台的预封装AI客服智能体,可在数分钟内连接企业知识库、操作功能及网页、短信、语音等沟通渠道。该产品同步推出按解决率计费模式,每次成功自主解决客户问题收费2美元,无需按token或操作次数计费。Help Agent支持低代码构建,内置测试功能,并配备全新客户服务门户。该产品预计于2026年7月正式上线。

浙江大学研究团队打造“技能护栏“:让AI电脑助手在危险环境中也能安全学习和工作
浙江大学提出SKILLHARNESS框架,通过为AI电脑助手的每项技能附加安全边界,从成功、失败和风险三类经历中学习,使AI在动态危险环境中安全高效地完成任务。
2025
07/10
17:53
分享
点赞

依米康泰国接入数据中心温控交付,液冷生产线与焓差实验室补齐制造测试
Salesforce推出Help Agent,简化AI客服部署流程
智能体资源发现协议ARD:谷歌微软等巨头联手解决AI智能体工具管理难题
IBM首次实现亚纳米芯片技术突破,可集成近千亿颗晶体管
当AI包揽数学运算,数学家的意义何在?
生成式AI正在让员工丧失独立思考能力
特朗普签署量子行政令,誓要成为"量子信息科技超级大国"
亚马逊追加130亿美元投资印度AI基础设施
Craig Primack博士:远程医疗如何填补肥胖症诊疗缺口
OpenAI与Broadcom联合推出专为AI推理打造的定制芯片Jalapeno
IBM宣称推出全球首个亚纳米芯片技术
OpenAI 迎来 AI 研究大牛 Noam Shazeer 加盟
Gartner:到2030年,守护代理将占据10%-15%的代理型AI市场份额
AI Agent制造业落地实战-从技术场景到效益提升的应用场景全解析
NVIDIA AgentIQ:高效连接和优化AI Agent团队的开源工具包
Cloudera:AI智能体的兴起让数据隐私的重要性日益凸显
微软开源AI Agent大更新,重塑智能体!多层级更强架构
Cloudera前瞻:数据与AI的碰撞,将如何驱动企业变革与增长
CIO们需要注意:AI代理将如何定价?
Multi-Agent ,知多少?
对话澜码科技创始人周健:大模型的下一个开垦地,AI Agent!
澜码科技发布企业级AI Agent平台AskXBOT,用专家知识赋能基层业务单元
