
剪映要变天了?字节Vidi2自动根据素材剪辑视频 原创
当你拍摄了一段长达半小时的旅行视频,想从中找出"戴红帽子的小女孩追逐海鸥"的片段。如果是你自己来找,可能要反复拖动进度条几分钟;但如果有一位“视频侦探”,你只需要描述一下想找的画面,他不仅能告诉你这个片段在第几分几秒,还能在画面中精确框出那个小女孩的位置,这就是字节跳动最新发布的Vidi2模型所做的事情。
2025年11月24日,字节跳动智能创作部门的智能编辑团队,在arXiv上公开技术报告。这支团队一直致力于解决一个困扰普通用户的难题:如何让AI像专业剪辑师一样理解视频内容,并自动完成复杂的编辑工作。
为什么我们需要一个"视频侦探"?
视频已经成为我们在互联网上交流和表达创意的主要方式。无论是短视频平台上的有趣片段,还是长视频网站上的影视剧集,视频内容正在以爆炸式的速度增长。然而,制作一段高质量的视频对大多数人来说依然是一件令人头疼的事情,尤其是当你需要在手机上完成剪辑和编辑操作时。
假设你是一位婚礼摄影师,刚刚拍摄了三个小时的婚礼全程视频。新人希望你能剪出一个十分钟的精华片段,重点展示"新郎看到新娘出场时的表情"、"交换戒指的瞬间"以及"所有宾客举杯祝福的场景"。有时候可能需要一帧一帧地浏览三个小时的素材,用肉眼寻找这些特定的画面,然后手动标记时间点,再进行剪辑。整个过程可能需要花费你整整一天的时间。
字节跳动在2024年发布了第一代Vidi模型,它已经展现出了强大的时序理解能力。也就是说,当你告诉它"找出新郎第一次看到新娘的画面"时,它能够告诉你这个片段大概在视频的哪个时间段。但这还不够精确。如果画面中同时出现了新郎、伴郎和新娘的父亲,模型虽然找到了正确的时间段,却无法告诉你"新郎"具体在画面的哪个位置。
Vidi2的突破性进展正是解决了这个问题。它不仅能够找到正确的时间段,还能在每一帧画面中用一个精确的"框"标出你要找的那个人或物体。用我们的"侦探"比喻来说,第一代Vidi像是一位能告诉你"嫌疑人大约在下午三点出现在商场里"的侦探,而Vidi2则升级成了能够指着监控画面说"看,他就在这里,穿蓝色外套的那个人"的超级侦探。
Vidi2的三大"侦探技能"
要成为一名优秀的视频侦探,需要掌握哪些本领呢?Vidi2主要具备三种核心能力,它们就像侦探工具箱里的三件宝贝,分别用于不同的"破案"场景。
第一项技能叫做"时空定位",在论文中被称为STG(Spatio-Temporal Grounding)。这是Vidi2最引以为傲的独门绝技,也是它与其他模型拉开差距的关键所在。想象你在看一部武侠电影,想找出"主角第一次使出绝世剑法"的片段。时空定位不仅能告诉你这个精彩瞬间发生在第45分钟到第47分钟之间,还能在每一秒的画面中准确圈出主角的位置,即使画面中同时有十几个人在打斗。这就像侦探不仅知道案发时间,还能在人群照片中准确指出嫌疑人一样。
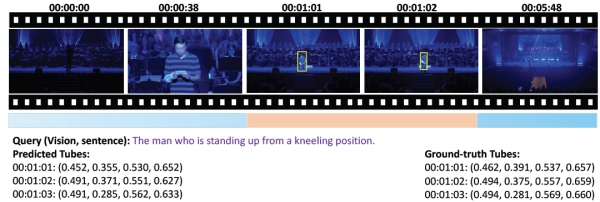
研究团队在论文中展示了一个具体的例子:在一段将近七分钟的视频中,用户输入的查询是"那个从跪姿站起来的男人"。这个场景发生在一个光线昏暗的环境中,画面里有好几个人。Vidi2不仅准确定位到这个动作发生在第1分01秒到第1分03秒之间,还在每一秒的画面中用精确的坐标框出了目标人物。模型预测的边界框坐标与人工标注的真实坐标相差无几。比如在第1分01秒的画面中,预测坐标是(0.452, 0.355, 0.530, 0.652),而真实坐标是(0.462, 0.391, 0.537, 0.657),误差非常小。
第二项技能是"时序检索",论文中称为TR(Temporal Retrieval)。如果说时空定位是精确到"画面中的哪个位置",那么时序检索就是专注于"视频中的哪个时间段"。这项技能在第一代Vidi中就已经表现出色,到了Vidi2则更加精进。时序检索特别适合处理那些只需要知道时间段、不需要精确到具体位置的查询。比如你想找出一段播客视频中"主持人讨论人工智能话题"的所有时间段,时序检索就能快速给你答案。
第三项技能是"视频问答",也就是Video QA。这是Vidi2相比前一代的重要升级。有了这项能力,Vidi2不再只是一个"搜索工具",而是变成了一个能够理解视频内容并回答问题的"智能助手"。你可以问它"视频里的主角最后去了哪里"、"那个红色的盒子里装的是什么"这样的问题,它会像一个看过整个视频的朋友一样给你答案。
值得一提的是,这三项技能并非孤立存在,而是相互配合、协同工作的。就像一位真正的侦探,既需要知道案发时间、案发地点,还需要能够分析案件来龙去脉一样。Vidi2把这三种能力整合在一个统一的模型架构中,用户只需要用自然语言描述自己的需求,模型就会自动调用合适的技能来完成任务。
"侦探"是如何炼成的:Vidi2的技术架构
了解了Vidi2能做什么之后,你可能会好奇:这个"超级侦探"到底是怎么训练出来的?让我用一个更通俗的比喻来解释。
想象你要培养一个能够同时理解文字、图像和声音的全能助手。传统的做法是分别训练三个专家:一个只懂文字的、一个只懂图像的、一个只懂声音的,然后让他们开会讨论。但Vidi2的做法不同,它从一开始就把文字、图像和声音放在一起学习,让模型天然地理解这三种信息之间的关联。
Vidi2的"大脑"建立在一个名为Gemma-3的大型语言模型之上。你可以把Gemma-3想象成一个已经阅读过海量书籍、具备强大理解能力的"学霸"。研究团队在这个学霸的基础上,额外教会了它"看"(理解图像和视频)和"听"(理解音频)的能力。整个模型的参数量是120亿,虽然这个数字听起来很大,但在当今的大模型时代,这实际上是一个相对精简的配置,意味着它可以在不那么昂贵的硬件上运行。
在处理视频时,Vidi2面临一个有趣的挑战:视频有长有短,短的可能只有几秒钟,长的可能超过一个小时。如何让同一个模型既能处理短视频又能处理长视频呢?研究团队设计了一种"自适应压缩"策略。你可以把这想象成一个智能的"摘要系统":对于短视频,它会仔细看每一帧;对于长视频,它会聪明地挑选关键帧,就像你快速翻阅一本厚书时会在重要章节多停留一会儿一样。
训练Vidi2的"食谱"也很讲究。首先,研究团队准备了大量的"合成数据",这些通过算法生成的训练样本,保证了数据的覆盖面和稳定性。但光有合成数据还不够,就像学厨艺不能只看菜谱,还需要真正下厨实践一样。团队还加入了大量真实视频数据,这对于提升模型在各种视频任务上的表现至关重要。特别是对于时空定位这个新技能,研究团队不仅利用了已有的图像级空间定位数据集来"举一反三",还专门标注了大量真实视频的时空定位数据,确保模型能够在实际场景中准确工作。
如何评判一个"侦探"的水平:全新的评估基准
在学术研究中,要证明一个新模型确实比之前的模型更强,就需要有一套公平、全面的"考试题目"。Vidi2的研究团队不仅开发了新模型,还精心设计了两套新的评估基准,这就像是为视频理解领域贡献了一套标准化的"高考试卷"。
第一套基准叫做VUE-STG,专门用于评估时空定位能力。这套基准有四个与众不同的特点,让它比以往的同类数据集更加贴近真实应用场景。
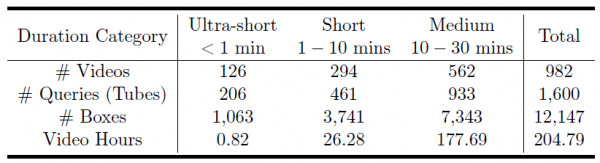
首先是视频长度的多样性,以前的学术数据集里,视频通常都很短,可能只有几秒到几十秒。但现实生活中,我们经常需要在十几分钟甚至半小时的长视频中寻找特定内容。VUE-STG包含的视频从十秒到三十分钟不等,总计982个视频、1600个查询,总时长超过204小时。这意味着模型不仅要能处理短视频,还要能在"大海捞针"般的长视频中准确定位。
其次是查询格式的优化,在标注这套数据集时,研究团队特别注意消除歧义。举个例子,如果原始描述是"一个球员被抬上救护车",这个描述其实有歧义,你想找的是"球员"还是"救护车"?团队会把这样的描述改写成更明确的形式,比如"正在被球员登上的那辆救护车"或"正在被抬上救护车的那位球员",这样模型和评估者都能清楚知道目标是什么。
第三个特点是标注质量,与许多依赖自动标注或众包标注的数据集不同,VUE-STG中的所有时间范围和边界框都是由人工精确标注的。虽然这种方式成本更高、速度更慢,但能确保评估结果的可靠性。
第四个特点是评估指标的设计,研究团队提出了一套完整的评估体系,包括时序指标(衡量时间段找得准不准)和时空指标(同时衡量时间和空间位置)。其中最重要的指标叫做vIoU(视频交并比),它综合考虑了时间和空间两个维度的准确性,作为模型排名的主要依据。
第二套基准叫做VUE-TR-V2,是对之前VUE-TR的升级版本,专门用于评估时序检索能力。升级后的数据集总视频时长从107小时增加到了311小时,增长了将近三倍。更重要的是,它包含了更多的长视频和超长视频(超过一小时的视频),让评估更加贴近真实场景。同时,查询的格式也更加接近普通用户的自然表达方式,而不是学术化的精确描述。
"侦探大比武":Vidi2与顶尖对手的较量
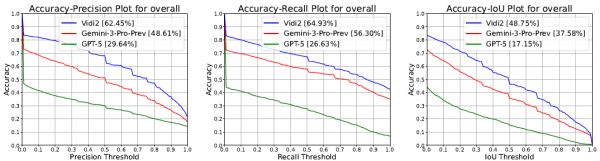
有了公平的考试题目,接下来就是真刀真枪的比拼了。研究团队让Vidi2与当前最强大的几个商业模型进行了正面较量,包括谷歌的Gemini 3 Pro(预览版)、OpenAI的GPT-5,以及阿里巴巴的Qwen3-VL-32B。
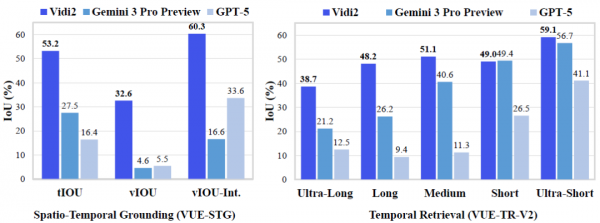
在时空定位任务上,Vidi2展现出了压倒性的优势。整体来看,Vidi2的时序交并比(tIoU)达到了53.19%,而Gemini 3 Pro只有27.50%,GPT-5更是只有16.40%。用通俗的话说,如果把找准时间段比作射箭,Vidi2有超过一半的箭能射中靶心附近,而竞争对手只有四分之一甚至更少。
在空间定位方面,差距更加悬殊。Vidi2的空间交并比(vIoU)是32.57%,而Gemini 3 Pro只有4.61%,GPT-5是5.47%。这意味着在"框出画面中具体位置"这件事上,Vidi2的准确度是竞争对手的六到七倍。这个差距之所以这么大,主要是因为时空定位本身就是一项全新的、难度极高的任务,而Vidi2是第一个专门为此优化的模型。
研究团队还做了更细致的分析,看看不同条件下模型的表现差异。一个有趣的发现是:随着视频长度增加,所有模型的表现都会下降,但Vidi2下降得最慢。在十到三十分钟的"中等长度"视频上,Vidi2的tIoU仍然保持在47.27%,而Gemini 3 Pro跌到21.13%,GPT-5更是只有4.10%。这说明Vidi2在处理长视频时的"耐力"远超竞争对手。
另一个值得关注的维度是目标物体的大小。当要找的物体在画面中占据的面积很小(不到10%)时,所有模型的表现都会变差,因为小目标本身就更难定位。但即使在这种困难条件下,Vidi2的vIoU仍有23.31%,是Gemini 3 Pro(2.33%)的十倍,是GPT-5(3.66%)的六倍多。
在时序检索任务上,Vidi2同样表现优异。在VUE-TR-V2基准上,Vidi2的整体IoU达到48.75%,超过Gemini 3 Pro的37.58%十多个百分点,更是大幅领先GPT-5的17.15%。特别是在超长视频(超过60分钟)这个最具挑战性的类别上,Vidi2的IoU是38.65%,而Gemini 3 Pro只有21.19%,GPT-5是12.49%。
为了确保比较的公平性,研究团队为每个竞争模型都精心设计了适合其特性的输入格式和提示语。比如GPT-5不支持直接输入视频,只能接受一系列图片帧,所以团队按照一定规则从视频中提取帧序列来输入。这些细节上的考量确保了评估结果的可信度。

那么在视频问答这个更通用的任务上表现如何呢?研究团队在三个公开的学术基准上进行了测试:LVBench、LongVideoBench和VideoMME。这三个基准都采用选择题的形式,便于客观评估。结果显示,Vidi2在LVBench上得分45.8%,在LongVideoBench上得分57.1%,在VideoMME上得分63.5%。这些成绩与同等规模的开源模型Qwen2.5-VL-7B相当(45.3%、54.7%、65.1%),虽然与顶尖的Gemini-2.5-Pro(78.7%、84.3%)还有差距,但考虑到Vidi2主要针对时序检索和时空定位进行优化,能在通用问答任务上达到这个水平已经很不错了。
"侦探"能帮我们做什么:实际应用场景
说了这么多技术细节,你可能最关心的还是:这个"视频侦探"到底能在现实生活中帮我们做什么?研究团队在论文中展示了三个非常实用的应用场景。

第一个应用是"自动生成精彩片段"。想象你拍了一段将近十分钟的宠物视频,想分享给朋友,但又不想让他们看完整段。有了Vidi2,你只需要告诉它"帮我找出视频中最精彩的片段,并给每个片段起个标题"。模型会自动扫描整个视频,挑选出几个亮点时刻,并生成诸如"这只兔子的晨间例程有点……与众不同"、"当你想安静,但朋友偏不让你消停"这样生动有趣的标题。论文中展示的例子是一段关于兔子的视频,Vidi2自动提取了三个精彩片段,每个片段都配有一个幽默且贴切的标题。
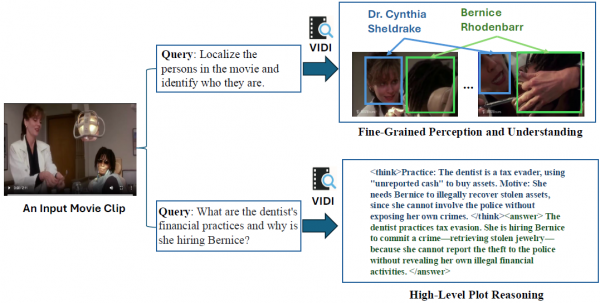
第二个应用是"剧情理解"。如果你是影视爱好者或视频编辑从业者,这个功能会特别有用。现代影视作品往往有复杂的人物关系和情节线索,即使是专业编辑人员,想要按照特定角色或特定情节来剪辑视频,也需要花费大量时间反复观看。Vidi2可以帮你"认人",识别出画面中的不同角色并追踪他们的位置。更厉害的是,它还能理解复杂的情节逻辑。论文中的例子是一部电影片段,用户问"那个牙医的财务操作是什么,她为什么要雇佣Bernice?"Vidi2不仅识别出画面中的两个角色(牙医Dr. Cynthia Sheldrake和Bernice Rhodenbarr),还推理出剧情要点:牙医是个逃税者,她需要雇佣Bernice来追回被偷的珠宝,但又不能报警,因为那样会暴露她自己的非法行为。
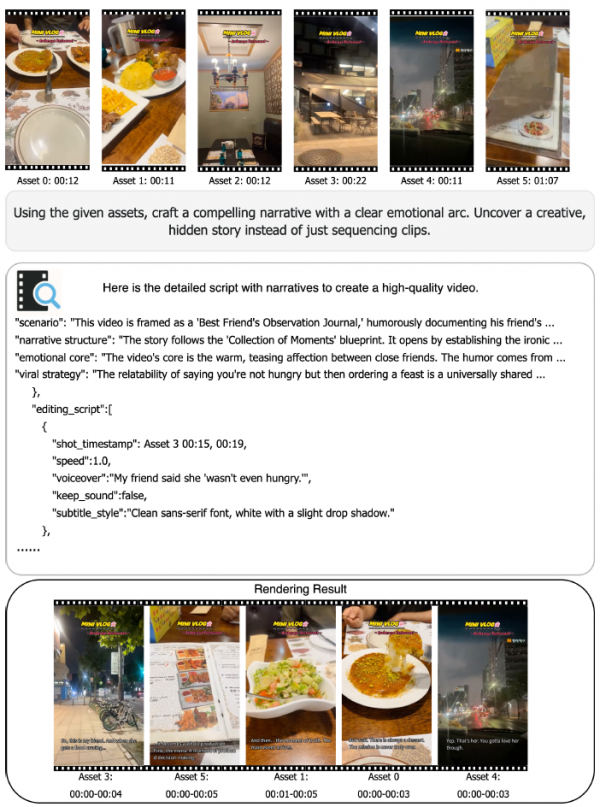
第三个应用是"基于故事线的视频创作"。这是一个更高级的应用,目标是让AI像专业剪辑师一样,根据叙事逻辑来组织多个视频素材。论文展示了一个例子:输入六段不同的美食视频片段,让模型"用这些素材创作一个有情感弧线的故事"。Vidi2会生成一份完整的剪辑脚本,包括场景设定("这个视频以'闺蜜观察日记'的形式呈现,幽默地记录朋友的日常")、叙事结构("故事遵循'瞬间集锦'的框架,先建立反差,再展现温情")、情感核心("视频的核心是闺蜜之间温暖又互相调侃的情感")以及具体的剪辑指令(哪个片段放在哪里、用什么速度、配什么旁白、用什么字幕样式)。最终渲染出来的成品视频包含了旁白、音乐、动画和转场效果,展现了模型自动化整个创意剪辑流程的潜力。
这三个应用场景,从简单到复杂,从个人用户到专业场景,展示了Vidi2的广泛适用性。对于普通用户来说,它可以让视频编辑变得像发微信一样简单,只需要说出你想要什么,AI就能帮你完成;对于专业人士来说,它可以大幅提升工作效率,让他们把更多精力放在创意构思而非繁琐的素材整理上。
至顶AI实验室洞见
Vidi2代表了视频AI领域的一个重要里程碑。它第一次真正实现了端到端的时空定位能力,让AI不仅能理解"什么时候发生了什么",还能精确指出"在画面的哪个位置"。这看似简单的进步,实际上打开了一扇通往智能视频编辑的大门。
回想一下,十年前我们可能从未想过,有一天可以对着手机说一句话就能搜索到想要的信息。而今天,语音助手已经成为我们日常生活的一部分。Vidi2的出现让我们有理由相信,不久的将来,我们可能只需要对着电脑说"帮我把这段视频里所有笑得最开心的镜头剪出来做成一个合集",AI就能自动完成所有工作。
虽然Vidi2在时空定位和时序检索上取得了领先优势,但在通用视频问答方面,它与顶尖的商业模型还有明显差距。说明要打造一个真正"全能"的视频AI助手,还有很长的路要走。同时论文里展示的应用场景虽然令人兴奋,但从学术演示到大规模商业落地之间,通常还需要经历大量的工程优化和产品打磨。
不过有一点是确定的:视频正在成为互联网上最主要的内容形式,而能够真正"理解"视频的AI,将会深刻改变我们创作、编辑和消费视频内容的方式。Vidi2让我们看到了这个未来的一角。对于普通用户来说,这意味着视频创作的门槛将进一步降低;对于专业人士来说,这意味着效率工具将变得更加强大;而对于整个行业来说,这预示着一场关于视频内容生产方式的深刻变革正在酝酿之中。
那么问题来了:当AI能够像你一样理解视频内容,甚至比你更快更准确地完成编辑工作时,人类创作者的价值将体现在哪里?或许,正是这个问题,才是Vidi2这类技术留给我们最值得思考的课题。
Q&A
Q1:Vidi2是什么?
A:Vidi2是字节跳动智能编辑团队开发的大型多模态视频理解模型,它能够根据文字描述在视频中精确定位特定时间段,并在画面中框出目标物体的位置。简单来说,它就像一个"视频侦探",你描述想找的内容,它就能帮你在茫茫视频中精准定位。
Q2:Vidi2和GPT-5、Gemini相比谁更强?
A:在时空定位和时序检索这两项专业任务上,Vidi2大幅超越GPT-5和Gemini 3 Pro,准确率是它们的数倍。但在通用视频问答方面,Vidi2与顶尖模型还有差距,因为它主要针对视频定位任务进行了专门优化。
Q3:普通人能用Vidi2做什么?
A:普通人可以用它自动提取长视频中的精彩片段、为片段生成标题,或者通过自然语言描述来快速定位视频中的特定画面。目前Vidi2还处于技术发布阶段,尚未以消费级产品形式向公众开放,但它预示了未来视频编辑工具的发展方向。
来源:至顶AI实验室
好文章,需要你的鼓励



突破性AI助手:Skywork-R1V4让机器像侦探一样“看图说话“还能上网搜证据
昆仑万维Skywork AI团队开发的Skywork-R1V4是一款突破性的多模态AI助手,能够像侦探一样主动分析图像、上网搜索信息并将两种能力无缝结合。该系统仅通过3万个高质量样本的监督学习就实现了卓越性能,在多项测试中超越了更大规模的商业模型,证明了精妙设计比单纯扩大规模更重要,为AI助手的实用化发展指明了高效路径。

Myriota推出HyperPulse 5G非地面网络IoT连接服务
太空物联网连接服务商Myriota宣布其HyperPulse连接平台正式商用,该平台结合公司5G非地面网络架构与从Viasat租赁的L波段容量。该平台采用波束跳跃技术,根据流量需求激活所需波束,优化电池供电物联网设备功耗。相比UltraLite服务,HyperPulse提供更低延迟和更高日数据传输量。服务将于12月15日在美国、墨西哥、巴西、澳大利亚和沙特正式上线。

香港科大最新突破:让AI看图像重建3D世界的速度飞起来了
香港科技大学研究团队开发出FlashVGGT技术,通过创新的"压缩代表"策略和分块递归推理机制,将3D重建速度提升10倍以上,能处理超过3000张图像的超长序列。该技术在保持重建质量的同时显著降低计算复杂度,为VR游戏、建筑测量、自动驾驶等领域提供更实用的3D重建解决方案。
2025
12/04
14:12
分享
点赞

威廉姆斯车队与Atlassian合作:打破传统赞助模式
美光科技放弃消费级存储品牌Crucial追逐AI商机
亚马逊希望通过免费赠送AI编程工具Kiro来抢占市场
ALM如何推动现代生产发展
剪映要变天了?字节Vidi2自动根据素材剪辑视频
HPE以虚拟化、安全与AI创新塑造混合云未来
Agentic AI军备竞赛升级!亚马逊云科技亮出“底牌”,定义下一条赛道
Myriota推出HyperPulse 5G非地面网络IoT连接服务
HPE与AMD扩大合作推进开放式机架级AI基础设施
爱立信与LotusFlare合作加速网络API技术普及
构建MCP服务器简单,但让它正常运行却困难重重
Linux 6.18发布:年度最后版本或成新长期支持版本
