
中科大发布Live Avatar:AI数字人无限聊天不翻车 原创
你愿意和一个数字人视频通话吗?如果它的嘴型、表情跟说话的声音完美配合,宛如真人。而且这场对话可以持续几个小时甚至更久,这个数字人始终保持着同一张脸、同样的肤色,不会突然变脸或者出现诡异的色彩偏差。

2025年12月,中科大和阿里巴巴的研究团队,发布了一项名为Live Avatar的突破性技术。这项研究的核心成果是:他们成功让一个拥有140亿参数的大规模AI模型,实现了实时、无限时长的高清数字人视频生成。简单来说,就是让超级大脑也能实时说话,而且可以一直说下去,不会越说越糟糕。
为什么让数字人无限聊天这么难?
让AI生成的数字人持续说话,究竟难在哪里?
你可以把AI生成视频想象成一个特别挑剔的厨师在做饭。这位厨师(AI模型)需要一道菜一道菜地做(一帧一帧地生成画面),而且每道菜都要和前面的菜完美搭配(保持视觉连贯性)。问题来了:如果这位厨师要连续做几百道菜,甚至上千道菜呢?
第一个大麻烦是速度。目前最厉害的AI视频生成技术叫扩散模型,它的工作原理有点像用橡皮擦慢慢擦掉一幅画上的涂鸦。想象一下,一幅被完全涂花的画,AI需要一点一点地把杂乱的涂鸦擦掉,最终还原出清晰的图像。这个擦除过程需要反复进行很多次(通常几十次甚至上百次),每次都要让整个超大模型运算一遍。对于140亿参数的模型来说,这简直就像让一头大象跳芭蕾舞,虽然理论上可能,但实际操作起来慢得让人抓狂。结果就是,生成一秒钟的视频可能需要好几秒甚至更长时间,完全无法实时使用。
第二个大麻烦是记忆衰退。当数字人持续生成视频时,就像一个人在不断地复印复印件。你可能玩过这个游戏:把一张纸复印一份,再把复印件复印一份,如此反复。最后你会发现,字迹变得越来越模糊,甚至面目全非。AI生成长视频时也会出现类似的问题,数字人可能慢慢变脸,肤色可能渐渐偏移,整体画面质量也会逐渐下降。这种现象被研究者们称为身份漂移和色彩偏差。

在Live Avatar之前,市面上的技术要么只能做到实时但质量一般(因为用的是小模型),要么质量很好但速度太慢(因为用的是大模型)。就好比你只能选择骑自行车快速到达目的地,或者坐豪华轿车舒适地慢慢抵达,但没法既快又舒适。研究团队在论文中专门做了一个对比表格,展示了目前主流方法的局限:大多数方法无法同时实现"流式生成"、"实时速度"和"无限时长"三个目标,而Live Avatar是第一个全部做到的。
流水线式的聪明解法
那么,Live Avatar是怎么破解这个难题的呢?研究团队想出了一个特别巧妙的办法,叫做"时间步流水线并行"(Timestep-forcing Pipeline Parallelism,简称TPP)。
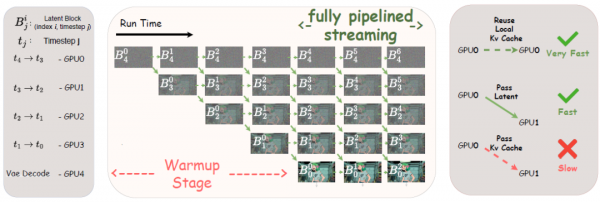
还记得我们说过,扩散模型生成图像就像擦除涂鸦吗?通常情况下,这个擦除过程是串行的,必须先擦第一遍,等擦完了才能开始擦第二遍,以此类推。这就像一个人在流水线上独自完成所有工序,效率自然很低。
Live Avatar的做法是:请来一群帮手,让每个人只负责一道工序。具体来说,他们用了5块高性能显卡(H800 GPU),每块显卡只负责擦除过程中的一个特定步骤。比如说,如果整个擦除过程需要4步,那么第一块显卡只做第一步(把涂鸦从最乱擦到稍微清晰一点),第二块显卡只做第二步(继续擦得更清晰),以此类推。最后一块显卡负责把完成的画面解码成真正的视频画面。
这样一来,当第一块显卡处理完一帧画面的第一步,它就可以把半成品传递给第二块显卡,然后立刻开始处理下一帧画面的第一步。与此同时,第二块显卡在处理第一帧的第二步,第三块显卡可能在处理更早一帧的第三步……就像真正的工厂流水线一样,每块显卡都在不停地忙碌,没有人需要等待。
这个方法有一个特别关键的细节:每块显卡都有自己的"记忆本"(KV缓存),记录着它处理过的历史信息。而且,每块显卡的记忆本只记录同样"擦除程度"的信息。这听起来有点奇怪,为什么要这样设计呢?
研究团队专门做了实验来回答这个问题。他们发现,让AI看着"同样模糊程度"的历史信息来处理当前画面,效果比看着"完全清晰"的历史信息要好。这可能是因为AI在训练时就是这样学习的,它习惯了在特定的"模糊度"下工作,突然给它太清晰的参考反而会让它困惑。就好比一个习惯戴眼镜看谱的钢琴家,你突然给他换成高清大屏幕显示,他反而可能弹错音。
通过这套流水线系统,Live Avatar在5块显卡上实现了每秒20帧的生成速度,这意味着它可以实时生成流畅的视频,你说话的同时,数字人就在同步"说话"。更重要的是,这种并行方式几乎不需要显卡之间传输太多数据(只传递半成品画面,不传递记忆本),通信开销非常小,效率极高。
让数字人记住自己长什么样
解决了速度问题,还有一个更棘手的挑战:如何让数字人在长时间对话中保持一致的外貌?
想象你正在画一幅连环画,每一格都要画同一个人物。如果你画了几百格甚至几千格,很可能画着画着就跑偏了,脸型变了一点,发色深了一点,背景色调也不太对了。AI生成长视频时也会遇到同样的问题,研究者称之为"推理模式漂移"和"分布漂移"。
Live Avatar提出了一套叫做"滚动锚点帧机制"(Rolling Sink Frame Mechanism,简称RSFM)的解决方案。这个名字同样很学术,但背后的思想非常直观。
核心想法是:给AI一张"标准照",让它在整个生成过程中不断参考这张照片,确保画出来的人物始终像照片上的样子。但这里有两个精妙的设计。

第一个设计叫"自适应注意力锚点"(Adaptive Attention Sink,简称AAS)。一开始,AI会参考用户提供的原始参考图片。但是,当AI生成了第一帧视频画面后,系统会用这第一帧画面来替换原始参考图片。为什么要这样做呢?因为AI生成的画面和原始照片在风格上可能有微妙的差异。如果一直参考原始照片,这种差异会持续存在并慢慢累积。但如果参考的是AI自己生成的第一帧,后续所有画面都会和第一帧保持一致,整体风格也就统一了。这就像一个乐队在演奏时,指挥不是按照乐谱的节拍走,而是跟着乐队实际演奏的节奏来调整,这样虽然可能和原谱有一点点出入,但整个演奏会非常和谐统一。
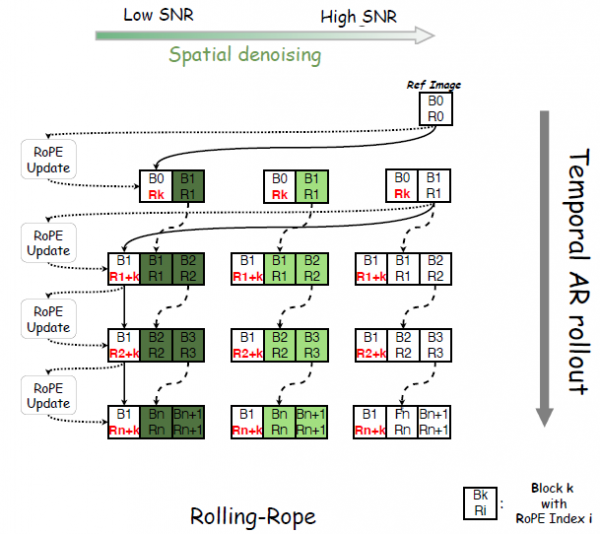
第二个设计叫"滚动位置编码"(Rolling RoPE)。这涉及到AI如何理解"时间"的问题。AI在处理视频时,需要知道每一帧画面在时间轴上的位置,这一帧是第1帧还是第1000帧?位置编码就是告诉AI这个信息的方式。问题是,AI在训练时只见过几分钟长度的视频,它的"时间尺度"是有限的。如果你让它处理一个几小时长的视频,那些时间位置数字会变得巨大,超出AI的认知范围。
滚动位置编码的解决方案很聪明:它不让锚点帧的位置数字固定不变,而是让它随着视频进度滚动。具体来说,锚点帧的位置总是被设定为当前帧位置加上一个固定偏移。这样一来,无论视频生成到第100帧还是第10000帧,锚点帧和当前帧之间的"相对距离"始终保持在一个合理的范围内,就像一个永远走在你前面固定距离的向导,无论你走多远,他都在那个位置等你。
研究团队还在训练阶段引入了一个叫历史污染(History Corrupt)的技术。这听起来有点反直觉,为什么要污染历史信息呢?原因是这样的:在实际使用时,AI参考的历史帧都是它自己生成的,难免有一些小瑕疵;但在训练时,如果给AI参考的都是完美的真实视频帧,AI就会变得娇气,一遇到有瑕疵的历史帧就不知道该怎么办了。通过在训练时故意给历史帧加一些噪声,AI学会了在"不完美"的条件下依然能做出好的判断,就像一个在嘈杂环境中练习过的歌手,到了正式演出时反而更稳定。
两阶段训练:先打基础,再精雕细琢
Live Avatar的训练过程分为两个阶段,就像培养一个技能一样,先学基础动作,再学高级技巧。
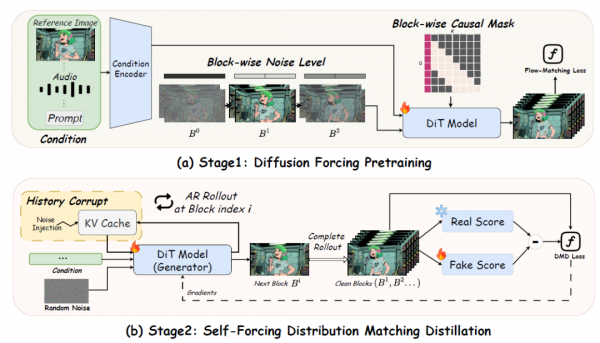
第一阶段叫扩散强迫预训练(Diffusion Forcing Pretraining)。在这个阶段,研究团队教AI学会一个关键能力:逐块生成视频。他们把视频分成一小块一小块的(每块包含3帧画面),让AI学会一次只关注一块,同时参考前面已经生成的块。这就像教一个人写连载小说,先学会写好每一章,同时记住前面的剧情,保持故事连贯。
在这个阶段,研究团队使用了一种特殊的"因果遮罩"策略。简单来说,就是告诉AI:"你只能看到过去发生的事情,不能偷看未来。"每一块画面在生成时,只能参考它前面的块,不能参考后面的块。这确保了AI能够真正做到"边走边生成",而不是必须等整个视频都规划好才能开始。
第二阶段叫自强迫分布匹配蒸馏(Self-Forcing Distribution Matching Distillation)。核心思想是:让AI学会偷懒,用更少的步骤完成同样质量的工作。
还记得我们说过,扩散模型生成图像需要反复"擦除涂鸦"很多次吗?在第一阶段训练完后,AI还是需要很多步骤才能生成高质量的画面。第二阶段的目标就是把这个步骤数大幅压缩,从几十步压缩到只要4步。
这种压缩不是简单的加速,而是一种知识转移,学术上叫蒸馏。想象一下,有一个经验丰富的老师傅(原始的多步模型),做一道菜需要慢工出细活,走很多步骤。现在要训练一个学徒(蒸馏后的少步模型),让他用更少的步骤做出同样好吃的菜。方法是:让学徒先尝试做菜,然后让老师傅品尝评价,告诉学徒哪里做得不够好。学徒根据反馈调整,反复练习,最终学会了用更简洁的方法达到同样的效果。
研究团队发现,这种蒸馏过程不仅加快了速度,还意外地提升了画面质量。这个发现和之前一些研究的结论一致,蒸馏过程中使用的"分布匹配"损失函数,某种程度上起到了类似"强化学习"的作用,能够优化模型的美学表现和整体质量。就好比学徒在学习老师傅技艺的过程中,居然发展出了一些老师傅都没有的新技巧。
真实效果如何?
说了这么多技术细节,Live Avatar的实际表现到底怎么样呢?研究团队做了大量的实验来验证他们的系统。
首先是速度测试。在5块H800显卡上,Live Avatar实现了每秒20帧的端到端生成速度,这意味着它可以流畅地实时生成视频。作为对比,其他使用类似规模模型的方法,速度通常只有每秒0.16到0.26帧,比Live Avatar慢了将近100倍。有一些方法确实能达到实时速度(比如Ditto方法能达到每秒21.8帧),但它们使用的模型规模只有Live Avatar的七十分之一(2亿参数对比140亿参数),画面质量自然也有差距。

关于画面质量,研究团队使用了多个标准指标来评估,包括美学得分(ASE)、图像质量(IQA)、唇形同步度(Sync-C和Sync-D)以及身份一致性(Dino-S)。在短视频测试中,Live Avatar的各项指标都达到了竞争力水平,与使用相同基础模型但速度慢100倍的方法相当甚至更好。
更令人印象深刻的是长视频测试。研究团队测试了7分钟长度的视频生成,发现Live Avatar在所有指标上都大幅领先竞争对手。其他方法在长时间生成时普遍出现明显的画质下降,而Live Avatar的画面质量始终保持稳定。论文中的对比图清楚地展示了这一点:在生成400秒视频后,其他方法的数字人或者脸型变了,或者色调偏了,或者细节模糊了;而Live Avatar生成的数字人依然保持着和开始时一样的清晰面貌。
研究团队甚至做了一个极限测试:让系统连续生成10000秒(将近3小时)的视频。要知道,他们的模型在训练时只见过5秒钟长度的视频片段。按照常理,让模型处理比训练时长几千倍的内容,肯定会"崩溃"。但实验结果显示,无论是在10秒、100秒、1000秒还是10000秒的时间点上采样,视频的画质指标几乎没有变化。这证明了滚动锚点帧机制的强大有效性。
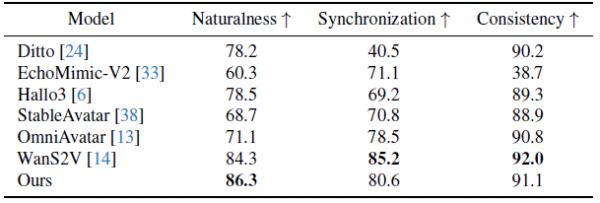
除了客观指标,研究团队还进行了主观评测。他们邀请了20位参与者,对各种方法生成的视频进行盲评,从"自然度"、"同步性"和"一致性"三个维度打分。结果显示,虽然有些方法在某些客观指标上表现更好(比如OmniAvatar在唇形同步度指标上得分很高),但人类评审反而给它的打分较低。原因是这些方法为了优化客观指标,让数字人的嘴巴动作变得过于夸张,反而显得不自然。而Live Avatar在三个维度上的人类评分都名列前茅,这说明它确实做到了让数字人看起来自然、同步、一致。
每个技术组件的价值
为了证明每个技术组件都是必要的,研究团队还做了详细的消融实验,也就是把各个组件一个一个去掉,看看效果会变差多少。
关于流水线并行(TPP),如果去掉这个设计,速度会从每秒20帧降到每秒4帧,减慢了5倍。尝试用传统的多GPU并行方式(序列并行)来代替,也只能达到每秒5帧,远不如TPP高效。这证明了TPP不只是一个简单的工程优化,而是一个真正突破性的系统设计。
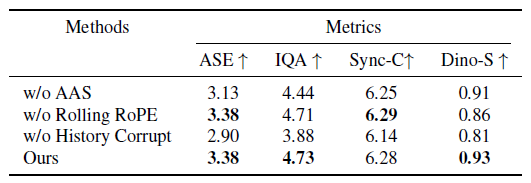
关于长视频生成的各个组件,去掉自适应注意力锚点后,美学得分从3.38降到3.13,图像质量从4.73降到4.44;去掉滚动位置编码后,身份一致性分数从0.93降到0.86;去掉历史污染机制后,美学得分更是暴跌到2.90,图像质量降到3.88。这些数据清楚地表明,每个组件都在发挥重要作用,缺一不可。
研究团队还专门对比了"同步骤记忆"和"清晰记忆"两种策略。所谓同步骤记忆,就是让AI在处理第N步去噪时,参考历史帧的第N步中间结果;清晰记忆则是让AI始终参考历史帧的最终清晰版本。实验结果令人意外,同步骤记忆在所有指标上都优于清晰记忆,而且还能支持流水线并行(因为不需要等待历史帧完全处理完)。这个发现对于理解扩散模型的工作原理很有价值。
这项技术能用来做什么?
Live Avatar的应用场景非常广泛。最直接的应用是虚拟主播和数字人直播。想象一下,一个24小时不间断的新闻播报数字人,它可以持续工作几个小时,始终保持一致的形象和高质量的画面。又或者是在线教育场景中的虚拟教师,能够实时回答学生的问题,用自然的表情和口型进行讲解。
另一个重要应用是实时视频通话中的虚拟形象。你可以用自己的声音说话,但屏幕上显示的是一个定制的数字人形象,这在隐私保护、匿名交流等场景中很有价值。Live Avatar的实时性能意味着这种应用可以流畅地进行,不会有明显的延迟。
研究团队特意展示了Live Avatar的泛化能力,它不仅能处理真实人脸,还能驱动卡通角色、动画人物,甚至是拟人化的非人类对象。论文中展示的一个有趣例子是让一团火焰说话,火焰的形态随着音频节奏变化,仿佛真的在开口说话一样。这种创造性的应用展示了技术的灵活性和想象空间。
当然,研究团队也坦诚地指出了当前技术的局限性。虽然TPP大幅提升了帧率(每秒能生成多少帧),但"首帧延迟"(从收到音频到输出第一帧画面的时间)并没有明显改善,这在需要极低延迟的交互场景中可能是个问题。另外,系统对锚点帧机制的依赖很强,在一些复杂场景中可能影响长时间的时序一致性。团队表示,未来会继续研究如何降低延迟和进一步提升时序连贯性。
至顶AI实验室洞见
Live Avatar研究团队通过巧妙的流水线并行系统设计和滚动锚点帧机制算法创新,同时解决了速度和质量两个看似矛盾的问题。而且他们的方法具有很强的通用性,同样的思路可以应用到其他需要实时生成的AI任务中。
我们离真假难辨的数字人又近了一步。未来,你在视频通话中看到的人,可能是一个AI驱动的数字形象,而你完全无法分辨。这带来了便利,也带来了新的思考:我们应该如何应对这种技术带来的信任问题?如何防止技术被滥用于欺骗?研究团队在论文中也特别提到了伦理考量,表示他们的技术仅用于合法的远程呈现和交互应用,并建议在实际部署时采取访问控制和数字水印等措施。
科技的发展总是比我们想象的更快。而Live Avatar,正是这个加速进程中的一个重要节点。
Q&A
Q1:Live Avatar是什么?
A:Live Avatar是由阿里巴巴集团联合中国科学技术大学等高校研发的AI数字人视频生成技术,它能够根据音频实时生成高清数字人说话视频,而且可以无限时长地持续生成而不出现画质下降或"变脸"问题。
Q2:Live Avatar需要什么硬件才能运行?
A:论文中的实验使用了5块NVIDIA H800显卡才能达到每秒20帧的实时生成速度。这意味着目前它还是一个需要高端硬件支持的专业级技术,短期内可能主要用于企业级应用而非普通消费者设备。
Q3:这项技术会不会被用来制作"深度伪造"假视频?
A:这确实是一个值得关注的问题。研究团队在论文中专门讨论了伦理考量,强调技术仅用于合法用途,并建议采用访问控制和数字水印等措施来防止滥用。不过,任何强大技术都存在被误用的风险,社会需要在技术普及的同时建立相应的监管和检测机制。
来源:至顶AI实验室
好文章,需要你的鼓励


西班牙病毒如何将谷歌带到马拉加
33年后,贝尔纳多·金特罗决定寻找改变他人生的那个人——创造马拉加病毒的匿名程序员。这个相对无害的病毒激发了金特罗对网络安全的热情,促使他创立了VirusTotal公司,该公司于2012年被谷歌收购。这次收购将谷歌的欧洲网络安全中心带到了马拉加,使这座西班牙城市转变为科技中心。通过深入研究病毒代码和媒体寻人,金特罗最终发现病毒创造者是已故的安东尼奥·恩里克·阿斯托尔加。

多伦多大学发现:聊天机器人的“嘴巴“影响它们的智商
这项由多伦多大学领导的研究首次系统性地揭示了分词器选择对语言模型性能的重大影响。通过训练14个仅在分词器上有差异的相同模型,并使用包含5000个现实场景测试样本的基准测试,研究发现分词器的算法设计比词汇表大小更重要,字符级处理虽然效率较低但稳定性更强,而Unicode格式化是所有分词器的普遍弱点。这一发现将推动AI系统基础组件的优化发展。

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
人工智能安全公司Cyata发现LangChain核心库存在严重漏洞"LangGrinch",CVE编号为2025-68664,CVSS评分达9.3分。该漏洞可导致攻击者窃取敏感机密信息,甚至可能升级为远程代码执行。LangChain核心库下载量约8.47亿次,是AI智能体生态系统的基础组件。漏洞源于序列化和反序列化注入问题,可通过提示注入触发。目前补丁已发布,建议立即更新至1.2.5或0.3.81版本。

北大研究团队颠覆视频AI训练新方法:让机器像人类一样“预测下一帧“学习世界
北京大学研究团队提出NExT-Vid方法,首次将自回归下一帧预测引入视频AI预训练。通过创新的上下文隔离设计和流匹配解码器,让机器像人类一样预测视频下一帧来学习理解视频内容。该方法在四个标准数据集上全面超越现有生成式预训练方法,为视频推荐、智能监控、医疗诊断等应用提供了新的技术基础。
2025
12/26
14:04
分享
点赞

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
Mill如何与亚马逊和全食超市达成合作协议
TechCrunch创业大赛中的9家顶尖生物技术初创公司
2025年印度科技领域十大重要发展
中科大发布Live Avatar:AI数字人无限聊天不翻车
从软件定义汽车到AI驱动质控:Testin云测助力车机测试数智化价值落地
无需Linux即可运行自由开源软件
超越 SEO:AI 引擎优化如何改变在线可见性格局
新Mac必装应用:五款提升工作效率的神器推荐
DXC蒲公英计划:为神经多样性IT专业人士赋能
AMD Strix Halo与Nvidia DGX Spark:哪款AI工作站更胜一筹?
类人机器人投资热潮涌现但商业化仍需数十年
