
微软研究院重磅发现,Data Efficacy:AI学习顺序和学习内容同等重要! 原创
我们教孩子学习时,都知道要循序渐进,先学简单的加减乘除,再学复杂的方程式。
意外的是,在训练AI模型时,这个基本常识竟然被忽略了。研究人员通常把所有训练数据随机打乱,就像把小学到大学的所有课本混在一起,随便挑一本让学生学习。
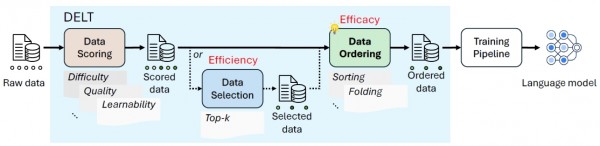
2025年6月,微软研究院提出DELT(Data Efficacy in LM Training)方法,通过优化训练数据使用顺序,让AI性能提升且无需额外计算成本。DELT方法包含数据评分、选择和排序三步骤,相关论文发表在Arxiv上。
微软的研究团队提出了一个全新的概念:“数据效力”(Data Efficacy)。以往的研究主要关注“数据效率”,也就是如何挑选最好的训练数据,就像在菜市场精挑细选最新鲜的食材。而数据效力则关注如何安排这些数据的使用顺序,就像大厨知道什么时候下什么料,才能让菜品达到最佳口感。
为了解决这个问题,研究团队开发了一套名为DELT的完整方法体系。这套方法就像一本详细的烹饪指南,包含三个核心步骤:首先给每份数据打分(就像给食材评级),然后选择使用哪些数据(就像决定今天用哪些食材),最后安排数据的使用顺序(就像制定烹饪的先后步骤)。
给数据打分:不只看质量,还要看时机
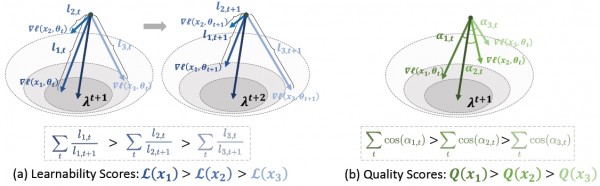
研究团队创新性地提出了LQS评分方法,这种方法不仅考虑数据的质量,还考虑数据的可学习性,也就是AI在什么阶段最适合学习这个数据。
可学习性的概念特别有趣。研究人员发现,同一份数据在AI学习的不同阶段会产生不同的效果。就像学钢琴时,简单的音阶练习在初学阶段很有用,但对已经有一定基础的学生来说就显得过于简单了。相反,复杂的乐曲对初学者来说太难,但对有基础的学生来说正好能提升技能。
LQS方法通过观察AI在学习过程中对每份数据的“反应”来评分。如果一份数据在训练初期让AI很吃力,但随着学习的进行逐渐变得容易消化,那么这份数据就获得高分。这种数据通常包含丰富的知识,虽然复杂但很有价值。相反,如果数据从始至终都让AI无所适从,可能就是噪音数据,应该被过滤掉。
质量评分则关注数据与AI学习目标的一致性。就像做菜时每种调料都应该让整道菜更美味,每份训练数据也应该让AI朝着正确的方向学习。研究团队通过观察AI在学习某个数据后,是否朝着预期的方向前进来判断数据质量。
数据排序:从乱炖到精心编排
解决了数据评分问题后,下一个挑战就是如何安排数据的使用顺序。传统方法要么完全随机打乱数据,要么简单地按难易程度排序。研究团队发现,这两种方法都有明显缺陷。
随机打乱就像做菜时随便抓调料,虽然省事但效果不佳。而简单排序虽然遵循了从易到难的原则,但会产生一个严重问题:AI学会新知识后,可能会忘记之前学过的内容。这就像学生专心练习高难度曲子时,可能会忘记基础的指法。
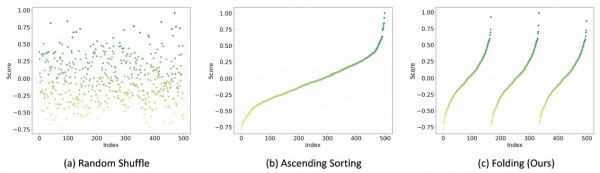
为了解决这个问题,研究团队提出了“折叠排序”方法。这种方法的核心思想是让AI在学习过程中反复接触不同难度的数据,而不是一次性从简单学到复杂。
具体来说,折叠排序会把所有数据按难度排序后,再巧妙地重新组织。比如原本的顺序是1、2、3、4、5、6(从易到难),折叠排序会变成1、4、2、5、3、6的顺序。这样AI在学习简单内容(1)后,会接触一些复杂内容(4),然后回到简单内容(2),再学习复杂内容(5),如此反复。
这种方法的好处是显而易见的。AI既能循序渐进地学习,又不会因为长时间接触同一难度的内容而产生偏食现象。
实验验证:数字说话的时刻
为了验证DELT方法的有效性,研究团队进行了大规模的实验。他们使用了多个不同规模的AI模型和数据集,就像在不同的厨房里,用不同的设备和食材来验证同一套烹饪方法。
实验结果令人振奋。在八个不同的测试任务中,使用DELT方法训练的AI模型平均性能提升了1.65%。这个数字听起来可能不大,但在AI领域,即使0.1%的提升都可能需要投入巨大的计算资源。更重要的是,这种提升是在不增加任何额外计算成本的情况下实现的。
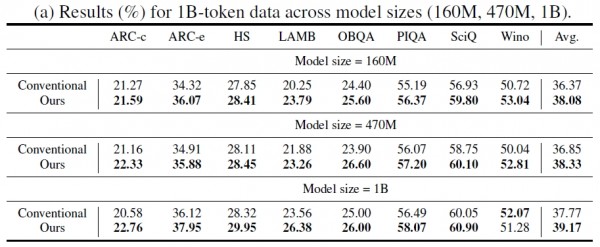
研究团队还发现,DELT方法在不同规模的模型上都有效果。无论是小型的1.6亿参数模型,还是大型的10亿参数模型,都能从这种方法中受益。这说明数据使用顺序的重要性是普遍存在的,不只适用于特定规模的AI系统。
特别值得一提的是,DELT方法还能与传统的数据筛选方法结合使用。也就是说,你既可以挑选最好的食材(数据效率),又可以安排最佳的烹饪顺序(数据效力),两者相得益彰,效果更佳。实验显示,当两种方法结合使用时,AI的性能提升甚至超过了单独使用任一方法的效果。
跨领域验证:不只是纸上谈兵
为了证明DELT方法的通用性,研究团队还在数学和编程两个专业领域进行了验证。

在数学领域,他们使用专门的数学数据集训练AI解决数学问题。结果显示,使用DELT方法训练的AI在数学推理任务上的表现明显更好。这说明即使在需要严密逻辑思维的数学领域,学习顺序的安排也能产生显著影响。
在编程领域的实验同样令人印象深刻。研究团队训练AI学习编写代码,结果发现按照DELT方法安排的学习顺序能让AI更好地掌握编程技能。这对于当前蓬勃发展的AI编程助手技术来说,具有重要的实用价值。
这些跨领域的验证结果说明,DELT方法揭示的可能是人工智能学习的一个基本规律。无论AI要学习什么技能,合理安排学习内容的顺序都能提升学习效果。
深入机制:为什么顺序如此重要
研究团队还深入分析了为什么数据使用顺序会如此重要。他们发现,现代AI模型通常只训练一轮(也就是每份数据只看一次,epoch=1),这与早期需要反复训练多轮的模型完全不同(epoch>1)。这种变化使得数据的使用顺序变得异常关键。
早期的AI模型就像反复研读同一本教科书的学生,即使第一遍读得不太好,后续的多次重复也能弥补。但现代AI模型更像是速读课程的学生,每本书只读一遍就要掌握全部内容,这就对阅读顺序提出了极高要求。
研究团队通过大量实验发现,如果AI在学习初期就接触过于复杂的内容,会影响后续的学习效果。相反,如果一直学习简单内容,又会错过学习复杂知识的最佳时机。DELT方法恰好在这两个极端之间找到了平衡点。
他们还发现,折叠排序方法能有效缓解AI的遗忘问题。传统的课程学习方法虽然遵循从易到难的原则,但AI在学习后期可能会忘记早期学过的简单知识。折叠排序通过在学习过程中适时回顾简单内容,帮助AI保持对全部知识的掌握。
实际应用:改变AI训练的游戏规则
DELT方法的意义远不止学术研究。在实际应用中,这种方法可能会改变整个AI行业的训练方式。
首先,这种方法几乎不需要额外的计算资源。对于那些计算预算有限的研究机构和公司来说,DELT提供了一种免费的性能提升方案。他们只需要重新安排现有数据的使用顺序,就能获得更好的AI模型。
其次,DELT方法特别适合当前的大规模AI训练趋势。随着训练数据规模越来越大,如何有效利用这些数据成为关键挑战。DELT提供了一种系统性的解决方案,不仅能提升性能,还能提高训练的稳定性。
对于AI应用开发者来说,DELT方法也带来了新的思路。他们可以根据具体应用场景的需求,设计个性化的数据排序策略。比如,开发医疗AI时可能需要特别注意数据的专业性递进;开发教育AI时可能需要更多考虑知识的逻辑顺序。
局限性与未来展望:科学研究的诚实态度
研究团队也坦诚地指出了当前方法的局限性。DELT方法目前主要在语言模型上进行了验证,在图像、音频等其他类型的AI模型上的效果还需要进一步研究。
另外,LQS评分方法需要一个高质量的小规模数据集来计算评分,这在某些应用场景下可能不容易获得。研究团队正在探索更简单、更通用的评分方法。
不过,这些局限性并不影响DELT方法的重要价值。研究团队已经在计划将方法扩展到更大规模的模型和更多类型的数据上。他们还希望开发更简单易用的工具,让更多研究者和开发者能够轻松使用这种方法。
至顶AI实验室洞见
模型训练中数据、算力、算法缺一不可。关于训练数据,研究人员逐渐总结出的一项重要经验是”Garbage in, Garbage out”,也就是“垃圾(数据)进(模型),垃圾(回答)出(模型)”。所以数据质量开始受到重视。
训练数据光有质量不行,还要讲究数据的排序方法。
正如人类教育中强调的因材施教、循序渐进,AI训练也需要精心设计的教学计划。DELT方法为我们提供了制定这种计划的科学工具,让AI能够更加高效地学习。
未来,数据效力可能会成为AI训练的一个重要研究方向。就像OpenAI研究员在谈论GPT4.5时强调数据效率,如何更好地组织和排序训练数据可能会吸引越来越多研究者的关注。
论文地址:
https://arxiv.org/abs/2506.21545
END
本文来自至顶AI实验室,一个专注于探索生成式AI前沿技术及其应用的实验室。致力于推动生成式AI在各个领域的创新与突破,挖掘其潜在的应用场景,为企业和个人提供切实可行的解决方案。
Q&A
Q1:什么是数据效力?它和数据效率有什么区别?
A:数据效力关注如何安排训练数据的使用顺序来提升AI性能,而数据效率关注如何选择最好的训练数据。打个比方,数据效率是挑选最好的食材,数据效力是安排最佳的烹饪顺序。两者互补,都很重要。
Q2:DELT方法会不会增加AI训练的成本?
A:不会。DELT方法只是重新安排现有数据的使用顺序,不需要额外的计算资源或时间。这就像用同样的食材和烹饪时间,仅仅改变烹饪顺序就能做出更美味的菜,是一种免费的性能提升。
Q3:DELT范式如何提升语言模型训练效果?
A:DELT通过数据评分(Data Scoring)、数据选择(Data Selection)和数据排序(Data Ordering)优化训练数据组织。数据评分根据样本质量、难度等属性分配分数;数据选择基于分数筛选最优子集;数据排序则打破传统随机打乱方式,按分数重新组织数据顺序(如升序或降序)。这种方法在不增加数据规模或模型参数量的前提下,显著提升模型性能。
来源:至顶AI实验室
好文章,需要你的鼓励


Wonder Dynamics联合创始人加入2025年TechCrunch Disrupt AI舞台
TechCrunch Disrupt 2025将于10月27-29日在旧金山举行,汇聚超过10,000名科技和投资领袖。Wonder Dynamics联合创始人、现Autodesk公司成员Nikola Todorovic将登台演讲。作为视觉效果资深专家转型AI企业家,他与演员Tye Sheridan共同推出了Autodesk Flow Studio,这是一个突破性AI平台,能让创作者无缝地将3D角色融入真人场景。该平台使用云端工具自动化复杂的灯光、动画和合成流程,为电影制作人提供更快速、更便捷的高端视觉效果制作途径。

清华大学团队用AI“魔法师“重建3D世界:仅凭两张照片就能还原完整空间场景
清华大学团队开发出LangScene-X系统,仅需两张照片就能重建完整的3D语言场景。该系统通过TriMap视频扩散模型生成RGB图像、法线图和语义图,配合语言量化压缩器实现高效特征处理,最终构建可进行自然语言查询的三维空间。实验显示其准确率比现有方法提高10-30%,为VR/AR、机器人导航、智能搜索等应用提供了新的技术路径。

全球风投二季度复苏迹象显现,AI交易主导资本流向
全球风投市场二季度显现复苏迹象,退出价值达676亿美元,为经济放缓以来最高季度数据。尽管美国交易价值因缺少OpenAI大额融资而下降25%,但AI领域仍表现突出,Meta对Scale AI的143亿美元投资成为史上第二大风投交易。AI交易占2025年美国风投总额近三分之二。然而募资仍是最大挑战,上半年仅募得266亿美元,有望创十年新低。欧洲、亚太和拉美地区同样面临困境。

IntFold:IntelliGen AI突破蛋白质结构预测难题,可控制基础模型改写药物发现游戏规则
IntelliGen AI推出IntFold可控蛋白质结构预测模型,不仅达到AlphaFold 3同等精度,更具备独特的"可控性"特征。该系统能根据需求定制预测特定蛋白质状态,在药物结合亲和力预测等关键应用中表现突出。通过模块化适配器设计,IntFold可高效适应不同任务而无需重新训练,为精准医学和药物发现开辟了新路径。
2025
07/04
10:56
分享
点赞

Wonder Dynamics联合创始人加入2025年TechCrunch Disrupt AI舞台
全球风投二季度复苏迹象显现,AI交易主导资本流向
什么是Perplexity?这款AI聊天机器人全方位解读
英超联赛推出AI工具提升球迷体验
Lovable计划融资1.5亿美元,估值达20亿美元
调研了300家企业,ICONIQ 发布《开发者手册:2025年AI现状报告》,揭秘企业AI落地的全景路线
一套脚本跑遍全平台,Testin云测以前沿自动化测试服务赋能企业伙伴
微软研究院重磅发现,Data Efficacy:AI学习顺序和学习内容同等重要!
多智能体系统如何革新数据工作流程
微软推出业务级AI微调服务助力企业价值创造
CEO预言白领替代潮:白领零工经济时代来临
AI与E Ink技术也无法让触屏触控板成为好创意
