
苹果发现:只需一个注意力层,就能让AI图像生成既快又好 原创
关于哪家大厂AI模型最强,似乎从无定论;但哪家大厂在AI掉队最明显,好像毫无争议。
同样经历过掉队,字节能迅速成立Seed团队追赶反超,苹果还有机会吗?库克卸任能否挽救苹果AI?
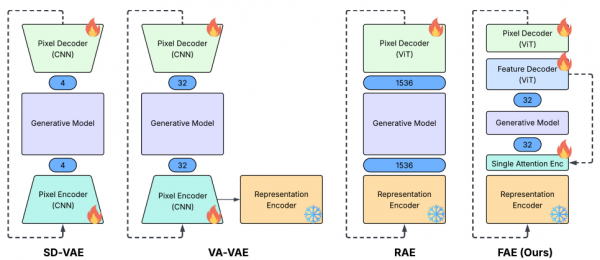
2025年12月,苹果公司的研究团队提出FAE,核心发现很简单:只需要一个"注意力层",就能让AI画家既学得快、又画得好。这个发现挺符合奥卡姆剃刀原则,有时候最简单的解决方案反而是最好的。
AI画家的两难困境:理解世界还是创造世界?
要理解这项研究的意义,我们得先搞清楚AI图像生成背后的一个根本矛盾。这个矛盾,就像是一个人既想当哲学家又想当画家一样。
想象你正在学习认识世界。为了理解一张照片里的内容,这是猫还是狗、是快乐还是悲伤,你的大脑需要提取出很多特征。这些特征就像是你对世界的理解笔记,越详细越好。比如说,当你看到一只猫的图片时,你的大脑会记录下"毛茸茸的、有胡须、眼睛是竖瞳"等等信息。在AI领域,这类专门理解图片的模型被称为视觉表征模型,比如著名的DINO和SigLIP。它们就像是AI界的哲学家,擅长深度理解图像的含义。
这些哲学家模型有一个特点:它们喜欢用很多维度来记录信息。打个比方,如果让你用三个词描述一只猫,你可能会说"可爱、毛茸茸、有胡须"。但如果给你1536个词的配额,你就能描述得更加精细,从毛发的光泽到瞳孔的形状,事无巨细。DINO-V2这样的顶级理解模型,就使用了1536个维度来描述图片信息。维度越高,理解就越细腻。
然而,当你想要创造而不只是理解时,情况就完全不同了。AI图像生成模型的工作方式,有点像是从一团乱麻中慢慢梳理出一幅画。最流行的扩散模型就是这样工作的:它从一张充满噪点的电视雪花图开始,一步一步地去除噪点,最终变成一张清晰的图像。这个过程就像是雕塑家从一块大理石中凿出雕像,不断去除多余的部分,直到作品显现。
问题来了:这种创造过程在低维度空间里工作得最好。为什么呢?想象你在一个漆黑的房间里寻找出口。如果房间是一条简单的走廊,你很容易摸索出去。但如果房间是一个有无数岔路的迷宫,找到出路就困难得多了。高维度空间就像这个复杂迷宫,让去噪过程变得不稳定、难以控制。通常,图像生成模型只使用4到64个维度,远少于理解模型的1536维。
这就是AI领域长期存在的"理解vs创造"困境:理解图像需要高维度的丰富信息,创造图像却需要低维度的简洁空间。这两者看似水火不容。
之前的尝试:各有各的烦恼
面对这个困境,科学家们之前尝试过两条路,但都不够理想。
第一条路是对齐策略。这就像是请两位翻译官,一位懂理解模型的语言,一位懂生成模型的语言,让他们不断沟通,直到双方能够互相理解。典型的方法包括REPA和VA-VAE。它们设计了复杂的"对齐损失函数",试图让理解模型和生成模型的特征对应起来。但问题在于,这种翻译过程难免会丢失信息,就像把一首优美的诗翻译成另一种语言,总会失去一些韵味。
第二条路是直接使用策略。既然翻译会丢失信息,那干脆不翻译了,直接用理解模型的高维特征来做生成。RAE就是这种思路的代表。但这样做的代价是什么呢?你需要把生成模型改造得更大、更复杂,才能处理那1536维的信息。这就像是为了运送一头大象,你不得不把所有的门都拆掉重建。模型变得又大又慢,而且只能配合特定的理解模型使用,换一个就得重新改造。
苹果的研究团队看到了这个僵局,开始思考一个更根本的问题:我们真的需要保留理解模型的全部高维信息吗?
灵光乍现:其实不需要那么复杂
这里有一个关键的洞察,也是这项研究最精彩的地方。
回想一下,为什么DINO这样的理解模型需要那么高的维度?因为它们在训练时使用了一种叫"掩码预测"的方法。简单说,就是把图片的一部分遮住,让模型猜测被遮住的内容。这就像玩拼图游戏,当你只看到拼图的一半时,被遮住的那一半可能有无数种可能性。为了记录所有这些可能性,模型需要很多维度。
但是,当我们把训练好的理解模型拿来用于图像生成时,情况完全不同了。我们给模型的是完整的图片,没有任何遮挡。这时候,那些用来记录"各种可能性"的高维度信息就变得多余了。这就好比你已经看到了完整的拼图,就不再需要猜测被遮住的部分是什么样子。
研究团队由此得出一个大胆的结论:在图像生成任务中,我们可以大胆地压缩理解模型的高维特征,而不会丢失真正有用的信息。那些被"压缩掉"的,主要是为了处理掩码任务而保留的冗余信息。
这个发现让一切变得简单起来。
FAE的诞生:一个注意力层的魔法
基于这个洞察,研究团队设计了FAE,特征自动编码器。它的结构简单得令人难以置信,核心就是一个注意力层加上一个线性投影。
让我们用一个厨房比喻来理解FAE的工作原理。
想象你是一位厨师,手边有一大堆顶级食材,这就是理解模型提供的1536维丰富特征。你的任务是把这些食材浓缩成一道精华汤底,方便后续烹饪使用。FAE的单注意力层编码器就像是一个神奇的榨汁机,它能够识别哪些食材是核心精华,哪些只是增加体积的水分。
为什么用注意力层而不是简单的线性压缩呢?因为注意力机制有一个独特的能力:它能够看到所有食材之间的关系,识别出哪些信息是冗余的。比如说,如果每一块土豆都携带着"这是一锅汤"的信息,那这个信息其实只需要记录一次就够了。注意力层正是能够发现并去除这种全局冗余信息的高手。
通过这个单层注意力机制,FAE把1536维的特征压缩到只有32维。这不是粗暴的丢弃,而是智慧的提炼。
双解码器设计:确保精华不流失
光有压缩还不够,我们还需要确保压缩过程没有丢掉重要信息。FAE的解决方案是使用双解码器设计,这是整个系统的另一个精妙之处。
回到厨房的比喻,你用榨汁机把食材浓缩成了精华汤底,但怎么知道这个汤底保留了所有重要的风味呢?FAE的做法是设置两道质检工序。
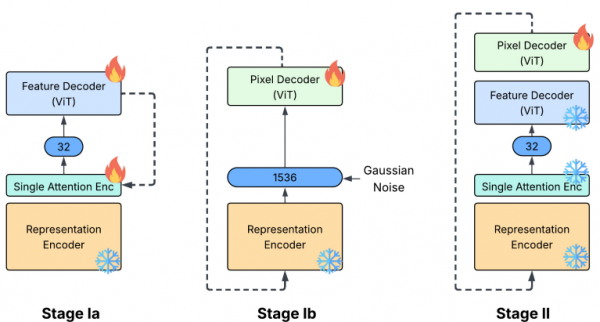
第一道工序是特征解码器。它的任务是从32维的压缩特征中,重建出原来1536维的完整特征。如果重建得很准确,就说明压缩过程确实保留了关键信息。这个特征解码器使用了6层Transformer结构,采用了一些现代深度学习的最佳实践,包括旋转位置编码、RMSNorm和SwiGLU激活函数。训练时使用标准的变分自编码器目标函数,既要求重建准确,又要求压缩后的特征分布规整。
第二道工序是像素解码器。它从重建的特征出发,生成最终的图像。这个解码器基于ViT-L架构,使用对抗损失、感知损失和重建损失的组合进行训练。有意思的是,像素解码器的训练分两个阶段:第一阶段在加了高斯噪声的原始DINO特征上训练,让解码器学会对噪声有一定的容忍度;第二阶段再微调到压缩后重建的特征上。
研究团队发现了一个令人惊喜的现象:即使不做第二阶段的微调,只用第一阶段训练的解码器,直接在压缩重建的特征上生成图像,效果也相当不错。这说明FAE的压缩确实非常保真,压缩后的特征与原始特征高度相似。
实验验证:数据说话
理论再漂亮,也得用实验来验证。研究团队在两个标准基准测试上检验了FAE的能力。
第一个测试是在ImageNet数据集上的类别条件图像生成。这是AI图像生成领域的高考,所有重要的方法都要在这里一较高下。评价指标是FID分数,分数越低,说明生成的图像质量越高、越逼真。
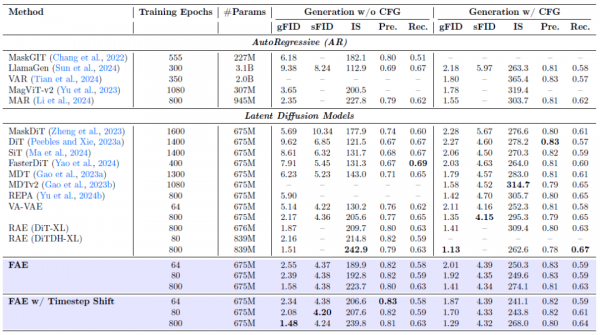
结果相当亮眼。在使用分类器引导的情况下,FAE在训练800个epoch后达到了1.29的FID分数,接近当时的最佳水平。更令人印象深刻的是它的学习速度:仅训练80个epoch,FAE就达到了1.70的FID分数。要知道,很多竞争方法需要训练几百甚至上千个epoch才能达到类似水平。在不使用分类器引导的情况下,FAE更是创下了1.48的最佳FID分数,展现出真正的实力。
第二个测试是文字生成图像任务。研究团队只用CC12M数据集进行训练,它比许多大模型使用的数据集小得多,然后在MS-COCO数据集上进行零样本测试。结果显示,FAE在使用分类器引导时达到6.90的FID分数,接近那些使用海量数据训练的大型模型的水平。
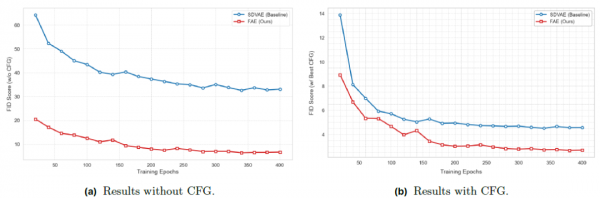
研究团队还展示了FAE的通用性,将它应用到了另一类完全不同的生成模型,归一化流模型STARFlow上。结果同样令人满意,FAE变体的FID分数达到2.67,远超使用标准VAE的4.51,而且收敛速度也快得多。
语义信息的保留:理解能力没丢失
FAE的一个独特优势是,它不仅适合图像生成,还保留了原始理解模型的语义理解能力。
为了验证这一点,研究团队做了两项额外测试。第一项是在ImageNet上的线性探测实验。这是测试特征质量的标准方法,如果特征保留了良好的语义信息,那么只用一个简单的线性分类器就能达到不错的分类准确率。结果显示,FAE的重建特征达到了86.17%的top-1准确率,与DINOv2-g/14模型的87.00%非常接近。考虑到FAE把维度压缩到了原来的2%,这个成绩相当出色。
第二项是在MS-COCO数据集上的图文检索任务。FAE在图像到文本和文本到图像两个方向上的检索准确率都与原始SigLIP2模型几乎相当,说明压缩后的特征依然保留了丰富的跨模态语义信息。

更直观的证据来自研究团队的可视化分析。他们展示了FAE特征的跨图像补丁匹配能力,不同图片中语义相似的区域(比如不同动物的头部、不同鸟类的翅膀)在FAE的特征空间中仍然能够准确匹配。这说明FAE不只是保留了粗略的全局信息,而是精确地保持了细粒度的、部件级别的语义关系。
消融实验:每个设计都有意义
研究团队还进行了一系列消融实验,验证FAE各个设计选择的合理性。
关于编码器结构,他们比较了单注意力层、纯线性层和6层Transformer这三种方案。结果发现,单注意力层在生成质量和理解能力上都表现最好。纯线性层虽然更简单,但因为它只能独立处理每个维度、无法识别补丁间的冗余信息,导致压缩效果和下游性能都稍逊一筹。而6层Transformer反而更差,这正好印证了研究团队的洞察:适配任务比原始的自监督预训练任务简单得多,过于复杂的编码器反而会"过拟合"于简单的重建任务,丢失掉原始特征中的宝贵信息。
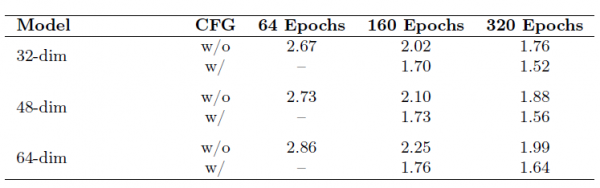
关于潜在维度,他们测试了32维、48维和64维三种设置。虽然64维的重建质量稍好,但32维在最终生成质量上反而最优,同时收敛速度也最快。这再次说明,对于生成任务来说,更低的维度确实更有利。
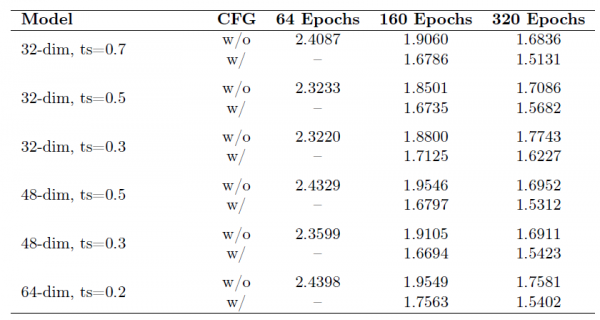
关于时间步偏移,研究团队发现这一技巧能够显著加速收敛,并缩小不同潜在维度之间的性能差距。加入时间步偏移后,FAE在仅64个epoch的训练后就能达到相当好的生成质量。
最后,关于生成模型本身的架构改进,他们逐步加入了SwiGLU、旋转位置编码和RMSNorm。每一个组件都带来了收敛速度和最终质量的改善,三者组合的效果最好。
至顶AI实验室洞见
苹果团队的关键洞察在于:他们没有被"如何保留高维信息"这个表面问题束缚住,而是追问了一个更根本的问题,我们真的需要那些高维信息吗?答案是,在图像生成这个具体任务中,并不需要。那些高维度主要是为了处理掩码预测任务,而生成任务用不到。这种减法思维让一切变得简单:一个注意力层就够了。
FAE的设计也展现了模块化的美感。它把复杂系统拆解成几个相对独立的模块:压缩编码器负责提炼,特征解码器负责质检重建,像素解码器负责最终输出。每个模块都有明确的职责,可以独立优化,也可以灵活替换。你可以用DINO的特征,也可以换成SigLIP的特征;你可以接扩散模型,也可以接归一化流模型。这种灵活性是复杂的端到端系统难以实现的。
研究团队坦诚地指出,由于编码器训练时没有直接优化图像重建损失,FAE的重建FID和图像保真度不如VA-VAE这类直接优化重建的方法。这是一个权衡:FAE选择了保留语义理解能力和生成效率,在重建精度上做了一些让步。
随着预训练视觉模型越来越强大,如何高效地将它们的能力迁移到各种下游任务,是一个日益重要的问题。FAE证明了,通过精心设计的轻量级适配器,我们可以在保留核心能力的同时,让预训练模型适应新的任务需求。这种即插即用的思路,可能会成为未来AI系统设计的一个重要方向。
Q&A
Q1:FAE是什么,它解决了什么问题?
A:FAE是苹果公司研究团队提出的特征自动编码器方法,用于将预训练视觉模型的高维特征压缩到适合图像生成的低维空间。它解决了"理解模型需要高维度、生成模型需要低维度"这一长期困扰AI图像生成领域的矛盾。
Q2:为什么只需要一个注意力层就够了?
A:因为预训练理解模型的高维度主要是为了处理掩码预测任务中的多种可能性,而图像生成时输入的是完整图像,不需要这些冗余信息。单注意力层能够识别并去除补丁间的全局冗余,同时保留真正有用的语义信息。
Q3:FAE生成的图像质量如何?
A:FAE在ImageNet基准测试上取得了接近最佳的FID分数(使用分类器引导时为1.29,不使用时为1.48),而且学习速度非常快,仅80个epoch就能达到竞争方法需要数百epoch才能达到的水平。
来源:至顶AI实验室
好文章,需要你的鼓励


据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
当超级计算机被压缩进一个比书本还小的盒子里,这画面有多炸裂?想象一下,你桌面上摆着的不是什么花瓶摆件,而是一台能跑200B参数AI推理的"超算怪兽"——这就是我们今天要聊的主角:华硕Ascent GX10。

不用再训练AI模型,香港科技大学团队发明“智能管家“,让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。


韩国KAIST让SVG动画脱胎换骨:AI如何破解矢量图形的“语义迷宫“让静态图标活起来
韩国KAIST开发的Vector Prism系统通过多视角观察和统计推理,解决了AI无法理解SVG图形语义结构的难题。该系统能将用户的自然语言描述自动转换为精美的矢量动画,生成的动画文件比传统视频小54倍,在多项评估中超越顶级竞争对手,为数字创意产业带来重大突破。
2025
12/17
14:40
分享
点赞

苹果发现:只需一个注意力层,就能让AI图像生成既快又好
YouTube推出基于Gemini 3的创作者游戏制作工具
英伟达是唯一能负担免费提供AI模型的厂商
OpenAI发布新旗舰图像生成AI模型GPT Image 1.5
脑启发算法可大幅降低AI能耗
Mac办公桌升级必备配件指南:提升工作效率的最佳选择
PTC Windchill+ 助力 HOLON研发全球首批符合汽车行业标准的 L4 级电动汽车
航旅行业的AI“乘法效应”:迈向指数级进化
OpenAI推出GPT Image 1.5模型加速图像生成竞争
Zoom推出AI Companion 3.0智能体工作流程
ChatGPT成为互联网最受阻止的爬虫机器人
英伟达推出开源权重模型填补美国AI市场空白
