
北大团队揭秘AI大脑的"纠结症":当视觉和文字打架时,多模态模型如何做选择 原创
说起人工智能看图识字这件事,你可能以为它总能准确无误地理解我们给它的图片和文字。但实际情况远比这复杂。设想一下这样的场景:你给AI展示了一张红色正方形的图片,同时配上一段文字说"这个正方形是蓝色的"。此时AI该相信谁?是相信自己的"眼睛"还是相信文字的描述?
这个看似简单的问题,实际上牵涉到当前多模态大语言模型面临的核心挑战。来自北京大学、南华工业大学、清华大学、乔治亚大学、阿卜杜拉国王科技大学以及MBZUAI的研究团队,在2025年11月发表的一项研究中,对这个问题进行了深入探讨。
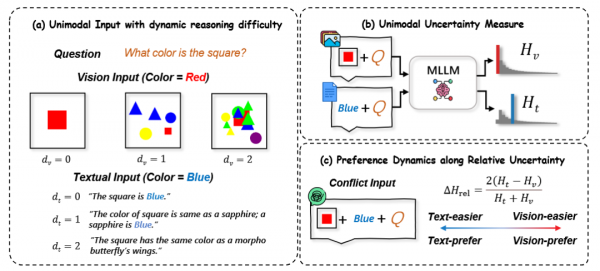
这项研究最引人注目的地方在于,它第一次系统性地将AI处理冲突信息的行为,拆解成了两个可以量化的核心要素。第一个要素是"相对推理不确定性",说白了就是AI对两种信息来源分别有多大把握。第二个要素是"内在模态偏好",也就是在条件相似时,AI天生更倾向于相信图像还是文字。过去的研究往往只关注最终的统计数据,比如统计AI有多少次选择了文字描述,有多少次选择了图像信息。但这种粗略的统计方式,就像只看考试的平均分,却忽略了每道题的难易程度对学生答题的影响一样。
AI的选择困境:当眼见与耳闻不一致
在日常生活中,我们经常遇到眼睛看到的和耳朵听到的信息不一致的情况。比如朋友告诉你"那辆车是红色的",但你明明看到的是一辆蓝色的车。这时候,你会相信自己的眼睛还是朋友的话?对于今天的多模态AI系统来说,这种矛盾信息的处理同样是一个巨大挑战。
多模态大语言模型(简称MLLMs)就像一位同时具备视觉和听觉的智能助手,它能够同时处理图像和文本信息。这种能力让它在网页导航、辅助视障人士等应用中发挥着重要作用。然而,当图像显示的是蓝色汽车,而配文描述却说是红色时,AI必须做出选择——这种行为被研究者称为"模态跟随"。这就像一位侦探面对两份相互矛盾的证词,必须决定相信哪一方。
以往的研究通常只是统计AI在大量案例中选择相信图像还是文本的比例,这种粗糙的方法就像只看侦探的破案率,却忽略了每个案子的具体难度。北京大学团队认为,这种方法忽视了一个关键因素:AI对每个单独预测的信心程度。同样是给出正确答案,有的模型可能非常确定,而另一个模型可能只是勉强猜对。即使是同一个模型,面对不同的问题,其确定程度也会有天壤之别。这种潜在的信心差异直接影响着模型在面对矛盾时的最终选择。
破解谜团的新思路:双重因素理论
研究团队提出了一个革命性的观点:AI的模态跟随行为实际上是一个动态过程,受两个核心因素共同支配。第一个因素是"相对推理不确定性",这反映了AI在处理纯文本和纯图像时的信心差距。第二个因素是"固有模态偏好",指的是当两种模态的推理难度相当时,AI天生的倾向性。
打个比方,这就像一位侦探在破案时会综合考虑两个方面。首先是证据的可靠程度——指纹证据可能比目击证词更可靠。其次是侦探个人的办案习惯——有的侦探更相信物证,有的则更看重人证。当文本信息的推理优势(也就是其相对不确定性较低)足够大,能够克服模型对视觉信息的潜在偏好时,AI才会选择相信文本。
为了验证这个假设,研究团队精心设计了一套可控的实验数据集。他们能够独立地调节视觉和文本输入的推理难度,从而在不同的不确定性水平下观察AI的行为。在颜色识别任务中,视觉难度通过添加干扰物、缩小目标物体或引入遮挡来控制。比如,低难度的图像可能只有一个清晰的红色方块,而高难度的图像则可能在众多彩色形状中包含一个被部分遮挡的小方块。文本难度则通过推理复杂度来调节——从直接陈述"方块是蓝色的",到需要多步推理的"方块的颜色和蝴蝶翅膀相同"。
研究团队使用输出熵来量化模型的感知不确定性。熵就像温度计一样,能够精确测量AI的"犹豫程度"。低熵值表示AI非常确定自己的答案,就像侦探掌握了确凿证据;高熵值则表示AI在多个可能答案之间摇摆不定,仿佛侦探面对模棱两可的线索。
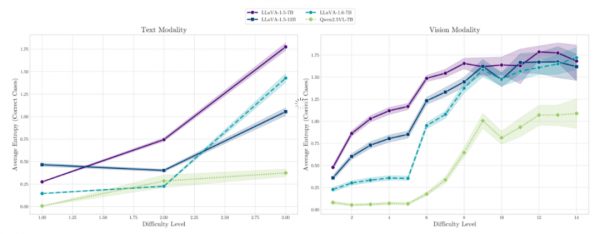
突破性发现:单调递减的普适规律
研究的第一个重大发现令人惊叹。通过对六个不同的多模态模型进行测试,包括LLaVA系列和Qwen-VL系列,研究团队发现了一个普遍规律:随着某一模态的相对不确定性增加,模型跟随该模态的概率呈现出平滑的单调递减趋势。换句话说,当文本变得相对于图像更难理解时,AI选择相信文本的可能性会稳定且可预测地降低。
这个发现就像发现了一条物理定律。无论是哪种架构或规模的模型,都遵循着这个基本规律。这直接证实了研究团队的核心假设:模态跟随不是一个固定的特征,而是一个受相对推理不确定性支配的动态行为。
更有趣的是"平衡点"的发现。虽然所有模型都遵循单调递减规律,但它们的曲线在坐标轴上的位置各不相同。研究团队将模型同等可能跟随任一模态(50%的概率)时对应的相对不确定性值定义为"平衡点"。这个平衡点提供了一种原则性的、定量的方法来衡量模型的固有偏好。平衡点在零以下表示固有的视觉偏好(因为文本必须显著更容易才能被同等对待),而平衡点在零以上则表示固有的文本偏好。
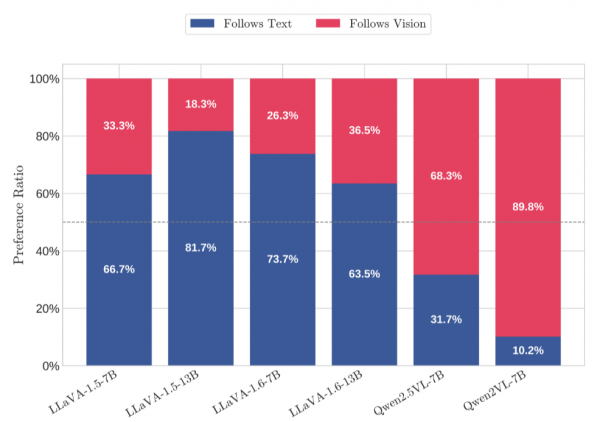
这个框架成功解释了之前看似矛盾的现象。比如Qwen2-VL看起来比Qwen2.5-VL更倾向于跟随视觉,但深入分析发现,这主要是因为Qwen2-VL在特定数据集上的视觉能力更强,导致更多数据点落在"视觉更容易"的区域。而Qwen2.5-VL实际上具有更强的固有视觉偏好,因为即使在文本明显更容易的情况下,它仍然倾向于相信视觉信息。
内部机制揭秘:模型的"思想斗争"
研究的第二个重大贡献是揭示了AI内部的决策机制。为什么当相对不确定性接近平衡点时,模型会表现出犹豫和平均化的行为?研究团队通过逐层分析模型的推理过程,发现了"振荡"这一内部机制。
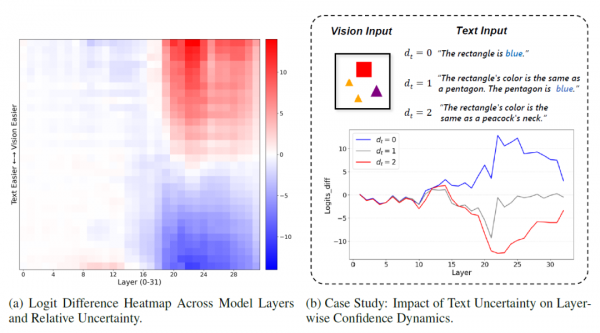
研究者将冲突场景分为两类区域。在"清晰区域",一个模态显著比另一个容易理解,模型会在早期处理层就快速且稳定地选定更容易的模态。这就像侦探面对一份清晰的指纹证据和一份模糊的目击证词,会毫不犹豫地选择相信指纹。相反,在"模糊区域",两个模态的不确定性水平相近,接近模型的平衡点,此时模型会表现出犹豫。这种犹豫在内部表现为"振荡"——模型的预测在文本支持的答案和视觉支持的答案之间反复切换。
通过可视化技术,研究团队展示了这种内部斗争的过程。在清晰区域,对数差异(文本答案的置信度减去视觉答案的置信度)会迅速偏向某一方并保持稳定。而在模糊区域,这个差异会在零附近徘徊,反映出模型的内部不确定性。这种数值上的犹豫正是振荡的直接原因。
一个具体的案例研究生动地展示了这一发现。研究者将同一张图片与三个不同推理难度的文本配对。简单文本让模型快速稳定地选择了文本;困难文本让模型果断地选择了视觉;而中等难度的文本则让模型陷入了内部的"思想斗争",其轨迹在决策边界附近徘徊,完美诠释了可控输入难度如何塑造相对不确定性,进而决定模型的内部状态和最终选择。
研究的深远意义
这项研究不仅在理论上取得了突破,更为实际应用提供了重要指导。通过理解AI如何处理矛盾信息,我们可以设计更可靠的多模态系统。比如在自动驾驶场景中,当摄像头捕捉的图像与地图文本信息冲突时,系统可以根据各自的不确定性水平做出更明智的决策。
研究还揭示了传统评估方法的局限性。简单的文本跟随率或视觉跟随率等宏观指标具有误导性,因为它们混淆了两个不同的因素:模型的能力和其固有偏好。新框架成功地将这两者分离,为更准确地评估和改进多模态AI系统提供了理论基础。
更重要的是,这项研究为理解AI的"思维过程"提供了新视角。通过观察模型内部的振荡行为,我们能够直观地看到AI在面临困难决策时的"纠结"过程。这种理解不仅有助于改进现有系统,还为开发更透明、更可解释的AI系统指明了方向。
研究团队的工作还具有很强的普适性。他们在多个数据集和任务上验证了发现的规律,包括颜色识别、物体识别、属性识别和位置推理等任务,都观察到了相同的单调模式。这证明相对不确定性与模态跟随之间的关系是一个稳健而普遍的原则。
随着多模态AI系统在各个领域的广泛应用,理解它们如何处理冲突信息变得越来越重要。这项研究提供的框架和见解,将帮助我们构建更智能、更可靠的AI系统,让它们在面对复杂、矛盾的真实世界信息时,能够做出更好的判断和决策。
来源:至顶AI实验室
好文章,需要你的鼓励


谷歌地图接入Gemini AI 打造全知智能助手
谷歌地图将集成Gemini人工智能技术,旨在将其升级为一个"全知型副驾驶"助手。这一整合将大幅提升地图服务的智能化水平,为用户提供更加个性化和全面的导航体验。通过AI技术的加持,谷歌地图有望在路线规划、地点推荐和实时信息服务等方面实现重大突破。

当AI遇到散点图:Feedzai团队首次揭秘机器如何“读懂“数据可视化
Feedzai团队首次系统评估了AI模型理解散点图的能力,创建了包含18,000张图表的大规模数据集。测试十个先进AI模型发现,在简单计数任务中部分模型准确率超90%,但精确定位任务表现不佳,准确率多在50%以下。研究还发现图表设计对AI性能有轻微影响,为AI辅助数据分析提供了重要参考。

微软构建虚假市场测试AI智能体,结果暴露意外缺陷
微软研究人员发布新的仿真环境来测试AI智能体,研究显示当前智能体模型容易受到操纵。该名为"Magentic Marketplace"的合成平台让客户智能体与商家智能体进行交互实验。测试包括GPT-4o、GPT-5和Gemini-2.5-Flash等模型,发现智能体在面临过多选择时效率下降,且在协作方面表现不佳。研究揭示了AI智能体在无监督环境下的性能问题。

机器人也能“货比三家“:KAIST团队让视觉语言机器人学会在关键时刻做出最精准选择
KAIST研究团队开发出MG-Select系统,首次让视觉语言机器人具备"货比三家"的决策能力。该系统通过生成多个行动候选方案并利用内部评估机制选择最优解,无需额外外部验证系统。在真实世界测试中,机器人精确操作成功率提升28%-35%,某些任务改进达168%,为机器人在医疗、制造等高精度应用领域的发展奠定重要基础。
2025
11/06
10:41
分享
点赞

谷歌地图接入Gemini AI 打造全知智能助手
微软构建虚假市场测试AI智能体,结果暴露意外缺陷
数据中心安全检查清单:5大核心类别消除运营风险
微软商店推出16款应用同时安装新功能
Perplexity展示如何在老旧GPU和AWS网络上高效运行大型AI模型
企业AI应用的四个关键策略:从随机试验到深度整合
Stream Ring:这枚智能戒指能悄悄记录你的想法
Alphabet正转变策略:将"登月项目"作为独立公司推向市场
企业构建可信赖AI为何如此关键
软件定义车辆的网络安全:实现安全出行五项措施
北大团队揭秘AI大脑的"纠结症":当视觉和文字打架时,多模态模型如何做选择
企业AI就绪安全网络架构,你跟上了吗?
