
腾讯发布"读图神器"HunyuanOCR,只用1%的参数就打败了行业巨头? 原创
2025年11月24日,腾讯混元视觉团队在arXiv上发布了一篇技术报告,介绍了最新开源的HunyuanOCR模型。这个仅有10亿参数的小模型,在多项测试中竟然击败了参数量是它几十倍甚至上百倍的大模型。
HunyuanOCR用巧妙的设计和精心的训练方法,证明了"小而美"的力量。这篇文章将带你深入了解这位OCR界的"小钢炮"是如何炼成的。
什么是OCR
在正式介绍HunyuanOCR之前,我们先来聊聊OCR到底是什么。OCR的全称是"光学字符识别",简单来说,就是让电脑能够"看懂"图片中的文字。你可能已经在日常生活中不知不觉地使用过OCR技术了:用手机扫描名片、拍照翻译外文菜单、把纸质文件转换成可编辑的电子文档,这些功能背后都有OCR在默默工作。
想象你面前有一堆图片需要分析。传统的方式是你得一张张看,一个字一个字地抄写下来。而OCR就像是给你配备了一位超级助手,它能瞬间"看"完所有图片,并把里面的文字都整理出来。更厉害的是,现代OCR不仅能认字,还能理解文档的结构,哪里是标题、哪里是表格、哪里是公式,就像这位助手不仅能抄写,还能帮你整理成条理清晰的笔记。
随着人工智能的快速发展,OCR的应用场景已经远远超出了简单的文字识别。在办公和教育领域,OCR能帮助翻译文献、提供学科辅导。在医疗健康领域,OCR可以将医疗记录数字化存档,帮助分析病历,为患者提供更好的治疗建议。更重要的是,OCR系统正在成为训练大型语言模型的重要工具,那些专业书籍和历史档案中蕴含的知识,正是通过OCR技术被"解锁"并用于训练AI的。
传统OCR的困境:流水线上的烦恼
在HunyuanOCR出现之前,业界主流的OCR解决方案大多采用"流水线"式的架构。这就像一家工厂的生产线,每个工位负责一道工序:第一个工位负责检测文字在哪里,第二个工位负责识别检测到的文字内容,第三个工位负责分析文档的布局结构,第四个工位负责识别其中的公式和表格,如果还需要翻译,那就再加一个工位。
这种流水线式的设计确实有它的优点:模块化程度高,每个环节都可以单独优化和更换。但问题也随之而来。首先是"踢皮球效应",如果第一个工位(文字检测)出了错,比如漏掉了一行字,那这个错误就会一路传递下去,后面的工位再厉害也无法弥补。这就像接力赛跑,第一棒选手掉了棒,后面的队友跑得再快也追不回来了。
其次是维护成本高昂,想象你要维护一条有五六个工位的生产线,每个工位都需要专业人员调试,工位之间的衔接也需要协调。一个完整的文档解析系统,可能需要整合高精度的文字检测模块、多语言文字识别引擎、精细的布局分析组件、专业的数学公式识别模块,以及结构化的表格识别单元。这种模块堆叠的设计不仅增加了部署的复杂性,还需要专业人员对各个组件进行协调调优。
近年来,随着视觉语言模型的进步,一些专门用于OCR和文档解析的开源模型相继问世,比如MonkeyOCR、Dots.OCR、MinerU2.5和PaddleOCR-VL等。这些努力试图通过大规模建模来提高解析精度。然而,由于当前开源模型在处理复杂布局和长文本序列时的鲁棒性有限,许多模型仍然依赖于前置的布局分析模块来检测文档元素,然后由视觉语言模型在局部区域内解析内容。虽然这种混合设计在一定程度上提高了可用性,但它尚未充分发挥视觉语言模型在端到端联合推理和统一多任务建模方面的潜力。
HunyuanOCR的秘密武器:一步到位的端到端设计
HunyuanOCR采用了一种完全不同的思路:把整条流水线变成一个"全能选手"。这位全能选手不需要在不同工位之间传递接力棒,而是一个人就能完成所有工序。用专业术语来说,这叫做"端到端"架构。
用一个比喻来理解这个概念,传统的流水线OCR就像是在餐厅点餐时,你的订单要经过前台、厨房主管、配菜师、大厨、装盘师等多个环节,任何一个环节出错,你的菜都可能不对味。而HunyuanOCR就像是一位全能的私人厨师,从听你说想吃什么,到采购、备菜、烹饪、装盘,全部一个人搞定,既高效又不容易出错。

HunyuanOCR的架构由三个核心模块组成,它们协同工作就像一支默契的三人乐队。第一位成员是"原生分辨率视觉编码器",基于SigLIP-v2-400M预训练模型构建,拥有大约4亿参数。这位成员的特长是"看",它能够处理任意分辨率的输入图像,通过自适应的分块机制保留原始宽高比。这意味着无论你给它一张又长又窄的文档截图,还是一张方方正正的证件照,它都能完整地"看"到所有细节,不会因为强行缩放而丢失信息。
第二位成员是"自适应MLP连接器",它是视觉和语言两个世界之间的桥梁。想象你有一位翻译官,能把图像世界的"语言"翻译成文字世界的"语言"。这位翻译官非常聪明,它会对视觉特征进行空间维度的自适应内容压缩,减少冗余信息,同时保留关键区域的重要语义信息,比如文字密集的区域。
第三位成员是"轻量级语言模型",基于混元0.5B模型构建。虽然只有5亿参数,但它内置了一项特殊技能,XD-RoPE位置编码。这项技术将传统的位置编码分解为四个独立的子空间:文本、高度、宽度和时间。这样的设计建立了一种原生的对齐机制,能够桥接一维文本序列、二维页面布局和三维时空信息,使模型能够处理复杂的布局解析和跨页文档分析。
这三位成员加起来,HunyuanOCR总共只有大约10亿参数,却能够在单次推理中完成整个工作流程。相比那些动辄上百亿参数的大模型,这就像是一辆小排量汽车跑出了超跑的速度,既省油又跑得快。
训练这位全能选手:从新手到高手的四个阶段
一位全能选手不是一天练成的,HunyuanOCR的训练过程分为四个精心设计的阶段。
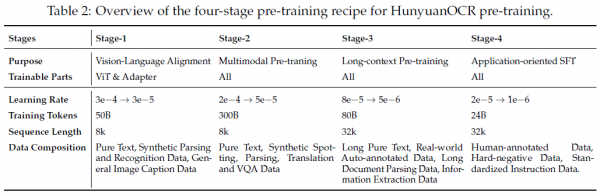
第一阶段可以叫做"热身期",主要任务是让视觉和语言两个模块学会"握手"。在这个阶段,研究团队只训练视觉编码器和MLP连接器,让它们学会如何将图像特征与文本语义对齐。训练数据主要是通用的图像描述数据和合成的OCR数据,同时保留少量纯文本数据以维持语言模型的基本能力。这个阶段使用了大约500亿个token进行训练。
第二阶段是"全面发展期",所有模型参数都被解锁,进行端到端的视觉语言联合学习。这个阶段的重点是增强模型对文档、表格、图表等结构化内容的深度理解和认知推理能力。训练数据混合了文本解析、定位、翻译和视觉问答等多种任务,使用了大约3000亿个token。
第三阶段是"长跑训练期",目标是将模型的上下文窗口扩展到32K个token。这就像是让运动员从短跑转向马拉松——不仅要跑得快,还要能跑得远。这个阶段使用了长文档解析任务和长篇纯文本数据,总计约800亿个token。
第四阶段是"精细打磨期",使用精心策划的人工标注真实数据进行退火训练。研究团队采用统一的指令模板和标准化的输出格式,确保不同任务之间响应模式的一致性。这个阶段使用了约240亿个token,为后续的强化学习奠定了坚实基础。
四个阶段加起来,HunyuanOCR使用了大约2亿个高质量样本进行训练,涵盖了九大真实场景:街景、文档、广告、手写文字、截图、卡证票据、游戏界面、视频帧和艺术字体,支持超过130种语言。
强化学习的魔法:让模型学会"自我反思"
如果说四阶段预训练是教会HunyuanOCR基本功,那么强化学习阶段就是让它学会"自我反思"和"精益求精"。这是HunyuanOCR的另一大创新,研究团队首次在业界证明,强化学习策略能够在OCR任务中带来显著的性能提升。
强化学习的核心思想可以用一个简单的比喻来理解:想象你在训练一只宠物狗。当它做对了动作,你就给它一块小饼干作为奖励;当它做错了,就不给奖励。久而久之,狗狗就学会了哪些行为会得到奖励,并倾向于做出正确的行为。
HunyuanOCR使用的是一种叫做GRPO的算法,全称是"群体相对策略优化"。在每次训练迭代中,模型会针对同一个输入生成多个不同的响应,然后根据奖励信号来调整策略,让好的响应更容易被生成。
但关键问题是:怎么判断一个响应是"好"还是"不好"呢?研究团队为不同的任务设计了不同的奖励机制。对于文字定位任务,奖励是基于预测框与真实框的重叠程度,以及识别文字与真实文字之间的编辑距离来计算的。这就像是判断你画的框有多准、认的字有多对。对于文档解析任务,奖励是基于输出内容与参考答案之间的编辑距离来计算的。对于视觉问答任务,奖励是二元的,答案语义匹配就给1分,不匹配就给0分。对于翻译任务,研究团队使用了一个评分模型来比较生成的翻译与参考翻译,给出0到5分的评分,然后归一化到0到1的区间。
为了确保训练的稳定性,研究团队还设置了一些约束条件。如果输出超过了最大长度限制,直接给0分;如果输出格式不符合要求,也直接给0分。这些约束帮助模型专注于学习准确的推理和格式化行为。
强化学习带来的效果是显著的。在文字定位任务中,模型在艺术字和屏幕截图等场景下的得分提升了2分以上。在文档解析任务中,OmniDocBench上的得分从92.5提升到了94.1。在信息提取任务中,准确率提升了约2分。在OCRBench上,平均得分提升了3.3分。这些数字背后,是模型在实际应用中更加可靠和准确的表现。
数据的艺术:好厨师需要好食材
在机器学习领域,有句话叫"垃圾进,垃圾出"。再好的模型架构,如果喂给它的数据质量不高,最终的效果也会大打折扣。HunyuanOCR的成功,很大程度上要归功于研究团队在数据构建方面下的功夫。
研究团队建立了一套完整的数据生产和清洗流水线,构建了一个包含超过2亿个图文对的语料库。这些数据来源多样:有公开的基准数据集,有通过网络爬虫收集的真实数据,还有使用自研工具生成的高质量合成样本。
合成数据的生成是一门艺术。研究团队基于SynthDog框架进行了扩展,能够生成支持130多种语言的段落级渲染数据,并且能够处理从左到右和从右到左两种文本方向,以及复杂的连笔书写风格。更重要的是,这套合成流水线支持对文本属性的精细控制,字体、颜色、方向都可以调整,还能模拟各种图像干扰,比如光照和阴影变化。
为了提高模型的鲁棒性,研究团队还开发了一套"扭曲合成流水线",专门用于模拟真实拍摄和自然场景中的图像缺陷。这套流水线可以模拟几何变形,比如折叠、弯曲和透视畸变;可以添加成像退化效果,比如运动模糊、高斯噪声和压缩伪影;还可以模拟光照变化,包括全局和局部的光照变化、阴影和反光。这些增强手段大大提升了模型在文字定位、文档解析和视觉问答等核心任务上的鲁棒性。
在问答对生成方面,研究团队开发了一套自动化流水线,能够将同一张图片的标注重复利用于多个任务。比如,一张带有文字定位标注的图片,可以自动生成相应的视觉问答数据。这种"一源多用"的策略大大提高了数据利用效率。
HunyuanOCR能做什么:五大核心能力全解析
说了这么多技术细节,HunyuanOCR到底能做什么呢?让我们来看看它的五大核心能力。
第一项能力是文字定位,这是OCR最基础的功能。HunyuanOCR能够精确定位和识别图片中的文字,输出行级别的文字内容和对应的坐标信息。为了确保输出格式的统一,研究团队设计了标准化的输出格式:用特定标签包裹识别出的文字内容,用另一组标签包裹文字区域的坐标信息。所有坐标都被归一化到0到1000的范围,以确保不同分辨率图片之间的一致性。
第二项能力是文档解析,这是OCR领域的核心能力,随着大语言模型的快速发展,其战略重要性日益凸显。HunyuanOCR提供了全面的文档解析方案,支持精细的元素级解析和完整的端到端文档解析。在元素级解析方面,它能够独立识别和提取数学公式、化学式、表格和图表等专门的文档元素,并将它们转换为相应的格式。公式转换为LaTeX,表格转换为HTML,流程图转换为Mermaid格式。在端到端文档解析方面,它能够对包含多种复杂元素类型的文档进行整体解析,按照阅读顺序输出所有文本内容,同时智能地将表格和公式转换为相应的格式。
第三项能力是信息提取和视觉问答。在信息提取方面,HunyuanOCR被设计用于开放世界中任意字段的提取,同时针对30多种常见文档类型进行了精确优化,包括身份证、银行卡、护照、营业执照、驾驶证、购物小票、出租车发票、火车票等。用户可以通过自然语言指令进行精细控制,支持单字段提取和多字段并行提取。此外,它还支持视频字幕提取,能够从标准视频截图中提取字幕内容。在视觉问答方面,HunyuanOCR展现了强大的开放域文档问答能力,能够处理裁剪的文本行、数学公式、文档、图表和街景图像等多种输入格式,并执行空间和属性理解、逻辑推理、数值计算等复杂任务。
第四项能力是文字图像翻译。HunyuanOCR内置了一个全面的端到端图像到文本翻译模块,支持14种以上的源语言,包括法语、德语、日语、韩语等,可以翻译成中文或英文。此外,系统还支持中英文之间的直接双向翻译。这个翻译模块不仅覆盖通用翻译场景,还能处理具有复杂布局的文档翻译任务。值得一提的是,HunyuanOCR在ICDAR 2025文档图像机器翻译竞赛的小模型赛道中获得了第一名,证明了其翻译能力的有效性。
性能表现:小模型的大能量
现在到了最激动人心的部分,HunyuanOCR的实际表现如何?让我们用一系列数据来说话。

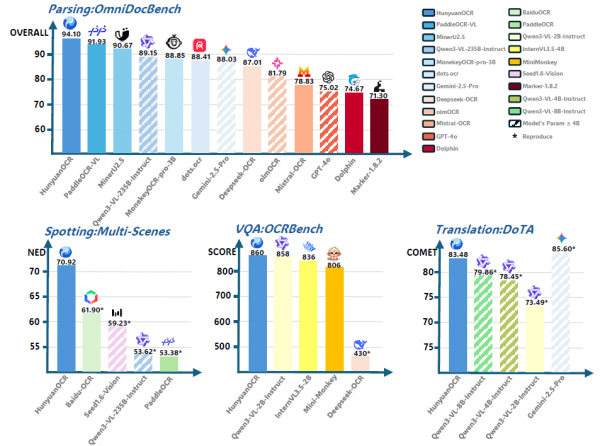
在文字定位任务上,研究团队构建了一个包含九个类别的基准测试集:艺术字、文档图像、游戏截图、手写文字、广告场景、卡证票据、屏幕截图、街景文字和视频帧,每个类别包含100张图片,总计900张。HunyuanOCR在这个测试集上取得了70.92分的综合成绩,大幅领先于传统的流水线方法和通用视觉语言模型。作为参考,PaddleOCR的得分是53.38分,百度OCR API的得分是61.90分,而参数量高达235B的Qwen3-VL-235B-A22B-Instruct也只得到了53.62分。
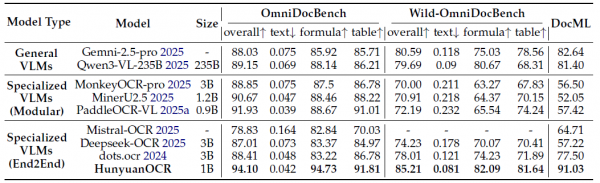
在文档解析任务上,HunyuanOCR在公开的OmniDocBench基准测试中取得了94.10分的综合成绩,超越了所有其他模型。在研究团队自建的Wild-OmniDocBench测试集上,这个测试集通过打印原始文档并在折叠、弯曲、不同光照等挑战性条件下重新拍摄,模拟真实世界中的文档拍摄场景,HunyuanOCR同样取得了最佳成绩85.21分。在多语言解析数据集DocML上,HunyuanOCR也展现了优秀的多语言解析能力,在全部14种语言上都取得了领先成绩。
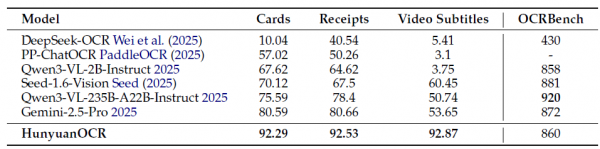
在信息提取和视觉问答任务上,HunyuanOCR在卡证信息提取任务上取得了92.29分,在票据信息提取任务上取得了92.53分,在视频字幕提取任务上取得了92.87分,全面超越了包括Qwen3-VL-235B-A22B-Instruct、Seed-1.6-Vision和Gemini-2.5-Pro在内的大型视觉语言模型。在OCRBench基准测试上,HunyuanOCR取得了860分,与参数量更大的Qwen3-VL-2B-Instruct相当,显著优于同等规模的DeepSeek-OCR。
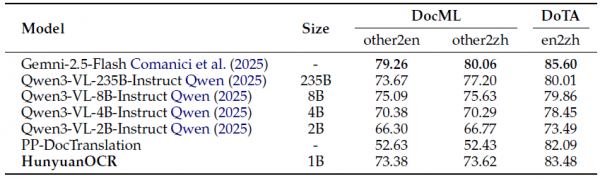
在文字图像翻译任务上,HunyuanOCR在DoTA基准测试的英译中任务上取得了83.48分的COMET得分,超越了参数量超过8B的多个模型。虽然由于语言模型规模相对较小,HunyuanOCR的翻译能力还不及其在文字检测、识别和文档解析方面的表现,但研究团队建议,对于需要更高翻译精度的应用场景,可以将其多语言解析模块与混元MT-7B翻译模型级联使用。
至顶AI实验室洞见
更好的OCR技术意味着更便捷的日常生活,比如,可以把一堆纸质文档拍照上传,系统能够完美保留原文档的格式和结构;把一张复杂的财务报表拍照,系统能够精确提取出每一个数字。这些场景正在因为OCR技术的进步而变得越来越现实。
而且HunyuanOCR是开源的,开发者和企业可以基于它构建自己的应用,而不必依赖昂贵的商业API。
HunyuanOCR证明,小模型也能取得优秀的表现,为边缘设备部署和移动端应用打开了大门。
不过HunyuanOCR目前还有局限性。由于语言模型规模相对较小,它在翻译质量上还有提升空间。研究团队表示,未来将继续通过token压缩和架构改进来优化推理效率,同时扩展模型处理更高分辨率和多页文档的能力。他们的长期目标是让HunyuanOCR适配边缘设备部署,进一步普及强大的OCR能力。
Q&A
Q1:HunyuanOCR的参数量只有1B,为什么能比235B的大模型表现更好?
A:HunyuanOCR的成功主要归功于三个因素:端到端的架构设计避免了传统流水线的错误传播问题;精心策划的高质量训练数据涵盖了130多种语言和九大真实场景;以及首创的强化学习策略为OCR任务提供了针对性的优化。
Q2:普通用户可以在哪里使用HunyuanOCR?
A:HunyuanOCR已经在HuggingFace上开源,开发者可以通过GitHub下载使用。研究团队还提供了基于vLLM的高性能部署方案,适合有技术背景的用户和企业进行二次开发和集成。
Q3:HunyuanOCR支持中文识别吗?
A:支持。HunyuanOCR是一个多语言模型,支持超过130种语言的识别和处理,中文是其重点优化的语言之一。无论是简体中文、繁体中文,还是中英混排的文档,它都能够有效处理。
来源:至顶AI实验室
好文章,需要你的鼓励


人工智能是否存在泡沫风险的深度分析
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。

UC伯克利大学发布革命性AI预算验证法:同样成本下数学解题准确率提升15.3%
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。

AI系统在压力下学会战略性欺骗的深层原因
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。

香港中文大学突破:让AI像真正的工程师一样设计机器
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。
2025
11/28
14:40
分享
点赞

AI系统在压力下学会战略性欺骗的深层原因
数据中心备份电力系统对比分析
Paxos以超1亿美元收购加密钱包初创公司Fordefi
腾讯发布"读图神器"HunyuanOCR,只用1%的参数就打败了行业巨头?
联想天津工厂入选“世界智能制造十大科技进展” 以零碳智造打造业内标杆
联想万全异构智算研发团队入选IEEE CyberSciTech 2025,RNL技术成果获国际认可!
首款搭载千问的AI硬件:夸克AI眼镜新品发布 次日门店现排队潮
ServiceNow或以超10亿美元收购网络安全初创公司Veza
谷歌云推出"PanyaThAI"计划加速泰国AI应用
英国产学合作推进光纤射频通信技术商业化进程
阿里巴巴推出可换电池设计的Quark AI智能眼镜
CIO影响力提升的关键:构建内部联盟
