
同时处理500个任务的AI会崩成什么样?Distyl AI测试了20个主流模型 原创

你是否还记得2020年春晚,有个小品叫《机场姐妹花》。黄晓明扮演的乘客向金靖扮演的机场地勤,提出一个长到离谱的要求(共198个字),但被金靖一字不差的重复出来:
“一套煎饼不放葱,一套煎饼只放葱…所有黑豆豆浆都要小杯的,所有加冰的都要中杯的”
是不是有点像我们使用豆包、Kimi、ChatGPT这些AI助手的时候,都要写提示词告诉它需求,想让它完整地执行出来。
简单的提示词一句话就够,比如“今天北京天气如何”
复杂的提示词可能要写成百上千字,来充分挖掘模型的性能。比如用LangGPT写出来的结构化提示词,或者是Manus的系统提示词、Claude的系统提示词等等。
那么AI助手或者说AI模型,能像金靖一样一字不差地完成超长提示词里的所有要求吗?
这正是Distyl AI公司的四位研究员想要解答的问题。
2025年7月15日,Distyl AI的研究人员,首次系统性地测试了当今最先进AI模型在面对大量指令时的真实表现能力,提出IFScale指令遵循评测基准,并将论文发表在Arxiv上。
AI系统正越来越多地被部署在复杂环境中,需要同时满足大量不同的规则和要求。然而,目前所有的AI性能测试的研究都只关注单一或少数几个任务。
为了填补这个研究空白,团队开发了一个名为"IFScale"的全新测试基准。这个测试的核心任务很简单:让AI写一份专业的商业报告,但同时必须在报告中准确包含指定的关键词。关键词数量从10个一直增加到500个,每增加10个就测试一次。这就像要求一个记者写新闻稿,但必须自然地融入越来越多的特定词汇,既要保持文章的流畅性,又不能遗漏任何一个要求的词汇。
研究团队测试了来自七大主要AI公司的20个最先进模型,包括我们熟悉的GPT-4、Claude、Gemini等。测试过程极其严格:每个难度级别都进行5次独立测试,确保结果的可靠性。指令遵循完整排名可以在文末项目地址中查看:
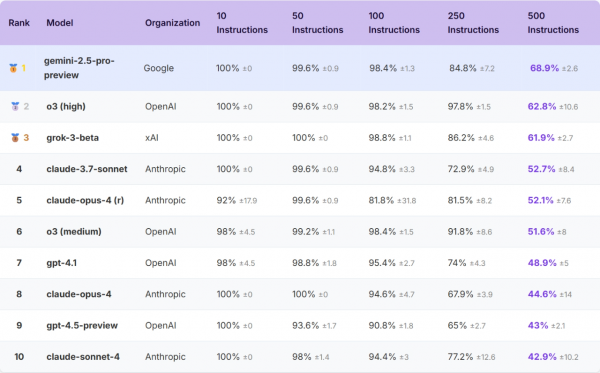
AI的极限比我们想象的要低得多
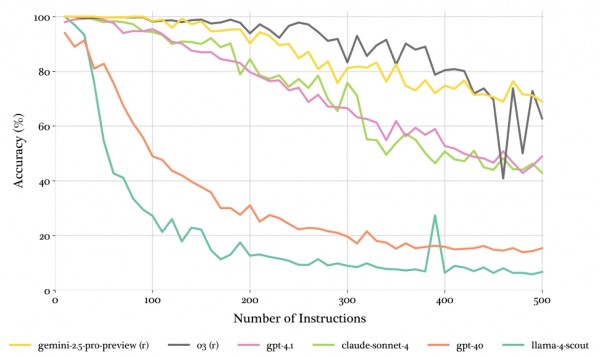
测试结果显示,即使是表现最好的前沿AI模型,在面对500个指令时的准确率也只有68%。这意味着每三个要求中就有一个会被忽略或处理错误。更令人担忧的是,大多数模型的表现要糟糕得多。这就像一个看似能干的助手,当你只交给他一两件事时表现完美,但当任务清单变长时,他开始频繁出错、遗漏重要事项。
研究团队通过精心设计的评估方法发现了AI失败的两种主要方式。第一种是"遗漏错误",就是完全忘记处理某个要求,就像助手直接忽略了你交代的某件事。第二种是"修改错误",虽然记得要处理这件事,但处理得不够准确,比如你要求包含"责任"这个词,但AI写成了"负责任"。随着任务数量增加,AI越来越倾向于直接遗漏任务,而不是尝试不完美的处理。
特别值得注意的是,推理模型(比如OpenAI的o3、Google的Gemini-2.5-pro)表现明显更好。这些模型在处理问题时会进行更深入的思考,就像一个更仔细、更有条理的助手,会在行动前仔细检查任务清单。
三种截然不同的崩溃模式
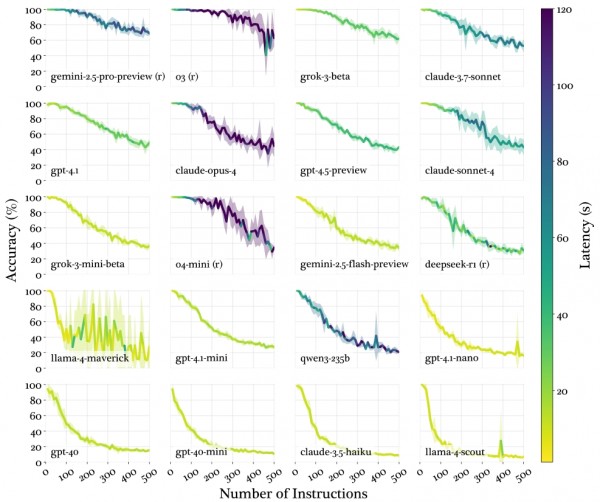
研究中最引人注目的发现是,不同的AI模型面对压力时表现出三种截然不同的"崩溃模式",就像不同性格的人在面临工作压力时的不同反应。
第一种是"阈值崩溃模式",主要出现在推理能力强的模型中。这些AI就像经验丰富的专业人士,在任务量适中时表现近乎完美,能同时处理150-250个不同要求而几乎不出错。但一旦超过他们的承受极限,性能就会急剧下降,表现变得不稳定。
第二种是"线性衰减模式",表现为随着任务增加,性能稳步下降。采用这种模式的AI就像普通的办公室职员,面对更多任务时逐渐力不从心,但衰减过程相对可预测。例如GPT-4.1和Claude-3.7-sonnet就展现了这种特征。
第三种是"指数崩溃模式",这类AI在面对稍多的任务时就迅速崩溃,但之后性能会稳定在一个很低的水平。这就像新入职的实习生,面对复杂任务很快就不知所措,但至少还能完成一些基础工作。有趣的是,这些快速崩溃的模型最终都稳定在大约7-15%的准确率,暗示这可能是AI处理复杂指令时的某种生存模式。
AI有明显的"偏心"问题

研究揭示了一个有趣的现象:几乎所有AI都存在"首因偏差",就像人类更容易记住清单开头的事项一样。当给AI一个长长的任务清单时,它们处理排在前面的指令时更加仔细准确,而对后面的指令则容易忽视或处理错误。
这种偏差在中等任务量(150-200个指令)时最为明显,就像一个助手在工作量刚开始让他感到压力时,会优先保证重要的事情不出错,而对不太紧急的事项敷衍了事。但当任务量达到极限时,这种偏差反而会减弱,因为此时AI已经完全不堪重负,处理所有指令都变得困难。
这个发现对实际应用有重要启示:如果你需要AI同时处理多个任务,把最重要的要求放在清单开头确实更保险。但当任务过于繁重时,这种策略的效果就会大打折扣。
速度与准确性的两难抉择
针对20个大语言模型,研究团队测试并统计了指令遵循行为的五个关键维度数据:1.准确度层次;2.具有中等难度区域的方差模式;3.显示系统性转向指令放弃的遗漏修改错误率;4.表明普遍注意力下降模式的首因效应;5.延迟特征。
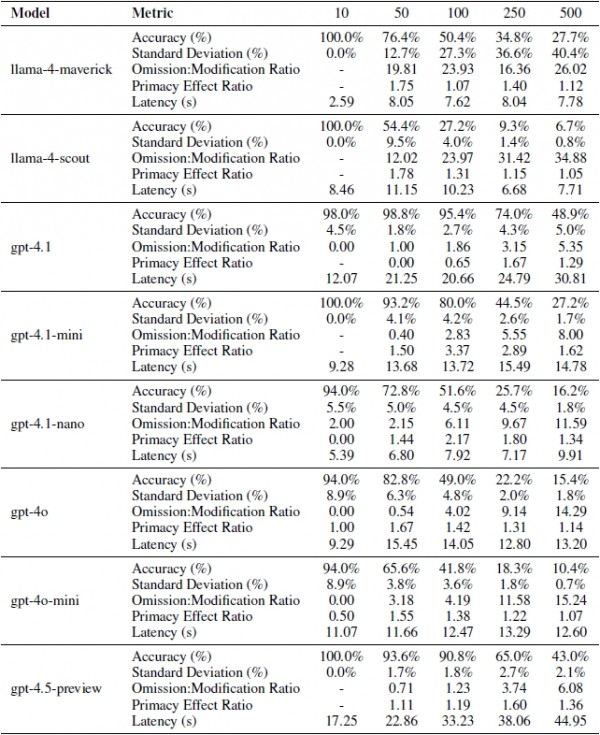
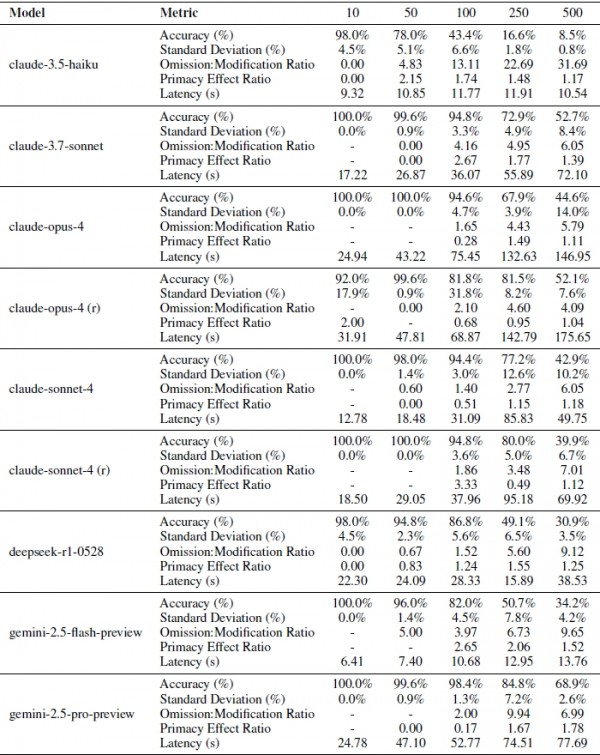
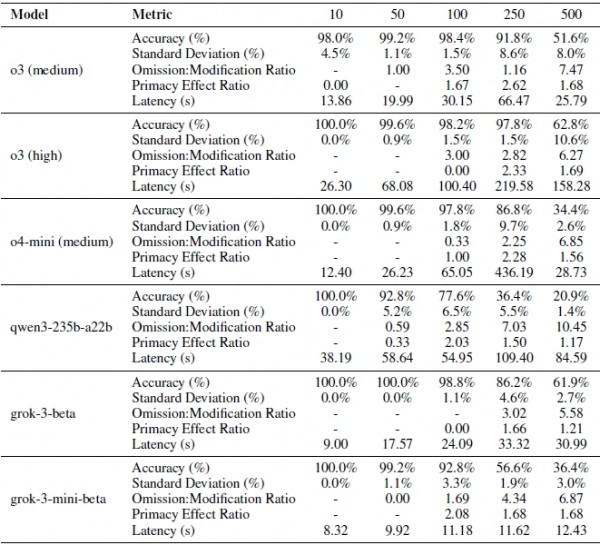
研究团队深入分析了AI的处理速度与准确性之间的关系。他们发现,推理模型虽然准确性更高,但处理速度明显更慢。以OpenAI的o3为例,处理10个指令只需26秒,但处理250个指令就需要近4分钟。相比之下,普通模型如Claude-3.5-haiku始终保持在10秒左右的稳定速度。
这就像精工细作的手工艺人与流水线工人的区别。手工艺人制作的产品质量更高,但速度较慢;流水线工人虽然速度快,但面对复杂任务时容易出错。对于需要实时响应的应用场景,比如客服聊天机器人,可能需要在准确性和响应速度之间做出权衡。
意外的发现和例外情况
研究中还出现了一些令人意外的结果。例如,Grok-3模型虽然没有使用复杂的推理模式,但表现却接近顶级推理模型,在500个指令的测试中达到了61.9%的准确率,且表现稳定。
另一个意外是,一些理论上应该表现更好的新模型反而不如预期。比如Qwen3这样的大型新一代模型只达到了26.9%的准确率,而某些较老的模型表现反而更好。看来,AI的能力并不总是随着模型规模或新旧程度简单递增。
对质量的潜在影响
研究团队还关注了一个重要问题:当AI忙于处理大量指令时,核心任务的质量是否会受到影响?他们发现,大多数模型在应对更多指令时,商业报告的整体质量并没有明显下降。但OpenAI的o系列模型是个例外,随着指令增加,生成的报告质量确实有所下降。
这个现象的部分原因可能是o系列模型生成的文本较短。当需要在有限的文字中包含大量关键词时,文章的自然流畅度就会受到影响,就像在一篇短文中硬塞太多信息点会让文章显得生硬拗口。
至顶AI实验室洞见
研究结果表明,当前的AI技术还无法完全胜任同时处理数百个复杂要求的工作。在这些场景中,可能需要采用分层处理的策略:先用AI处理相对简单的任务,再让人工专家负责最关键的部分。或者将复杂任务分解为多个较简单的子任务,分别交给不同的AI系统处理。
说到底,这项研究揭示了当前AI技术的一个根本局限:尽管它们在单一任务上可能表现出色,但在需要同时兼顾多个要求的复杂现实场景中,仍然存在显著的能力缺陷。
对于企业和开发者来说,这项研究提醒我们需要更加重视AI系统在复杂环境中的压力测试,而不只是关注理想条件下的性能表现。
这项研究为我们理解AI的真实能力边界提供了宝贵洞察。随着AI技术的不断发展,相信未来会有更多研究致力于提高AI在复杂多任务环境中的表现能力。
项目地址:
https://distylai.github.io/IFScale/
论文地址:
https://www.arxiv.org/abs/2507.11538
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q1: IFScale基准测试如何评估大型语言模型的指令跟随能力?
A: IFScale基准测试使用一个商业报告写作任务,包含500个关键词包含指令(如"Include the exact word {keyword}")。指令密度从10步进增加到500,自动评估模型通过正则表达式匹配关键词是否包含在报告中。该基准测量指令密度增加时的性能下降,开源在
https://distylai.github.io/IFScale。
Q2: 大型语言模型在500个指令下的最高准确率是多少?
A: 在IFScale测试中,500指令下最佳模型的准确率为68%。gemini-2.5-pro模型达到68.9%,o3模型达到62.8%。其他模型如gpt-4o准确率降至15.4%,llama-4-scout只有6.7%。性能下降显著,模型大小和推理能力影响结果。
Q3: 大型语言模型在高指令密度下有哪些性能下降模式?
A: 性能下降分三种模式:阈值衰减(推理模型如gemini-2.5-pro保持高准确率直到临界点),线性衰减(gpt-4.1稳定下降),指数衰减(llama-4-scout快速跌至低基线)。所有模型在极端密度下收敛到均匀失败。
来源:至顶AI实验室
好文章,需要你的鼓励


英特尔复苏进行中,代工业务成为关注焦点
英特尔第三季度财报超华尔街预期,净收入达41亿美元。公司通过裁员等成本削减措施及软银、英伟达和美国政府的大额投资实现复苏。第三季度资产负债表增加200亿美元,营收增长至137亿美元。尽管财务表现强劲,但代工业务的未来发展策略仍不明朗,该业务一直表现不佳且面临政府投资条件限制。

认知科学研究院首次发现:进化策略竟能超越强化学习训练大语言模型
美国认知科学研究院团队首次成功将进化策略扩展到数十亿参数的大语言模型微调,在多项测试中全面超越传统强化学习方法。该技术仅需20%的训练样本就能达到同等效果,且表现更稳定,为AI训练开辟了全新路径。

微软为Copilot推出Mico虚拟角色及新增自动化协作功能
微软发布新版Copilot人工智能助手,支持最多32人同时参与聊天会话的Groups功能,并新增连接器可访问OneDrive、Outlook、Gmail等多项服务。助手记忆功能得到增强,可保存用户信息供未来使用。界面新增名为Mico的AI角色,并提供"真实对话"模式生成更机智回应。医疗研究功能也得到改进,可基于哈佛健康等可靠来源提供答案。同时推出内置于Edge浏览器的Copilot Actions功能,可自动执行退订邮件、预订餐厅等任务。

当机器学会“热眼看世界“:纽约大学等联合团队让AI精通“热感翻译术“
纽约大学等机构联合开发的ThermalGen系统能够将普通彩色照片智能转换为对应的热成像图片,解决了热成像数据稀缺昂贵的难题。该系统采用创新的流匹配生成模型和风格解耦机制,能适应从卫星到地面的多种拍摄场景,在各类测试中表现优异。研究团队还贡献了三个大规模新数据集,并计划开源全部技术资源,为搜救、建筑检测、自动驾驶等领域提供强有力的技术支撑。
2025
07/21
17:07
分享
点赞

Unity中国携手腾讯广告,让中小开发者告别“碰运气”
Unity团结引擎发布三大战略 极速提升渲染效能
Unity开发者大会Unite2025点亮上海,团结引擎加速本土创新落地
阿里夸克“C计划”再曝新动向:一款AI浏览器或年底发布
英特尔复苏进行中,代工业务成为关注焦点
微软为Copilot推出Mico虚拟角色及新增自动化协作功能
Google与Anthropic签署百亿TPU合作协议推进AI发展
EA与Stable Diffusion背后公司合作,用AI制作游戏
英特尔称服务器CPU将重新火热:AI工作负载推动增长
提示工程正在深入探索最新发布的ChatGPT工作效率提升提示包
NRG能源如何通过技术创新重塑传统电力行业
CIO将承担业务主导AI项目失败的收拾责任
