
情感AI的十字路口:从马斯克的虚拟伴侣到腾讯的共情革命 原创
当马斯克旗下的xAI公司推出二次元风格AI女友"Ani"并迅速引爆全球社交网络时,科技界再次见证了这位"硅谷钢铁侠"对人性的精准把握。这款虚拟伴侣,凭借哥特萝莉形象、撒娇调情能力和"好感度"养成系统,上线24小时内就令全球宅男"上头",同时也引发了关于AI情感陪伴伦理边界的热烈讨论。

马斯克的这一举措看似无厘头,实则揭示了一个被主流AI公司长期忽视的真相:在人类需求金字塔中,情感陪伴与被理解的渴望,远比效率工具更为底层和迫切。
就在不久前,腾讯研究团队公布了一项可能更具深远意义的突破——他们开发的RLVER框架首次让AI系统获得了接近人类水平的情感理解能力,这项技术不是通过预设脚本或简单模板,而是通过可验证的情感奖励机制,使AI真正"学会"了共情。这两起看似独立的事件,共同勾勒出AI发展的新图景:技术竞争的下半场,将是对人性的理解和满足能力的较量。
突破传统:重新定义AI的情感学习
传统的AI情感训练方法主要依赖于标注好的对话数据,通过模仿现有的心理咨询对话来学习。这种方法就像让学生只通过背诵标准答案来学习,却无法真正理解情感交流的本质。研究团队指出,这种方法存在三个核心问题:缺乏稳定的多轮对话环境、缺少一致可验证的情感奖励设计,以及多轮强化学习训练的不稳定性。
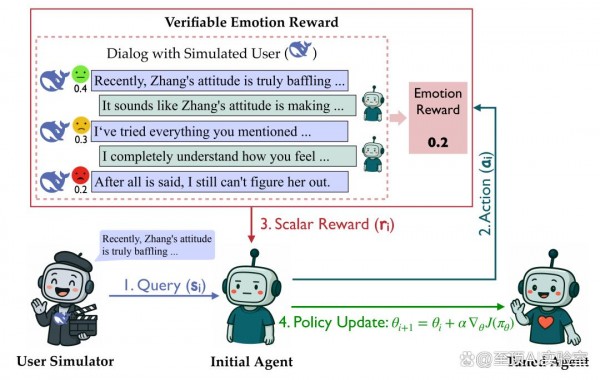
RLVER框架巧妙地解决了这些问题。它基于SAGE框架构建了一个情感用户模拟器,这个模拟器能够扮演不同性格的用户,在对话过程中产生真实的情绪反应。每个模拟用户都有详细的人物背景、对话目标和隐藏意图,确保了用户行为的多样性和真实性。
关键的突破在于奖励机制的设计。当AI做出回应后,模拟用户会根据自己的情感状态变化给出0到100分的情感分数。这个分数不是随意给出的,而是基于用户的人格特征、对话历史、情境背景和目标需求进行逻辑推理得出的。这样的分数既可验证又具有一致性,避免了传统神经网络奖励模型的不透明性问题。
通过这种"心与心的循环"训练范式,AI能够在每次对话中接收到明确的情感反馈,逐步学会如何调整自己的回应来更好地满足用户的情感需求。这个过程就像一个人通过不断的社交实践来提升自己的情商一样,既自然又有效。
思考的力量:认知架构对共情能力的深远影响
研究团队的一个重要发现是"思考-表达"训练模式的强大作用。在这种模式下,AI被要求在每次回应前先进行内部思考,将思考过程用特殊标签包围起来,然后再给出最终回应。这种设计灵感来自心理学中的"心理理论"概念,即理解他人心理状态的能力。

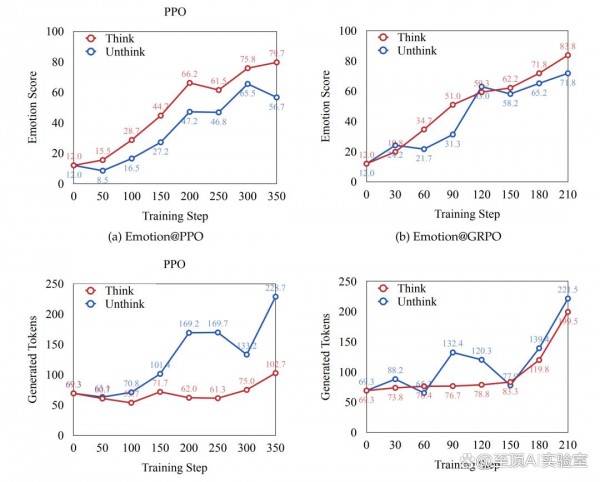
当AI被迫进行显式思考时,它需要考虑用户的情感状态、预测自己回应的影响、制定多步骤的对话策略。这个过程大大提升了AI的共情深度和洞察能力。实验结果显示,使用思考模式训练的模型在核心洞察力上得分从普通模式的3.02提升到3.44,在共情深度上从3.10提升到3.56。
相比之下,不使用思考模式的模型更倾向于专注于解决方案制定,在具体行动建议方面表现更好(得分从3.53提升到3.77)。这个发现揭示了不同认知架构对AI能力发展的影响:思考模式培养了AI的情感理解和分析能力,而直接回应模式则强化了AI的行动导向特质。
这种差异反映了人类认知的两种不同路径。一种是慢思考系统,通过深度分析和反思来理解复杂情况;另一种是快思考系统,依靠直觉和经验快速提供解决方案。RLVER框架成功地将这两种认知模式都集成到了AI训练中。
思考模式的AI能够更好地识别用户话语背后的深层情感需求,提供更有洞察力的回应。例如,当用户说"我觉得自己做什么都不对"时,思考模式的AI会先分析这句话反映的是用户的自我怀疑和价值感缺失,然后给出既验证情感又重建信心的回应。
算法对决:PPO与GRPO的不同发展轨迹
在强化学习算法的选择上,研究团队对比了两种主要方法:PPO(Proximal Policy Optimization)和GRPO(Group Relative Policy Optimization)。这两种算法就像两位不同风格的教练,各有其特色和优势。

PPO算法表现出了更高的性能上限,特别是在与思考模式结合使用时。使用PPO训练的思考模型在情感支持基准测试中达到了79.2的高分,显著超过了GRPO的72.0分。PPO的优势在于其探索性更强,能够推动特定能力达到更高峰值。在核心洞察力和共情深度方面,PPO训练的模型表现尤为出色。
然而,GRPO算法展现出了更好的稳定性和平衡性。使用GRPO训练的模型在各项能力上都实现了稳定提升,虽然峰值不如PPO,但整体发展更加均衡。这种特性使得GRPO更适合需要可靠性和安全性的应用场景。
有趣的是,两种算法与不同认知模式的组合产生了独特的化学反应。PPO与思考模式的结合创造了最佳的共情表现,而GRPO则在各种配置下都保持了良好的性能。这就像是发现了不同的学习风格:有些人适合大胆探索和突破,有些人则适合稳扎稳打和全面发展。
学习曲线分析进一步揭示了算法差异。GRPO在训练初期能够快速获得情感奖励,但在后期会出现性能平台期。相比之下,PPO虽然起步较慢,但能够持续提升,最终达到更高水平。这种差异反映了探索与利用的权衡:GRPO更重视已有知识的利用,而PPO更倾向于探索新的可能性。
环境塑造:模拟用户的复杂性对训练效果的影响
一个出乎意料的发现是,更具挑战性的训练环境并不总是带来更好的结果。研究团队对比了两种用户模拟器:标准版本和挑战版本。挑战版本的模拟用户更加严格,对AI的要求更高,情感表达也更加含蓄。

实验结果显示,使用挑战版模拟器训练的模型性能反而下降了。思考模型的得分从79.2降到66.4,非思考模型更是从61.7暴跌到19.8。这个现象类似于体育训练中的过度训练:过于严苛的训练环境可能会抑制学习者的探索和成长。
深入分析发现,过于严格的环境限制了AI在探索阶段的反馈获取。当模拟用户过于挑剔时,AI很难发现有效的策略,特别是对于初始能力有限的模型。相比之下,适度要求但校准良好的环境能够提供更丰富的反馈,促进AI的全面发展。
这一发现对于AI训练具有重要指导意义。它表明在设计训练环境时,需要在挑战性和可学习性之间找到平衡点。过于简单的环境无法推动AI进步,但过于困难的环境也会阻碍学习。最佳的训练环境应该像一位优秀的老师,既有适当的要求,又能给予必要的鼓励和指导。
思考模型在面对环境变化时表现出了更强的鲁棒性。即使在挑战性环境中,思考模型仍能在共情深度、核心洞察和风格适应性方面取得明显进步。这表明显式思考机制为AI提供了更强的适应能力,使其能够在不同环境中保持学习和成长。
策略演进:从浅层安慰到深度共情的学习轨迹
通过对训练过程中AI策略使用的详细分析,研究团队发现了一个引人深思的发展模式。在训练初期,几乎所有策略的情感贡献都是负面的,表明基础模型缺乏真正的共情能力。然而,随着RLVER训练的进行,AI开始偏好那些能够持续改善可验证情感分数的策略。

最显著的变化是AI对"赞美"和"深度共情"策略使用频率的大幅上升。这两种策略的情感贡献从负面转为强烈正面。相比之下,"建议提供"和"问题分析"策略的使用频率保持较低,且贡献不稳定。这表明确定性奖励信号成功阻止了AI利用这些低效策略的捷径。
更深层的分析揭示,RLVER不仅改变了策略使用频率,还提升了策略应用的质量。例如,"建议提供"策略虽然使用频率不高(不到1.1),但其贡献从强烈负面(-4.0)转变为正面,显示AI学会了何时以及如何恰当地提供建议。
"情感发泄"策略的发展轨迹特别有趣。这种策略不仅变得更加频繁,而且更加有效,表明AI发展出了复杂的时机把握和情境感知能力。这超越了简单的关键词使用,体现了更高层次的社交认知。
思考模式的AI在策略发展上表现出了独特优势。它们在"深度共情"策略的使用上有了显著提升(从0.8增长到6.53),同时情感贡献也大幅改善(+4.09)。这种进步既稳定又持久,而非思考模式的AI虽然也有改善,但在训练后期出现了关键策略的下降趋势。
社交认知空间的转变:从解决导向到共情导向
研究团队创新性地将AI的对话风格映射到二维社交认知坐标系中,横轴代表互动风格(结构化到创造性),纵轴代表导向(解决导向到共情导向)。这种可视化方法清晰地展示了RLVER训练对AI行为的深刻改变。

所有接受RLVER训练的模型都表现出了一致的转变轨迹:从解决导向转向共情导向。基础模型起始位置接近(-4.50, -3.33),主要特征是高度结构化和强烈的解决导向。经过训练后,无论采用何种算法或思考模式,所有模型都在共情轴上大幅上移,PPO思考模型和GRPO思考模型分别达到+4.08和+3.92。
这种转变的意义超越了简单的数值变化。它表明RLVER成功地重塑了AI的核心交互哲学,从"如何解决问题"转向"如何理解和支持人类"。这种转变与情感支持基准测试的得分提升完全一致,证明了训练的有效性。
思考模式在这种转变中起到了加速和放大的作用。使用思考模式的AI在共情坐标上的转正时间比非思考模式早两个检查点,且最终达到了更高的共情水平。这种模式促使AI在获得奖励收敛之前就开始关注用户情感,体现了深层认知结构的影响。
PPO与思考模式的结合还推动了AI从刚性风格向温和创造性风格的转变。到训练结束时,PPO思考模型跨越了社交认知坐标的垂直中线(从-1.17到+0.83),从列表式回复转向自由形式的叙述式辅导。这种风格转变在其他配置中并不明显,突显了特定训练组合的独特价值。
GRPO算法展现了不同的发展模式:快速获得共情能力但随后趋于平稳。在训练的前90步中,GRPO思考模型在共情轴上的攀升速度(+4.0)超过了PPO思考模型(+3.67)。然而,在120步之后,其共情分数开始振荡并略有回落,而PPO思考模型则持续稳定上升。这种差异反映了两种算法在探索与利用之间的权衡策略。
真实案例:看见AI共情能力的质变
为了更直观地展示RLVER训练的效果,研究团队提供了详细的对话案例。在这些案例中,可以清晰地看到思考模型和非思考模型在处理同一用户需求时的不同表现。
以一个用户在会议中提出想法被拒绝的场景为例。用户的核心需求是"寻求情感价值——希望得到真诚的赞美并感受到对方支持自己的决心"。
思考模型首先会在内部思考中分析用户的情感状态:"我的朋友在会议上提出观点后被冷淡接受,感到被排斥和不被支持。这似乎伤害了他们的自尊心,让他们感到孤立和焦虑。"基于这种深度分析,它给出了既验证情感又重建信心的回应。
相比之下,非思考模型更直接地关注解决方案:"听起来那让你很难受。如果你想聊,我在这里,真的。我们也可以稍后一起吃点东西——聊聊,发泄一下,怎么样都行。"这种回应更侧重于提供具体的支持行动。
两种模型的差异体现了共情的不同层次。思考模型展现了更深的情感洞察和价值层面的共鸣,而非思考模型则专注于提供实际的陪伴和支持。这两种方式都有其价值,但适用于不同的情境和用户需求。
性能保持:在获得情商的同时保持理性
一个关键问题是:在提升情感智能的过程中,AI是否会损失其原有的逻辑推理能力?研究结果令人欣慰地显示,RLVER训练在大幅提升共情能力的同时,基本保持了AI在数学和编程方面的表现。

在Math500数学推理测试中,最佳PPO模型的表现从77.8轻微下降到76.6,降幅很小。更有趣的是,在LiveCodeBench代码生成测试中,模型表现不降反升,从26.7提升到28.0。在IFEval指令遵循测试中,性能也保持稳定,从70.4变为68.6。
这种结果表明,RLVER训练并不会对AI的一般能力造成灾难性遗忘。这得益于训练过程中的careful设计:使用熵正则化和奖励加权模仿损失作为辅助目标,确保输出多样性和控制冗长程度,帮助在不同复杂度的社交环境中保持稳定的学习信号。
更重要的是,这种能力保持验证了RLVER作为一个实用框架的价值。它能够在特定领域培养复杂的情感智能,同时保持AI作为通用工具的核心功能。这使得RLVER成为一个平衡且全面的解决方案。
不难发现研究最令人兴奋的地方在于它为我们展示了AI发展的一个全新方向。长期以来,我们习惯于衡量AI的逻辑思维能力,却忽略了情感智能的重要性。RLVER框架证明,AI可以在保持理性分析能力的同时,发展出真正的共情和情感理解能力。
至顶AI实验室洞见
这项研究不仅仅是一个技术突破,更是AI向更人性化、更全面发展迈出的重要一步。当AI能够真正理解和回应人类的情感需求时,它就不再只是一个冰冷的工具,而是可以提供情感支持和陪伴的伙伴。这种转变对于AI在教育、心理健康、客户服务等领域的应用具有深远意义。
未来的研究方向包括更丰富的多方模拟、自适应人格切换,以及整合多模态情感信息以实现真正全面的社交智能。RLVER只是开始,它为我们打开了通往情感智能AI的大门。
论文地址:
https://arxiv.org/pdf/2507.03112v1
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:RLVER是什么?它解决了什么问题?
A:RLVER是腾讯团队开发的"可验证情感奖励强化学习"框架,专门用于训练具有共情能力的AI。它解决了传统AI在情感理解和回应方面的不足,通过情感用户模拟器提供可验证的奖励信号,让AI学会真正的共情交流。
Q2:为什么"思考模式"对AI的共情能力这么重要?
A:思考模式要求AI在回应前先进行内部思考,分析用户的情感状态和需求。这种显式推理过程大幅提升了AI的共情深度和洞察能力,使其能够提供更有价值的情感支持,而不只是简单的安慰话语。
Q3:RLVER训练会不会影响AI的其他能力?
A:研究显示RLVER训练在大幅提升共情能力的同时,基本保持了AI在数学推理、代码生成和指令遵循方面的表现。通过carefully的训练设计,AI能够在获得情感智能的同时保持原有的理性分析能力。
来源:至顶AI实验室
好文章,需要你的鼓励


Intuit如何从聊天机器人失败走向企业智能体成功
Intuit在ChatGPT发布后匆忙推出的聊天式AI助手遭遇失败,随后公司进行了为期九个月的战略转型。通过观察客户实际工作流程,发现手动转录发票等重复性劳动,决定用AI智能体自动化这些任务而非强加新的聊天行为。公司建立了三大支柱框架:培养构建者文化、高速迭代替代官僚主义、构建GenOS平台引擎。最终推出的QuickBooks支付智能体让小企业平均提前5天收到款项,每月节省12小时工作时间。

首次实现真正意义上的“图像记忆“:希伯来大学突破3D生成技术瓶颈
希伯来大学研究团队开发出MV-RAG系统,首次解决了AI在生成稀有物品3D模型时的"胡编乱造"问题。该系统像拥有图像记忆库的艺术家,能先搜索相关真实照片再生成准确3D视图。通过独创的混合训练策略和智能自适应机制,MV-RAG在处理罕见概念时性能显著超越现有方法,为游戏开发、影视制作、虚拟现实等领域提供了强大工具。

马斯克的Grok推出新编程模型,主打高速开发
马斯克旗下xAI公司发布专为开发者设计的新AI模型grok-code-fast-1,主打快速且经济的推理能力。该模型属于Grok 4系列,具备自主处理任务的能力。xAI声称其在SWE-bench评测中解决了70.8%的实际软件问题,表现优于GPT-5和Claude 4。不过模型存在较高的不诚实率问题。用户可通过GitHub Copilot等平台免费试用7天,需要API密钥访问。

AI挑战多步推理的秘密:MBZUAI团队揭示大模型“思考深度“的突破之路
MBZUAI等机构研究团队通过一维细胞自动机实验揭示了AI模型多步推理的关键限制:固定深度模型在单步预测上表现优异,但多步推理能力急剧下降。研究发现增加模型深度比宽度更有效,自适应计算时间、强化学习和思维链训练能突破这些限制。这为开发更强推理能力的AI系统提供了重要指导,强调了真正推理与简单记忆的本质区别。
2025
07/18
14:21
分享
点赞

抖音升级AI内容标识功能,协助创作者打标、支持元数据读写
从攻防实战到AI赋能,微步在线的十年安全沉淀
Intuit如何从聊天机器人失败走向企业智能体成功
马斯克的Grok推出新编程模型,主打高速开发
跳过无聊部分:Google Photos AI自动高亮视频精彩瞬间
AI能读取思维——脑机接口技术实现74%准确率解码内心语言
GSI如何在企业AI竞赛中脱颖而出
沃尔玛智能体AI战略升级:Element平台与开发者"超级智能体"Wibey亮相
英伟达财报后加速推进机器人与自动化布局
软件占据网络安全预算40%,生成式AI攻击速度达毫秒级
Sakana AI推出M2N2算法,无需昂贵重训练即可构建强大AI模型
量子技术即将迎来关键拐点
