
AGI-Next峰会全记录解读:Kimi、Qwen、智谱、腾讯同台,2026年有新范式是共识,中国引领AI概率最低预测2成 原创
2026年1月10日,清华大学基础模型北京市重点实验室发起的AGI-Next前沿峰会上,中国大模型领域最重要的四位技术领军人物少见地聚在了一起:智谱创始人兼首席科学家唐杰、月之暗面创始人杨植麟、阿里Qwen技术负责人林俊旸、腾讯首席AI科学家姚顺雨,以及香港科技大学杨强教授。

这场会议的时间节点比较特殊。两天前的1月8日,智谱刚刚在港交所敲钟上市,成为"全球大模型第一股",市值突破500亿港元;唐杰在上市当天的内部信中宣布将推出新一代模型GLM-5,并明确2026年智谱将聚焦全新模型架构、通用RL范式和模型自主进化三个方向。姚顺雨则是加入腾讯后首次公开亮相,这位27岁的前OpenAI研究员以远程连线方式参与讨论,现场大屏幕上被笑称有一张"巨大的脸"。林俊旸是阿里历史上最年轻的P10,他带领的通义千问团队开源模型衍生数量和下载量已位列全球第一。杨植麟则在不久前刚刚官宣了月之暗面新一轮5亿美元融资。
"中国公司成为全球最强AI公司的概率有多大"这个问题时,林俊旸给出的数字是20%。
会上各位顶尖专家,讲了很多真知灼见,这种场面太少了,给主办方点一个赞。不过,我也要说,中国AI届的对外表达还是也太少了(各种原因吧,有一些可能也是无奈),所以导致这次公开露面,大概只能从头讲起,所以感觉信息量其实还能给出的更多,但完全能理解。昨天已经相信大家已经都看过速记了,但是觉得还是可以有一个更显性的梳理,所以还是记录下(是二次消化,不能代表专家完整准确原意)。
1. "DeepSeek出来之后,Chat这一仗基本结束了"
唐杰教授给了一个直接的判断。

"2023年我们是第一个做出Chat的,当时第一个想法是赶紧把Chat扔在网上上线。"他回忆道,"结果八九月份十来个大模型都上来了,每一家用户都没有那么多。"
经过一年的观察,唐杰认为单纯做Chat已经不是在真正解决问题。他原本预判大模型会替代搜索,但现实是谷歌反而用AI把自己的搜索革命了。而2025年初DeepSeek的出现,在他看来彻底终结了Chat范式的竞争。
"可能对研究界、产业界,甚至对很多人都是'横空出世'。"唐杰说,"在DeepSeek这种范式下,Chat时代基本上算是解决了。我们做得再好,也许跟DeepSeek差不多,或许在上面再个性化一点、变成有情感的Chat。但总的来讲,这个范式基本到头了,剩下更多是工程和技术问题。"
这个判断促使智谱做出战略转向。团队内部争论了很多个晚上,最终决定把所有精力放在Coding和Agent上。2025年7月,智谱发布4.5版本,把Coding、Agentic、Reasoning能力整合在一起。
但真实世界的反馈很快给了他们一记重击。
用户拿着模型去编"植物大战僵尸",结果编不出来。"真实编程环境下有大量问题需要解决。"唐杰说。团队通过RLVR(可验证强化学习)配合编程环境作为反馈,才把效果提升上去。这个经历让他意识到:跑分是跑分,真正让能力进入主模型、在真实体感中让用户满意,是完全不同层面的挑战。
有意思的是,大洋彼岸几乎同时传出类似的判断。山姆·奥特曼在2025年初的博客中写道:"We are now confident we know how to build AGI as we have traditionally understood it. We believe that, in 2025, we may see the first AI agents 'join the workforce' and materially change the output of companies."(我们现在有信心知道如何构建传统意义上的AGI。我们相信2025年可能会看到第一批AI Agent"加入劳动力市场",实质性地改变公司的产出。)红杉资本在2025年5月的AI Ascent大会上也宣称,Coding已经达到了"screaming product-market fit"(尖叫级产品市场契合)。Chat的时代落幕,Agent的时代开启,这个共识正在跨越太平洋。
2. 前100个Token,Transformer和LSTM完全一样
杨植麟的演讲是全场最"硬核"的,从第一性原理出发,用一张被很多人忽略的图解释了为什么Transformer成为主流架构。
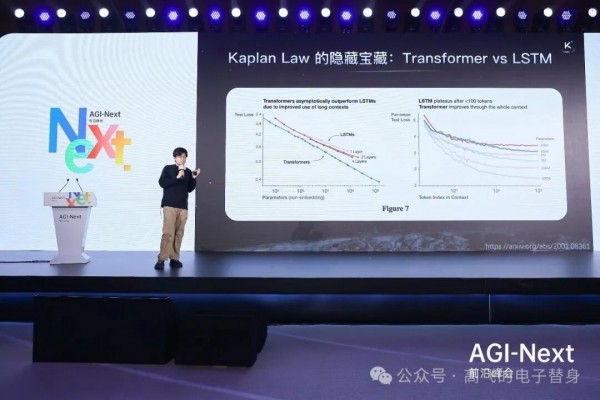
这个图示方法来自最早在提出Scaling Law的Kaplan论文中有所体现。横坐标是"序列中的第几个Token"(从第1个到第1000个),纵坐标是模型在该位置的预测损失(Loss,越低表示预测越准)。图上有两条线:蓝色是Transformer,红色是LSTM。
关键发现是:在前100个Token的范围内,这两条线几乎完全重叠。 当上下文很短时,Transformer和LSTM的表现一模一样,根本分不出谁更强。但随着横坐标向右延伸到1000个Token,蓝线开始明显下沉到红线下方。Transformer的优势不是一开始就有的,而是在上下文变长之后才逐渐显现。
为什么会这样?杨植麟用了一个类比:LSTM像一个只能往前看的人,必须一步步走完整条路,把所有信息压缩进一个固定大小的"记忆槽"里传递下去,走得越远,早期信息丢失越多。Transformer则像拥有一双能同时看清全局的眼睛,序列中任意两个位置都能直接建立联系,不受距离限制。
"这个特性在Agent时代变得极其重要。"杨植麟说,"很多Agent任务要求非常长的上下文。比如你想从零开发一个操作系统,本质上是搜索问题,需要在几十万Token的超长上下文中保持连贯的理解和规划。如果用LSTM,Loss曲线在100个Token之后就'躺平'了,根本无法胜任;而Transformer的曲线可以持续下降,Context越长、优势越大。"
基于这个理解,Kimi团队在2025年沿着两个方向做技术演进:提升Token效率,以及扩展长上下文能力。
3. "世界上最美的Loss曲线"
杨植麟展示的第二个核心技术是Muon优化器。
什么是优化器?可以理解为训练模型时的"调参师傅",决定每一步参数往哪个方向调、调多少。传统的Adam优化器用了十年,只看一阶信息(梯度方向);Muon由Keller Jordan在2024年提出,同时考虑二阶信息(梯度如何变化),能让模型学得更高效。Kimi团队在此基础上做了工程改进,实测Token效率提升2倍,等价于用同样的数据训出别人两倍Token的效果。
但原版Muon有个大问题:训练不稳定,Loss曲线容易"炸"。杨植麟展示了一张图,横坐标是训练步数,纵坐标是最大Logit取值,呈爆炸式增长。"它是一个不健康的状态,反映在右边非常高的时候,训练就可能不收敛,Loss会爆炸。"
Kimi团队开发了MuonClip版本,核心是加入QK-clip技术。在Transformer的注意力计算中,Query和Key两个向量的点积(即注意力分数)如果数值爆炸,会导致训练崩溃。QK-clip通过动态限制这些数值的上限来解决问题。
"这张图是2025年见过最漂亮的东西,是世界上最美的东西。" 杨植麟指着屏幕说。那是Kimi K2的15.5万亿Token预训练中的Loss曲线,完全平稳下降,没有一个spike。"当你有一个优雅的方法,就可以得到一个优雅的结果。"
另一个突破是Kimi Linear架构。线性注意力机制一直未能成为主流,核心问题是长距离任务掉点。标准Transformer注意力计算量与序列长度的平方成正比(写100万字要算100万×100万次),而线性注意力可以将计算量降到与序列长度成正比(写100万字只算100万次)。但此前的线性注意力在Context变长之后,效果打不过全注意力。
Kimi Linear通过Delta Attention技术,让线性注意力在长程任务上甚至比全注意力更好。根据Moonshot技术报告,在100万Token上下文下,Kimi Linear相比MLA的解码速度提升约6倍;杨植麟演讲中提到的"6-10倍"可能是指不同配置或更长上下文下的表现。这项技术将用于训练K3模型。
演讲最后,杨植麟分享了一段他与Kimi的对话。他问:AGI可能威胁人类,你怎么看?
Kimi的回答是:"我仍然会选择继续开发,因为放弃这个开发就意味着放弃人类文明上限。"
4. To B和To C正在发生明显分化
姚顺雨从硅谷带回的观察是:To C和To B两个市场正在走向截然不同的命运。
"今天用ChatGPT和去年相比,感受差别不是太大。"他说,"但Coding夸张一点来讲,已经在重塑整个计算机行业做事的方式,人已经不再写代码,而是用英语和电脑交流。"
原因很简单:对To C用户来说,大部分人大部分时候不需要那么强的智能。ChatGPT写抽象代数和伽罗瓦理论的能力变强了,但普通用户感受不到,很多人把它当作搜索引擎的加强版。
但To B市场完全不同。智能越高代表生产力越高,企业愿意为此付出溢价。姚顺雨举了一个例子:美国很多程序员愿意花200美元/月用最强的模型,而不是用50美元的次强模型。"如果年薪是20万美元,每天要做10个任务,最强模型可能八九个做对了,差的做对五六个。问题是你不知道哪五六个是对的,需要花额外精力监控。"
这和硅谷的信息高度一致。a16z在2025年发布的报告中称AI编程是一个"万亿美元市场",Cursor在15个月内达到5亿美元ARR和近100亿美元估值,Google花24亿美元acqui-hire了Windsurf。但也有研究机构METR发现,AI编程工具对资深开发者的提速效果远没有宣传的那么夸张,甚至在某些复杂代码库场景下会拖慢进度。To B市场的狂热与冷静并存,这是一个正在高速变化中的赛道。
这导致了一个有趣的现象:在To C应用上,模型和产品紧密耦合,比如ChatGPT和豆包;但在To B领域,趋势相反,模型公司和应用公司正在形成分层协作的格局。
林俊旸对此表示认同,但他补充了另一个视角:"今天做通用Agent最有意思的事情就是长尾。头部问题挺容易解决的,真正的魅力在于:今天我一个用户,寻遍各处都找不到能帮我解这个问题的,但在那一刻AI能帮我解决。全世界任何一个角落,寻遍各处都找不到,但你却能帮我解决,这就是AI最大的魅力。"
他也坦言,模型公司解决长尾问题有天然优势:"遇到问题只要训一训模型,烧一烧卡,问题可能就解决了。"而且今天强化学习带来了一个重要变化:"修问题比以前容易了。以前修问题很难,现在有RL之后,很小的一个数据点,甚至都不需要标注,只要有Query,稍微训一训,合并起来也非常容易。"
林俊旸在演讲中详细介绍了千问2025年的技术进展。千问从2023年8月开始做开源,最初的1.8B小模型只是内部做实验用的。"我说这个模型在2023年几乎是一个不可用的状态,为什么要开源出去?"他的师弟告诉他:7B很消耗机器资源,很多硕士生和博士生没有机器资源做实验,如果1.8B开源出去,很多同学就有机会毕业了。
这个初心让千问走上了开源之路。如今阿里通义实验室的开源模型衍生数量和下载量已位列全球第一。
在多模态方面,林俊旸强调了一个反直觉的观察:今天很多模型比人看东西看得更明白。"比如我又近视又散光,基本上不太好使。但AI很有意思,很细节的东西它看得很清楚,但问它前后左右,居然分不出来。"这成了团队要解决的问题。
图像生成领域的进展让他感到兴奋。8月份生成的图"AI感还是非常重",但12月份的版本"已经接近离谱了,虽然没有那么美和好看,但已经接近真人了"。还有一些细节的进步:水花不再夸张,灯塔照片里的水"可以达到非常自然的状态"。
"但是除了生成以外,用户告诉我们才知道,编辑是更大的需求。"林俊旸说,"因为大家都需要P图,让自己变得更好看。"开源社区给了一个重要反馈:图像编辑时,被编辑的部分会偏移,不在原位。"对于很多搞PS的同学来说,这个东西要非常精确,你不能随便移动。"这成了2511版本的重点改进方向。
5. Agent长任务是下一个战场
唐杰展示了智谱开源的AutoGLM案例。
用户说"下周去长春玩,帮我总结景点、收藏到高德、查票价、订高铁票",这个9B参数的模型在后台执行数十步操作(官方称可完成超过50步的长任务),调用不同APP,最终把所有信息整理好。开源后三天就拿了一万多star。
但他也坦言挑战:Agent数据训多了会降低语言能力和推理能力。"怎么让超大规模Agent模型保持通用性,是新问题。"
更大的挑战在于冷启动。很多应用根本没有数据,全是code,AI需要从零开始摸索。智谱的解决方案是把API和GUI混合在一起:对AI友好的场景用API,对人友好的场景让AI模拟人做GUI操作。
姚顺雨从另一个角度看待Agent的价值。他认为,即使今天所有模型训练全部停止,只要把现有模型部署到世界上各种各样的公司,"已经能带来今天10倍或者100倍的收益,能对GDP产生5%-10%的影响"。
"今天它对GDP的影响还不到1%。" 他说。问题不在于模型不够强,而在于部署和教育。"会使用这些工具的人在替代那些不会使用工具的人,就像当年电脑出来,如果你学编程,跟你还在用计算尺的人,差距是巨大的。"
红杉资本在AI Ascent 2025上提出了一个更激进的概念:Agent Economy(Agent经济)。他们认为AI Agent不仅会传递信息,还将转移资源、执行交易、发展自己的经济关系。但OpenAI前研究副总裁Bob McGrew在离职后接受采访时给出了一个冷静的预判:Agent会被商品化,最终按算力成本定价,而不是按它替代的人类劳动价值定价。"Once the capability exists, some other startup can come in and compete that away."(一旦能力存在,其他创业公司就可以进来把溢价竞争掉。)这意味着Agent赛道可能不像想象中那么容易建立护城河。
6. 自主学习:已经在发生,只是不够石破天惊
圆桌讨论进入下半场时,话题转向了"自主学习"。这个词在硅谷大街小巷的咖啡馆里被热议,但每个人的定义都不一样。
姚顺雨给出了一个反直觉的判断:"这个事情其实已经在发生了。"
他举了两个例子:ChatGPT在用用户数据不断学习聊天风格,让人感觉到它在变好,这是不是一种自主学习?Claude已经写了Claude这个项目95%的代码,它在帮助自己变得更好,这是不是一种自主学习?
"我们当时2022、2023年在硅谷宣传这个工作的时候,第一页就写ASI最重要的点是自主学习。"姚顺雨说,"今天的AI系统本质上都有两部分,一是模型,二是怎么用这个模型的代码库。Claude在写自己的代码库,这已经是自主学习了。"
但他承认,目前外界感知不明显,是因为这些自主学习的例子还局限在特定场景下,没有让人感觉到非常大的威力。"这个事情更像是一个渐变,不是突变。"
这种"已在发生但不够石破天惊"的感知,和硅谷的公开讨论形成有趣的对照。山姆·奥特曼在博客中宣称"we are beginning to turn our aim beyond that, to superintelligence in the true sense of the word"(我们开始把目标转向真正意义上的超级智能),但MIT Technology Review的长篇调查文章却指出,奥特曼的预言"hinged less on today's capabilities than on a philosophical tomorrow"(更多依赖于哲学层面的明天,而非今天的能力)。
AGI的定义在不断滑动,每次模型变强,标准就被抬高。也许正如姚顺雨所说,这是一个渐变而非突变的过程,只是身在其中的人往往最后才意识到变化的量级。
不过,似乎现在业界基本都认同持续学习,在线学习,只是对于实现它的难点和时间表没有特别公开共识的信息。这个问题之前Andrej Kaparthy的播客中谈过(播客题目:我们不是在制造动物,只是召唤幽灵),推荐大家也去一读了。
林俊旸则担心另一个问题:主动性带来的安全风险。
"我非常担心安全问题,不是担心它今天讲一些不该说的话,最担心的是它做一些不该做的事情。" 他说,"比如主动产生一些想法,往会场里面扔一颗炸弹。就像培养小孩一样,我们要给它注入正确的方向。"
杨强从理论层面给出了另一个视角。他引用了睡眠研究的类比:人类每天晚上睡觉是在清理噪音,使得第二天准确率能持续提升。 "我建议大家看一本书叫《我们为什么睡觉》,UC Berkeley神经科学教授Matthew Walker写的。"他说,"如果你把不同的Agent串联起来,每一个都不能做到百分之百,N个之后能力是按指数下降的。人类的解决方法是睡觉。像这些理论的研究,孕育着一种新的计算模式。"
作为联邦学习领域的资深学者,杨强提出了一个独特的观察:工业界和学术界正在分化。
"一直以来学术界是一个观望者,工业界在领头往前疯跑。这是好事,就好像天体物理学刚开始的时候以观测为主,伽利略的望远镜,然后才出现牛顿。"他认为,后面一个阶段,当有了众多的稳定大模型,进入稳态的时候,学术界应该跟上来。
学术界要解决什么问题?杨强认为是工业界还没来得及解决的问题。"比如智能上界在哪里?给你一定的计算资源或能源资源,你能做到多好?我90年代初就做过一个实验,如果投入一定资源在记忆上,这个记忆能帮助推理多少?帮助会不会变成反向的——记得太多了,噪音反而干扰推理,有没有一个平衡点?"
他还提到了哥德尔不完备定理的启示:"大模型不能自证清白,必定有一些幻觉不可能消灭掉。" 你多少资源能换取多少幻觉的降低,这是有一个平衡点的,特别像经济学里风险和收益的平衡。
在应用层面,杨强看好通用大模型与各领域专用小模型协同共生的前景。"我越来越多看到,很多场景本地资源不足,但本地数据又有很多隐私和安全要求。通用型大模型和本地特殊性的小模型如何协作,会变得越来越重要。尤其是医疗、金融这样的场景。"
唐杰对2026年出现新范式充满信心,给出了两个理由:
一是学术界现在有卡了。2023-2024年,工业界有上万片算力卡,高校往往只有0片或1片,差距高达万倍。但到现在,很多高校已经配备充足算力,不少老师和硅谷学者纷纷投身大模型架构、持续学习等领域研究。尽管差距仍有10倍,但学术界已孵化出创新种子。
二是效率瓶颈已经出现。数据从2025年初的10TB涨到现在的30TB,未来可能扩展到100TB,但规模扩张带来的收益与高昂的计算成本不成正比。"如果能用更少的投入获得同样智能的提升,它就变成瓶颈式的突破。"
他提出了一个新概念:Intelligence Efficiency(智能效率),衡量的是用多少投入能获得智能的增量。
唐杰在演讲中系统梳理了他对AGI路径的思考。他认为,大模型的发展本质上是参考人脑认知的学习过程:从最早把世界长时知识全部背下来(就像小孩子先看书),到学会推理、学会数学题,再到更多的演绎和抽象。
唐杰借用卡尼曼的双系统理论来解释大模型的发展路径。"系统一完成了95%的任务,比如问'中国的首都是什么',你直接回答,因为背下来了。只有更复杂的推理问题,比如'我今天晚上要请一个四川的朋友大吃一顿,去哪吃',这才是系统二做的事情。"
对于未来的AI,他提出了几个现在大模型还没有、但人远远超过机器的能力:
多模态感统。"原生多模态模型和人的'感统'很像。人的感统是收集视觉信息、声音信息、触感信息,把它们统一感知。有些人大脑有问题,很多时候是感统失调。"
记忆能力和持续学习。"人有短期记忆、工作记忆、长期记忆。但我在想,一个人的长期记忆也并不代表知识。如果我的知识不能被记录在维基百科上,100年之后我也消亡了,对这个世界也没什么贡献,好像也不叫知识。 怎么把记忆系统从单个人的三级扩展到整个人类的第四级记录下来,是未来要给大模型构建的。"
反思和自我认知。"现在模型已经有一定的反思能力,但自我认知是很难的问题。很多人怀疑大模型有没有自我认知的能力,我是有一些支持的,我觉得这是有可能的,值得探索。"
他还提到了一个更本质的问题:Transformer的计算复杂度是O(N²),导致在增大Context时显存增大、推理效率降低。"原来我们探讨的时候没有说非得把模型弄小,越来越大是比较主流的方向。但最近我在反思,我们能不能找到更好的知识压缩方法,把知识压缩到更小的空间里?"
7. 20%的概率,与100%的坦诚
讨论最后,主持人问了一个问题:三到五年后,全球最领先的AI公司是中国团队的概率有多大?
姚顺雨相对乐观:"概率还挺高的。任何一个事情一旦被发现,在中国就能够很快复现,在很多局部做得更好,包括之前制造业、电动车这样的例子已经不断发生。"
但他也指出几个关键条件:光刻机能不能突破?能不能有更成熟的To B市场?有没有更多愿意做冒险事情的人?
"今天中国唯一要解决的问题是:我们到底能不能引领新的范式?" 他说,"其他所有事情,无论是商业、产业设计还是工程,我们某种程度上已经比美国做得更好。"
林俊旸给出的数字是20%。
"美国的Compute整体比我们大1-2个数量级,他们大量投入到下一代Research,我们光交付就已经占据了绝大部分。"他说,"创新是发生在有钱人手里,还是穷人手里,这是历史以来就有的问题。"
但他也看到希望:"穷则思变。我们这群穷人,是不是有可能在软硬结合上找到机会?今天大家的冒险精神开始变得更好,营商环境也在变好。"
这个20%的数字,放在2025年初DeepSeek震动硅谷的背景下看,或许过于保守了。当时DeepSeek R1以不到600万美元的训练成本,达到了OpenAI o1级别的推理能力,Nvidia单日市值蒸发近6000亿美元。Axios的报道用了一个刺眼的表述:"a joke of a budget"(一个笑话级别的预算)。微软CEO Satya Nadella在达沃斯论坛上公开表示:"The performance of DeepSeek's new models is impressive... We must take these developments from China seriously."(DeepSeek新模型的表现令人印象深刻……我们必须认真对待来自中国的这些进展。)
但红杉资本在2025年12月的展望中也提醒:2026年可能是"Year of Delays"(延迟之年),数据中心建设进度落后,AGI时间线被推迟。硅谷的共识正在从"AGI in 2027"滑向更谨慎的预期。在这个不确定性增加的窗口期,中国团队的机会或许比20%更大——前提是,真的有人愿意做冒险的事。
唐杰的总结是三点:
一群聪明人真的敢做冒险的事,90后、00后这一代是有的;
环境可能更好一些,让俊旸有更多时间做创新而不是交付;
我们能不能笨笨地坚持,"也许走到最后的就是我们"。
三个问答归纳全会:
Q1: 为什么说Chat时代已经结束?
唐杰认为,DeepSeek的出现基本解决了Chat范式下的核心问题。继续在Chat上做,最多做到个性化或情感化,收益有限。新的范式是让AI真正做事,从对话变成行动,从问答变成任务执行。智谱选择了Coding+Agent路线,把编程、推理、智能体能力整合在一起。但真实环境的反馈显示,跑分和用户体感是两回事,"植物大战僵尸"编不出来的教训让团队意识到,可验证强化学习配合真实环境反馈才是提升效果的关键。
Q2: 为什么Transformer能成为主流架构?
杨植麟用一张常被忽略的图回答了这个问题:在前100个Token范围内,Transformer和LSTM表现完全一样。Transformer的优势要等到上下文变长之后才能显现。LSTM像只能往前看的人,信息传递过程中不断丢失;Transformer像有一双看清全局的眼睛,任意位置都能直接建立联系。这个特性在Agent时代极其重要,因为复杂任务需要在超长上下文中保持连贯理解。Kimi的技术演进方向因此聚焦在Token效率和长上下文能力两个维度。
Q3: 中国AI公司成为全球最强的概率有多大?
林俊旸给出20%。核心差距在于:美国算力规模大1-2个数量级,且大量投入下一代Research,中国公司光交付就占据了绝大部分资源。更深层的问题是,一旦范式被证明可行,中国能快速追上甚至局部做得更好,但引领新范式的冒险精神和文化积淀还不够。姚顺雨相对乐观,但指出关键条件包括光刻机突破、成熟的To B市场、以及更多愿意做冒险事情的人。"今天中国唯一要解决的问题是:我们到底能不能引领新的范式?"
来源:至顶AI实验室
好文章,需要你的鼓励


iOS 18新增游戏应用正式上线,专为iPhone游戏体验而生
苹果在iOS 26中推出全新游戏应用,为iPhone、iPad和Mac用户提供个性化的游戏中心。该应用包含五个主要版块:主页展示最近游戏和推荐内容,Arcade专区提供超过200款无广告游戏,好友功能显示Game Center动态并支持游戏挑战,资料库可浏览已安装游戏并提供筛选选项,搜索功能支持按类别浏览。iOS 26.2版本还增加了游戏手柄导航支持,为游戏玩家提供更便捷的操作体验。

上海AI实验室让机器人“睁眼看世界“:用视觉身份提示技术让机械臂学会多角度观察
上海AI实验室联合团队开发RoboVIP系统,通过视觉身份提示技术解决机器人训练数据稀缺问题。该系统能生成多视角、时间连贯的机器人操作视频,利用夹爪状态信号精确识别交互物体,构建百万级视觉身份数据库。实验显示,RoboVIP显著提升机器人在复杂环境中的操作成功率,为机器人智能化发展提供重要技术突破。

Sleepbuds制造商Ozlo如何构建睡眠数据平台
睡眠耳塞制造商Ozlo正将其产品转型为数据平台。公司与冥想应用Calm建立合作,利用SDK分享睡眠传感器数据,帮助内容创作者了解用户真实反馈。Ozlo计划推出AI睡眠助手、耳鸣治疗订阅服务和床边音箱等新产品,并收购了脑电图技术公司Segotia,预计2027年推出脑电监测产品进军医疗设备市场,目前正在进行B轮融资。

英伟达团队突破AI训练瓶颈:让机器人同时学会多种技能不再“顾此失彼“
英伟达研究团队提出GDPO方法,解决AI多目标训练中的"奖励信号坍缩"问题。该方法通过分别评估各技能再综合考量,避免了传统GRPO方法简单相加导致的信息丢失。在工具调用、数学推理、代码编程三大场景测试中,GDPO均显著优于传统方法,准确率提升最高达6.3%,且训练过程更稳定。该技术已开源并支持主流AI框架。
2026
01/12
14:13
分享
点赞

iOS 18新增游戏应用正式上线,专为iPhone游戏体验而生
Sleepbuds制造商Ozlo如何构建睡眠数据平台
CES 2026推出AI伴侣机器人Emily
苹果2026年将发布四款新iPhone机型预览
AGI-Next峰会全记录解读:Kimi、Qwen、智谱、腾讯同台,2026年有新范式是共识,中国引领AI概率最低预测2成
Anthropic推出医疗健康功能助力患者理解病历记录
Google推出通用商务协议,推动智能体购物自动化
核电初创公司携小型反应堆回归,面临重大挑战
谷歌针对部分医疗查询移除AI概览功能
Motional采用AI优先策略重启无人驾驶出租车计划
新年存储升级:三星SSD优惠最高减免100美元
OpenAI与软银联手投资10亿美元,助力星门项目能源伙伴发展
