
北京大学研究团队突破模拟计算精度极限:让矩阵运算快过超级计算机千倍 原创
在数学的世界里,解方程组就像解开一个复杂的谜题。当你面对一堆相互关联的未知数时,传统计算机需要一步步地计算,就像一个人在黑暗中摸索着寻找出路。然而,北京大学的研究团队最近在《Nature Electronics》期刊上发表了一项突破性研究,他们开发出一种基于电阻式随机存取存储器(RRAM)的模拟计算系统,能够以前所未有的精度和速度解决矩阵方程问题。
从厨房配方到矩阵运算的奇妙类比
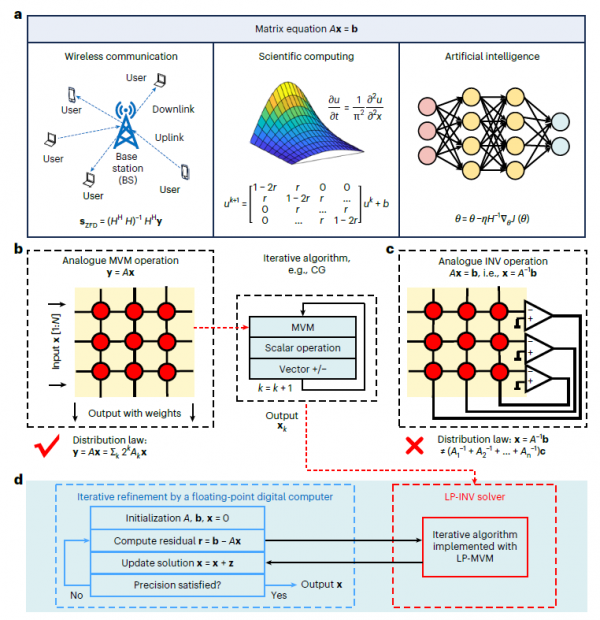
矩阵方程在我们生活中无处不在,虽然大多数人并不知道。当你用手机打电话时,基站需要处理多个用户同时发送的信号;当科学家模拟天气变化时,需要求解描述大气流动的方程;当人工智能学习新技能时,也需要解决复杂的优化问题。所有这些问题的核心都是解决形如Ax=b的矩阵方程,其中A是一个系数矩阵,x是我们要找的未知数,b是已知的结果。
传统数字计算机解决这类问题就像一位厨师按照食谱一步步做菜。首先切菜,然后炒制,接着调味,每个步骤都必须按顺序完成。当矩阵规模增大时,计算复杂度会呈立方级增长,一个100×100的矩阵需要的计算量是10×10矩阵的1000倍。这种"冯·诺伊曼瓶颈"让数据在处理器和内存之间来回奔跑,就像厨师不断地在厨房和储藏室之间往返取材料,效率自然大打折扣。
北京大学团队提出的解决方案则像是把整个厨房变成了一个智能烹饪系统。他们使用RRAM芯片构建了一个模拟计算电路,每个存储单元的电导值代表矩阵中的一个元素。当电流通过这个阵列时,根据欧姆定律和基尔霍夫定律,电路会自然地完成矩阵运算,就像水流过精心设计的管道系统会自动分流一样。更妙的是,通过添加运算放大器形成闭环反馈,整个系统可以在一步内求解矩阵逆运算,不需要反复迭代。
精度瓶颈的巧妙突破
模拟计算虽然速度快,但精度一直是个老大难问题。这就像用温度计测量体温,水银温度计虽然反应快,但读数可能不够精确。研究团队的RRAM器件只能可靠地编程到8个电导状态(相当于3比特精度),这对于许多实际应用来说远远不够。
为了解决这个问题,团队采用了一种类似于"分而治之"的策略。他们将高精度的矩阵分解成多个低精度的"切片",就像把一个大蛋糕切成多块来分别处理。具体来说,一个24位精度的矩阵被分解成多个3位的子矩阵,每个子矩阵有不同的权重。最重要的切片用于构建低精度求逆(LP-INV)电路,所有切片则用于高精度矩阵向量乘法(HP-MVM)运算。
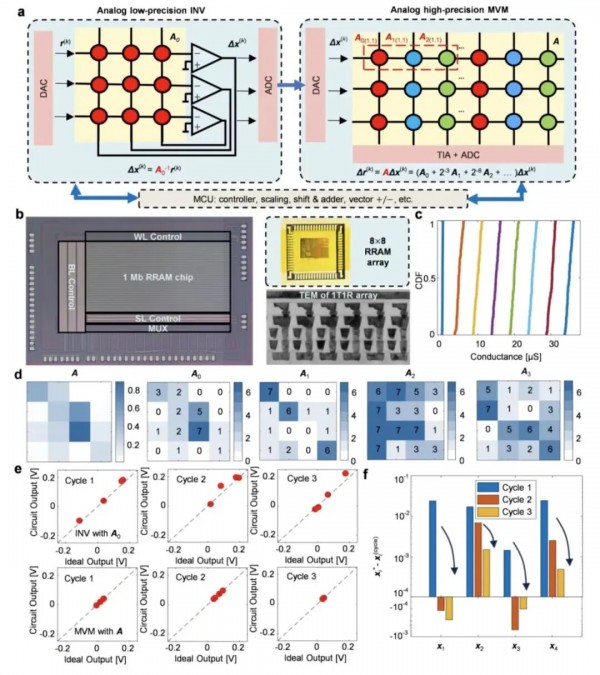
这个系统的工作流程就像一个精密的钟表机制。首先,LP-INV电路快速给出一个粗略的答案,虽然不够准确但方向正确。然后,HP-MVM通过位切片技术计算出精确的残差(实际结果与理想结果的差距)。接着,系统用这个残差来修正答案,如此反复几次,就能达到极高的精度。实验表明,对于一个4×4的矩阵,经过三次迭代后,每个元素的误差已经降到千分之一以下。这种方法的妙处在于,它充分利用了模拟计算的速度优势,同时通过迭代修正克服了精度不足的问题。
从小规模到大规模的扩展之道
解决小矩阵问题只是第一步,真正的挑战在于如何扩展到实际应用所需的大规模矩阵。研究团队开发的BlockAMC(块矩阵模拟计算)方法就像搭建积木一样巧妙。当面对一个大矩阵时,系统将其分割成多个小块,每个小块可以在不同的RRAM阵列上独立处理,最后再将结果组合起来。
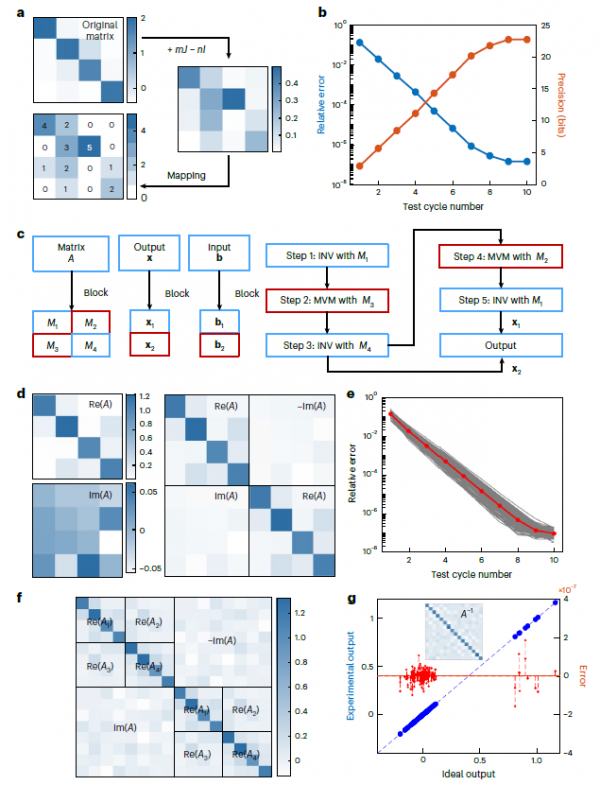
这种方法特别适合处理复数矩阵,这在无线通信等领域非常常见。复数矩阵可以展开成实部和虚部两个子矩阵,就像把一个立体拼图分解成多个平面来处理。实验中,团队成功解决了16×16的实数矩阵求逆问题,达到了24位定点精度(相当于32位浮点精度)。整个过程中,系统执行了16次HP-INV操作,每次处理单位矩阵的一个列向量。经过十个周期的迭代,逆矩阵元素的相对误差降到了千万分之一的量级。
更令人印象深刻的是,当矩阵规模从32×32扩展到128×128时,虽然需要使用多级BlockAMC,但系统的性能仍然保持优异。这就像建造摩天大楼,虽然楼层增加了,但通过合理的结构设计,整体稳定性依然可靠。计算复杂度分析显示,LP-INV操作数量按N^1.59增长,HP-MVM操作数量按N^2增长,都远低于传统数字处理器的N^3复杂度。
5G通信中的实战检验
为了验证这套系统的实用性,研究团队将其应用于大规模MIMO(多输入多输出)无线通信系统的信号检测。在5G和未来6G网络中,基站配备了大量天线来同时服务多个用户,这需要实时处理大规模矩阵运算。
实验设置就像一个微缩的通信场景。团队用一个16×4的MIMO系统传输北京大学校徽的二值化图像,每个用户天线传输8比特数据,相当于256-QAM调制中的一个符号点。信号经过带噪声的信道传输后,在基站使用零迫(ZF)检测方法恢复。这个过程的核心就是求解格拉姆矩阵H^H*H的逆,这正是数字处理器的性能瓶颈所在。
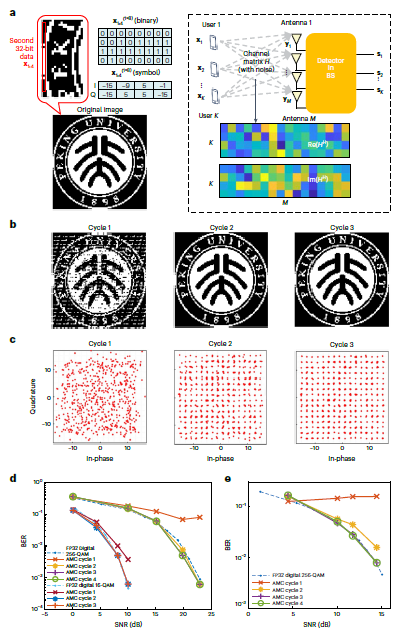
结果令人振奋。仅仅经过两个迭代周期,传输的图像就被完美重建,所有的256-QAM星座点都被正确检测,没有任何错误。与32位浮点数字处理器相比,HP-INV在两到三个周期内就达到了相同的误码率性能。对于更大规模的128×8 MIMO系统,通过两级BlockAMC处理16×16的复数矩阵,系统在三个周期内就达到了与数字处理器相同的性能。
这些结果不仅验证了系统的正确性,更重要的是展示了其在实际应用中的潜力。在信噪比测试中,无论是16-QAM还是256-QAM调制,HP-INV都能快速收敛到理想性能。特别是对于简单的16-QAM调制,误码率随信噪比稳定下降,表明较低的精度就足够了。
速度与能效的双重飞跃
研究团队对系统的瞬态响应进行了详细测量。对于4×4矩阵,模拟INV电路在120纳秒内就能收敛到稳定解,MVM操作的响应时间约为60纳秒。这个速度取决于运算放大器的增益带宽积和矩阵的最小特征值,而不是矩阵大小,这意味着时间复杂度实际上接近O(1)。
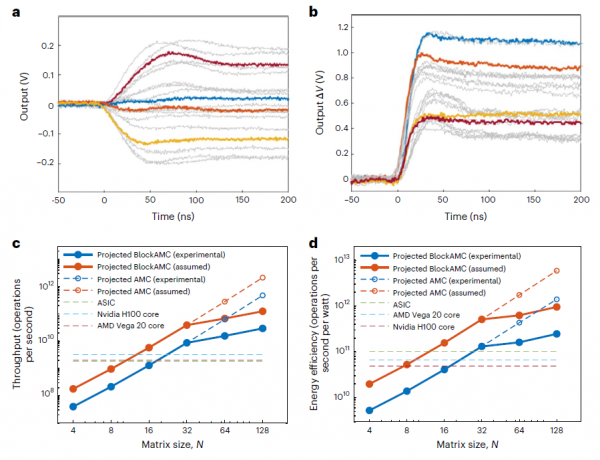
与最先进的数字处理器相比,这套系统展现出了压倒性的优势。研究团队将其与英伟达H100 GPU、AMD Vega 20 GPU以及专门设计用于128×8 MIMO信号处理的ASIC芯片进行了对比。在32×32的矩阵规模下,HP-INV的等效吞吐量已经超越了所有数字处理器。在128×128的规模下,即使使用了BlockAMC带来的额外开销,系统的吞吐量仍然比数字处理器高10倍,能效高3-5倍。
如果未来能够开发出响应时间更快的运算放大器(将INV响应时间降到20纳秒,MVM降到10纳秒),系统性能还能再提升4倍。在最理想的情况下,模拟计算可以实现比数字处理器高1000倍的吞吐量和近100倍的能效。这就像从步行升级到高铁,不仅速度快了,每公里的能耗反而更低。
研究团队还评估了导线电阻对系统性能的影响。通过仿真发现,即使在128×128的大规模阵列中,导线电阻(约1.73欧姆)对收敛速度的影响也很小,证明了系统的鲁棒性。此外,通过"确认"操作可以验证所有器件处于正确状态,如果发现缺陷可以用并行冗余阵列替代,进一步提高了系统的可靠性。
技术细节背后的创新
这项研究的成功离不开多项技术创新的支撑。首先是RRAM芯片的制造工艺。团队使用商用40纳米CMOS工艺平台,在M4和M5金属层之间嵌入了基于氧化钽(TaOx)的RRAM阵列。这种1T1R(一个晶体管配一个电阻)的结构确保了对每个存储单元的精确控制。通过写入验证方法,器件可以可靠地编程到8个电导状态(0.5-35微西门子),具有足够的读出裕度。
其次是巧妙的编码方案。最低的电导状态通过强复位获得,代表数值零。为了避免依赖强复位,还可以引入一个额外的高电导状态,使用差分编码方案覆盖-7到+7的范围。这种标准的AMC方法特别适合实值矩阵向量乘法。
整个系统的控制也经过精心设计。LP-INV电路板包含8×8 RRAM阵列、运算放大器、模拟开关、多路复用器、DAC和ADC。HP-MVM则是一个完全集成的芯片,包含1Mb RRAM阵列、跨阻放大器、ADC、模拟开关、多路复用器和寄存器。所有这些组件通过个人电脑协调工作,实现了从硬件到算法的完美配合。
至顶AI实验室洞见
这项研究为模拟计算开辟了新的道路。通过将低精度模拟运算与迭代优化相结合,团队成功突破了模拟计算长期存在的精度瓶颈。BlockAMC算法的引入使得系统能够处理实际应用所需的大规模矩阵。在大规模MIMO通信系统中的成功应用更是证明了这种方法的实用价值。随着技术的进一步发展,基于RRAM的模拟计算有望在科学计算、人工智能训练、信号处理等领域发挥越来越重要的作用,为后摩尔时代的计算架构提供新的可能。
https://www.nature.com/articles/s41928-025-01477-0
Q1:RRAM芯片在矩阵运算中是如何工作的?
A:RRAM芯片中的每个存储单元代表矩阵的一个元素,其电导值对应元素的数值。当电流通过阵列时,根据欧姆定律和基尔霍夫定律自然完成矩阵运算,就像水流过管道系统会自动分流。通过添加运算放大器形成闭环反馈,可以在一步内完成矩阵求逆,无需像传统计算机那样反复迭代计算。
Q2:北京大学团队的模拟计算系统相比传统数字处理器有多大优势?
A:在128×128矩阵规模下,该系统的吞吐量比英伟达H100 GPU等数字处理器高10倍,能效高3-5倍。如果采用更快的运算放大器,理论上可实现比数字处理器高1000倍的吞吐量和近100倍的能效。在大规模MIMO通信测试中,仅需2-3个迭代周期就能达到与32位浮点数字处理器相同的性能。
Q3:BlockAMC算法是如何让系统处理大规模矩阵的?
A:BlockAMC将大矩阵分割成多个小块,每个小块在不同的RRAM阵列上独立处理,最后组合结果。这就像搭积木,通过合理组合小模块来构建大系统。对于复数矩阵,可以展开成实部和虚部分别处理。实验中成功解决了16×16实数矩阵求逆,达到24位定点精度。
来源:至顶AI实验室
好文章,需要你的鼓励


北京大学研究团队突破模拟计算精度极限:让矩阵运算快过超级计算机千倍
北京大学研究团队开发出基于RRAM芯片的高精度模拟矩阵计算系统,通过将低精度模拟运算与迭代优化结合,突破了模拟计算的精度瓶颈。该系统在大规模MIMO通信测试中仅需2-3次迭代就达到数字处理器性能,吞吐量和能效分别提升10倍和3-5倍,为后摩尔时代计算架构提供了新方向。

普拉大学研究团队新突破:让AI读懂人话自动画流程图,比传统方法快一倍还准确
普拉大学研究团队开发的BPMN助手系统利用大语言模型技术,通过创新的JSON中间表示方法,实现了自然语言到标准BPMN流程图的自动转换。该系统不仅在生成速度上比传统XML方法快一倍,在流程编辑成功率上也有显著提升,为降低业务流程建模的技术门槛提供了有效解决方案。

Google大规模迁移内部工作负载至Arm架构,借助生成式AI工具
谷歌宣布已将约3万个生产软件包移植到Arm架构,计划全面转换以便在自研Axion芯片和x86处理器上运行工作负载。YouTube、Gmail和BigQuery等服务已在x86和Axion Arm CPU上运行。谷歌开发了名为CogniPort的AI工具协助迁移,成功率约30%。公司声称Axion服务器相比x86实例具有65%的性价比优势和60%的能效提升。

北大联合团队突破AI视频技术:一个模型同时看懂和生成视频的革命性进展
北京大学联合团队发布开源统一视频模型UniVid,首次实现AI同时理解和生成视频。该模型采用创新的温度模态对齐技术和金字塔反思机制,在权威测试中超越现有最佳系统,视频生成质量提升2.2%,问答准确率分别提升1.0%和3.3%。这项突破为视频AI应用开辟新前景。
2025
10/23
18:51
分享
点赞

北京大学研究团队突破模拟计算精度极限:让矩阵运算快过超级计算机千倍
Google大规模迁移内部工作负载至Arm架构,借助生成式AI工具
了解AI编程个性是进行氛围编程的最佳方式
AI服务的全新Shopify时刻已经到来
CIO在AI时代取得进步的关键步骤
智身科技机器狗助力曼彻斯特大学,勇夺IROS 2025四足机器人挑战赛冠军
人工智能企业加速营第七期开营:让优秀项目被看见,优秀项目有场景可验证
四十载伴NI行,日产中国40周年品牌之夜璀璨启幕
荣耀发布8大AI场景解决方案:以“全场景覆盖”推动终端智能普惠落地
栎新源与龙芯中科签署战略合作协议,国产超声波扫描显微镜全面应用龙芯底层产品
AI智能体的网络浏览器革命已拉开帷幕
英国监管机构将苹果和谷歌移动平台认定为战略市场地位
